

Regressionsanalyse er en af de mest eftertragtede metoder til statistisk forskning. Med det er det muligt at fastslå graden af indflydelse af uafhængige værdier på den afhængige variabel. Microsoft Excel-funktionaliteten har værktøjer beregnet til en lignende type analyse. Lad os analysere, at de repræsenterer sig selv og hvordan man bruger dem.
Tilslutning af en pakke med analyse
Men for at kunne bruge en funktion, der giver dig mulighed for at udføre en regressionsanalyse, skal du først og fremmest aktivere analysepakken. Først da de værktøjer, der er nødvendige for denne procedure, vises på eksilbåndet.
- Flyt ind i fanen "Fil".
- Gå til afsnittet "Parametre".
- Vinduet Excel parameters åbnes. Gå til underafdeling "Addstructure".
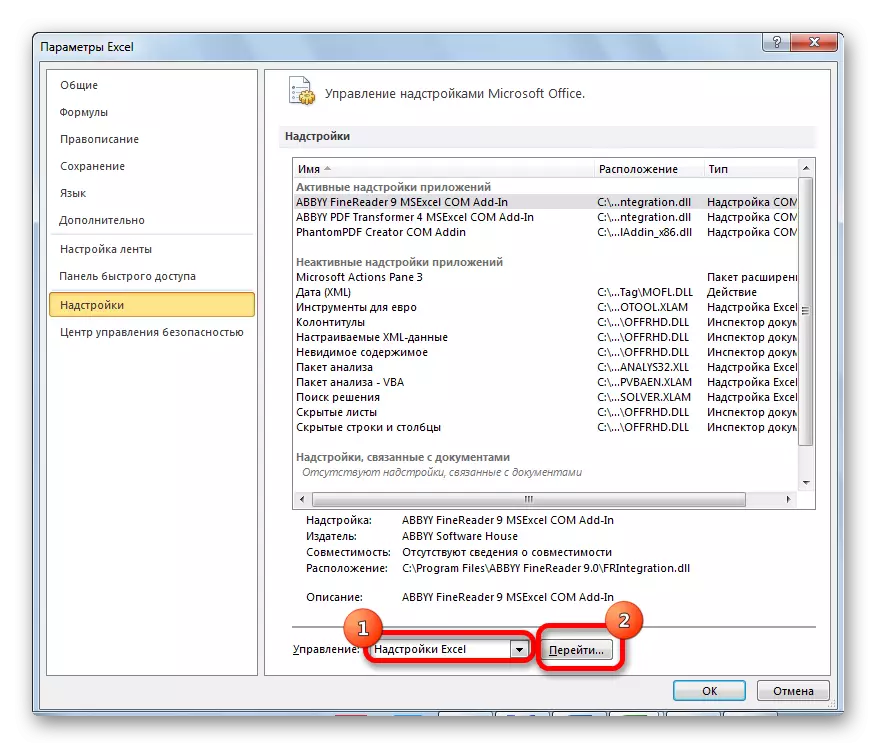
- I bunden af åbningsvinduet omarrangerer vi kontakten i "Control" -positionen til "Excel-tilføjelsespositionen", hvis den er i en anden position. Klik på "GO-knappen".
- Åbnet vindue tilgængeligt for Excel's overbygning. Vi sætter et tick om "analysepakke" -genstanden. Klik på knappen "OK".
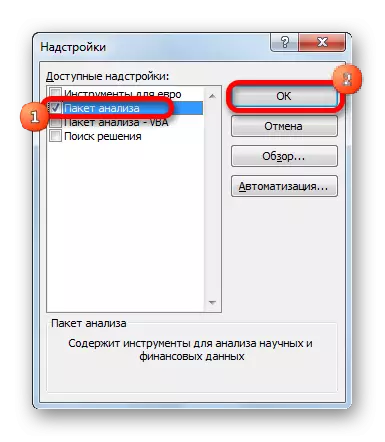
Nu, når vi flytter til fanen "Data", vil vi se en ny knap i værktøjslinjen "Data Analysis".
Typer af regressionsanalyse
Der er flere typer regressioner:- parabolisk;
- strøm;
- logaritmic;
- eksponentiel;
- vejledende;
- hyperbolic;
- Lineær regression.
Vi vil tale mere om implementeringen af den sidste type regressionsanalyse i Excele mere.
Lineær regression i Excel-programmet
Nedenfor er der som et eksempel præsenteret en tabel, hvor den gennemsnitlige daglige lufttemperatur på gaden, og antallet af købere for den relevante arbejdsdag er angivet. Lad os finde ud af ved hjælp af regressionsanalyse, præcis, hvordan vejrforholdene i form af lufttemperatur kan påvirke den kommercielle institutions deltagelse.
Den generelle ligning af regression af de lineære arter er som følger: Y = A0 + A1X1 + ... + AKK. I denne formel betyder Y-variabel, indflydelsen af de faktorer, som vi forsøger at udforske. I vores tilfælde er dette antallet af købere. Værdien af X er forskellige faktorer, der påvirker variablen. Parametre A er koefficienter regression. Det vil sige, det er de, der bestemmer betydningen af en bestemt faktor. Indekset K betegner det samlede antal af disse faktorer.
- Klik på knappen "Data Analysis". Det er sendt i fanen Hjem i værktøjslinjen "Analyse".
- Et lille vindue åbnes. I det vælger vi varen "regression". Klik på knappen "OK".
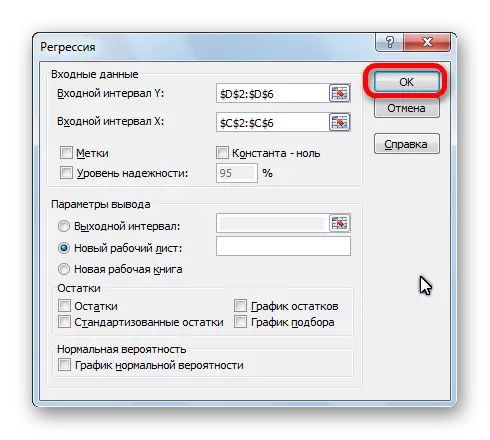
- Omregningsindstillingsvinduet åbnes. Det er obligatorisk for at udfylde felterne "Input Interval Y" og "Input Interval X". Alle andre indstillinger kan efterlades som standard.
I feltet "Input Interval Y" angiv adressen på rækkevidden af celler, hvor variabler er placeret, indflydelsen af de faktorer, som vi forsøger at etablere. I vores tilfælde vil disse være cellerne i kolonnen "Antal købere". Adressen kan indtastes manuelt fra tastaturet, og du kan blot vælge den ønskede kolonne. Den sidste mulighed er meget lettere og mere praktisk.
I feltet "Input Interval X" indtaster vi adressen på cellerne af cellerne, hvor denne faktor er placeret, hvis indflydelse på den variable, vi ønsker at installere. Som nævnt ovenfor skal vi etablere effekten af temperatur på antallet af butikskøbere, og indtaste derfor adressen på cellerne i kolonnen "Temperatur". Dette kan laves de samme måder som i feltet "Antal købere".

Ved hjælp af andre indstillinger kan du indstille etiketterne, niveauet for pålidelighed, konstant til nul, vise et diagram af en normal sandsynlighed og udføre andre handlinger. Men i de fleste tilfælde behøver disse indstillinger ikke at blive ændret. Det eneste, der skal være opmærksom på, er til outputparametrene. Som standard udføres udgangen af analyseresultaterne på et andet ark, men omarrere kontakten, du kan indstille udgangen i det angivne interval på samme ark, hvor bordet med kildedataene er placeret, eller i en separat bog, det vil sige i en ny fil.
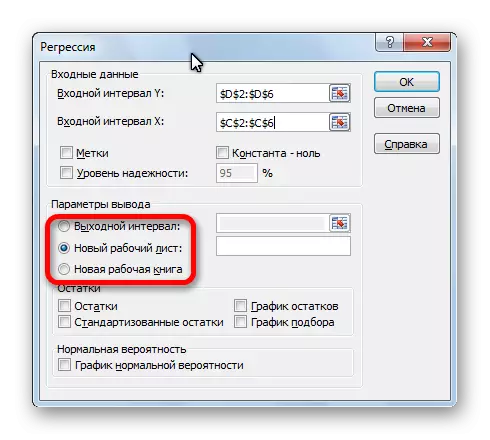
Når alle indstillinger er indstillet, skal du klikke på knappen "OK".
Analyse af resultaterne af analysen
Resultaterne af regressionsanalysen vises i form af et bord på det sted, der er angivet i indstillingerne.
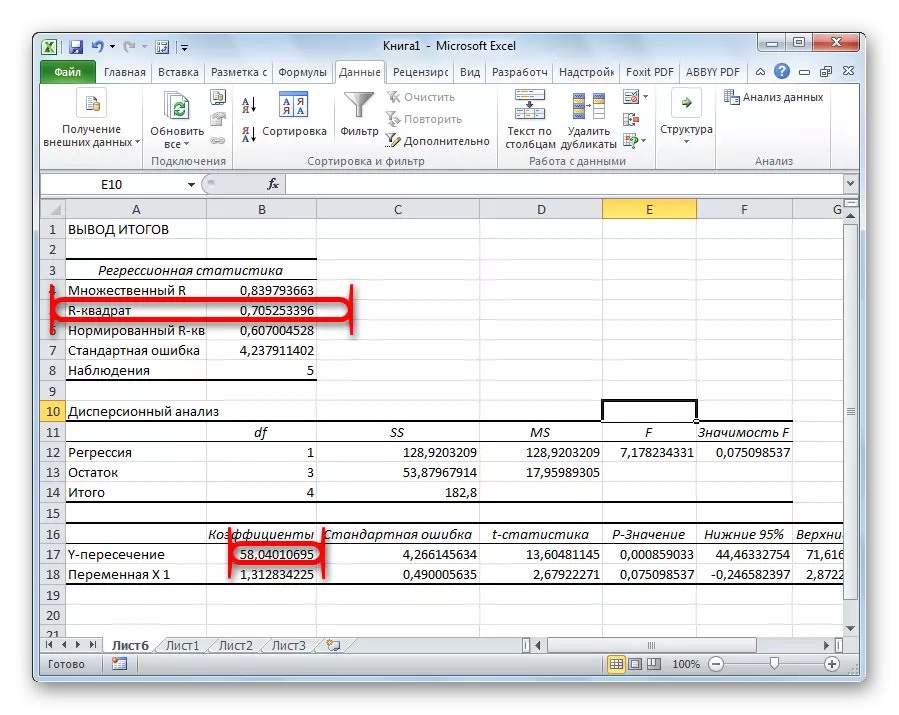
En af hovedindikatorerne er R-Square. Det angiver kvaliteten af modellen. I vores tilfælde er denne koefficient 0,705 eller ca. 70,5%. Dette er et acceptabelt niveau af kvalitet. Afhængighed mindre end 0,5 er dårligt.
En anden vigtig indikator er placeret i cellen ved krydset af "Y-Intersection" -linjen og kolonnen "koefficienter". Det angiver, hvilken værdi der vil være i Y, og i vores tilfælde er dette antallet af købere, med alle andre faktorer svarende til nul. Denne tabel er 58,04 i denne tabel.
Værdien ved skæringspunktet mellem tælleren "Variable X1" og "koefficienter" viser niveauet af afhængighed af Y fra X. I vores tilfælde er det niveauet af afhængighed af antallet af kunder i butikken på temperaturen. Koefficienten på 1,31 betragtes som en ret høj indikator for indflydelse.
Som du kan se, ved hjælp af Microsoft Excel-programmet er det ret nemt at lave en tabel med regressionsanalyse. Men at arbejde med de data, der er opnået ved udgangen, og forstå deres essens, vil kun en forberedt person kunne.