方法1:使用自動工具
Excel有一個自動工具,旨在拆分列中的文本。它無法自動正常工作,因此必須手動完成所有操作,選擇處理的數據范圍。但是,該設置在實現中最簡單且快速。
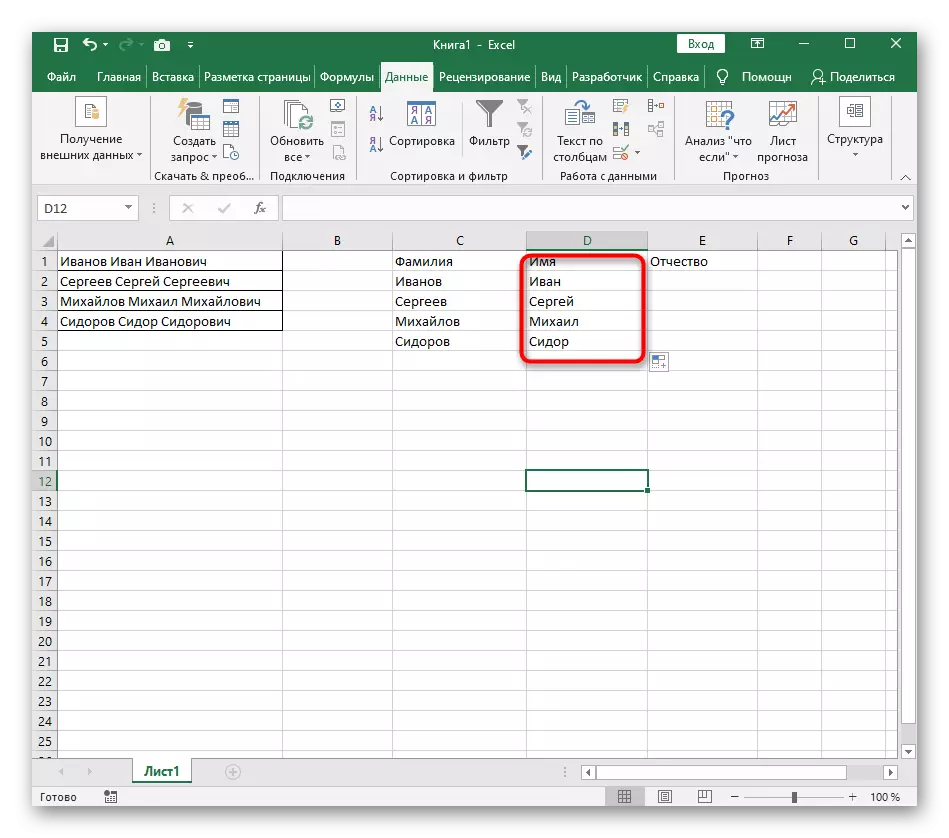
- 使用鼠標左鍵,選擇要在列上劃分的文本的所有單元格。
- 之後,轉到“數據”標籤並單擊“文本到列”按鈕。
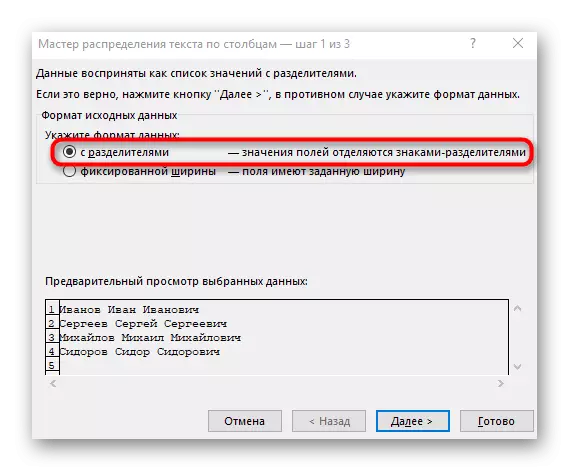
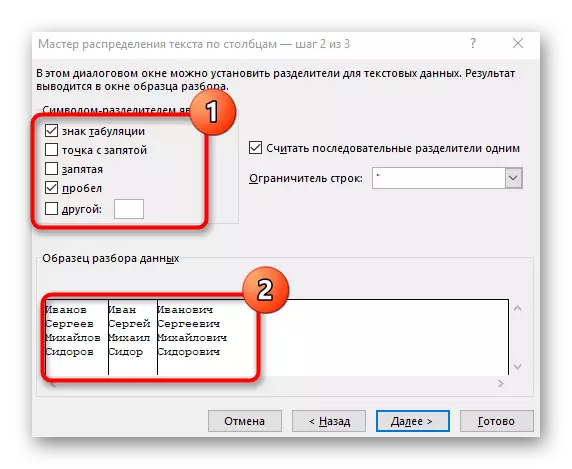
- 出現“列文本嚮導”窗口,其中您要在其中選擇“使用分隔符”的數據格式。分隔符最常執行空間,但如果這是另一個標點符號,則需要在下一步中指定它。
- 勾選序列符號檢查或手動輸入,然後讀取下面的窗口中的初步分離結果。
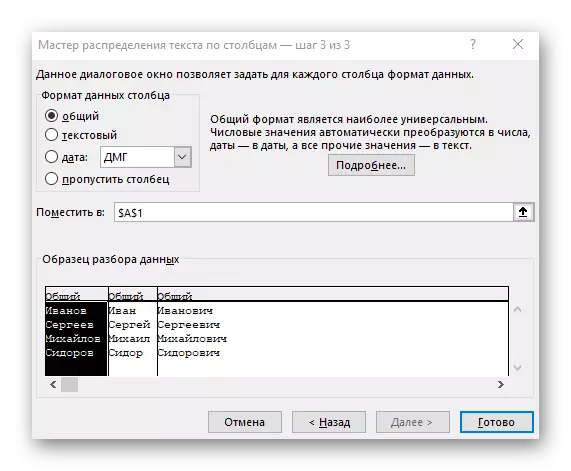
- 在最後一步中,您可以指定新的列格式和必須放置的位置。完成設置後,單擊“完成”以應用所有更改。
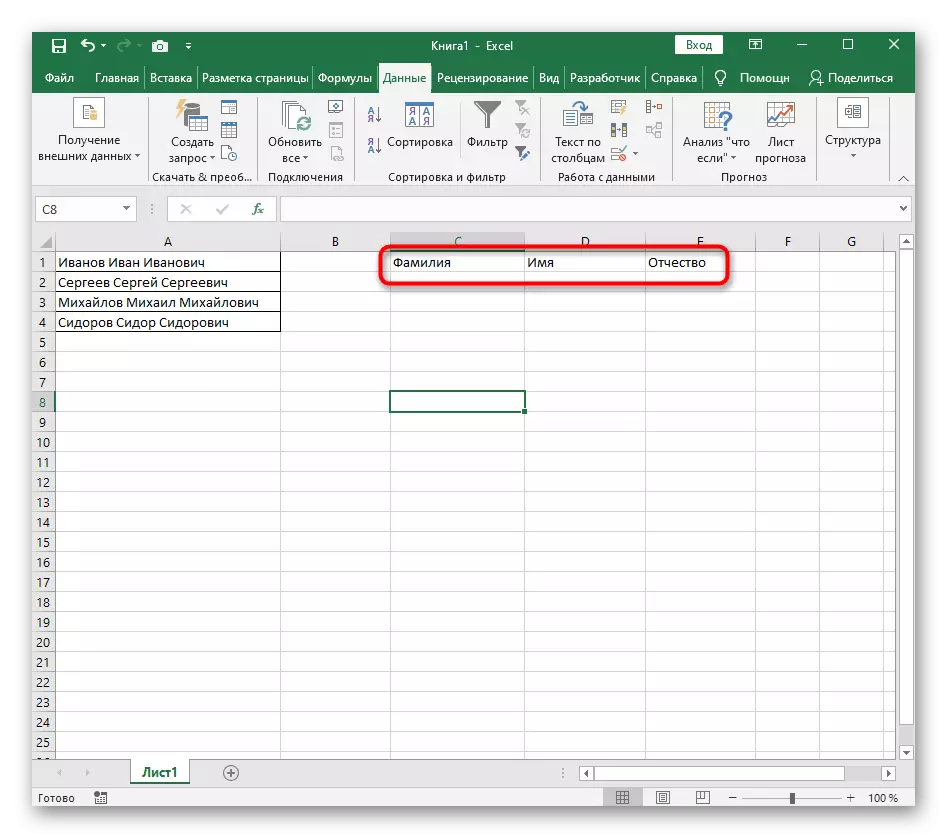
- 返回表格並確保分離已成功傳遞。


根據該指令,我們可以得出結論,這種工具的使用在最佳的那些情況下,其中必須僅執行一次,表示每個單詞是新列的。但是,如果新數據不斷被介紹到表中,一直劃分它們會以這種方式不太方便,所以在這種情況下,我們建議熟悉以下方式。
方法2:創建文本拆分公式
在Excel中,您可以獨立地創建一個相對複雜的公式,允許您計算單元格中的單詞的位置,查找間隙並將每個分割為單獨的列。作為一個例子,我們將採用由空格分隔的三個單詞組成的單元格。對於他們每個人來說,它將採用自己的公式,因此我們將該方法分為三個階段。第1步:第一個單詞的分離
第一單詞的公式最簡單,因為它必須僅從一個間隙中排斥以確定正確的位置。考慮其創建的每個步驟,因此形成了完整的圖片是為什麼需要某些計算。
- 為方便起見,使用我們添加分隔文本的簽名創建三個新列。你可以做同樣或跳過這一刻。
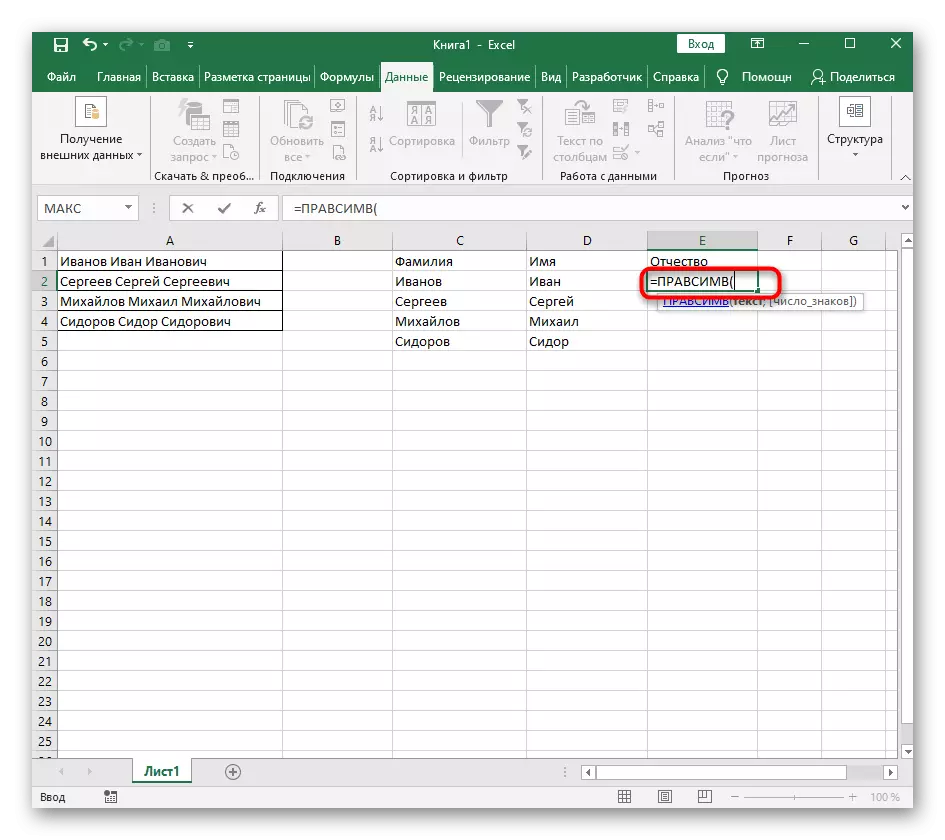
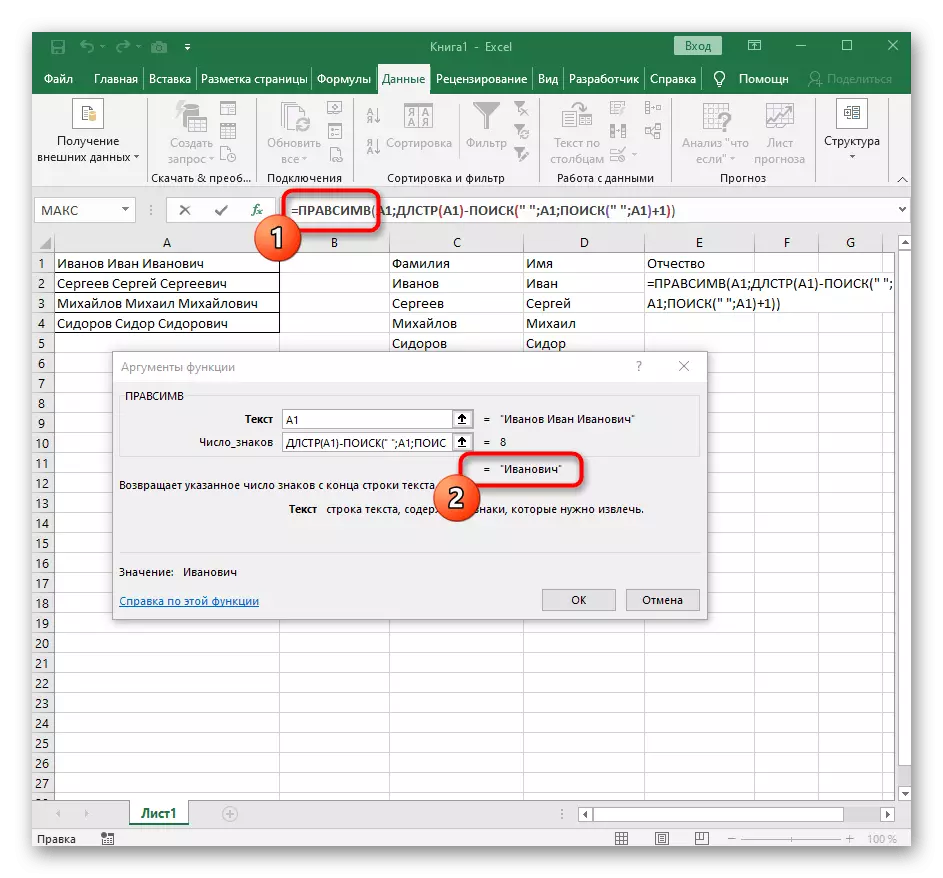
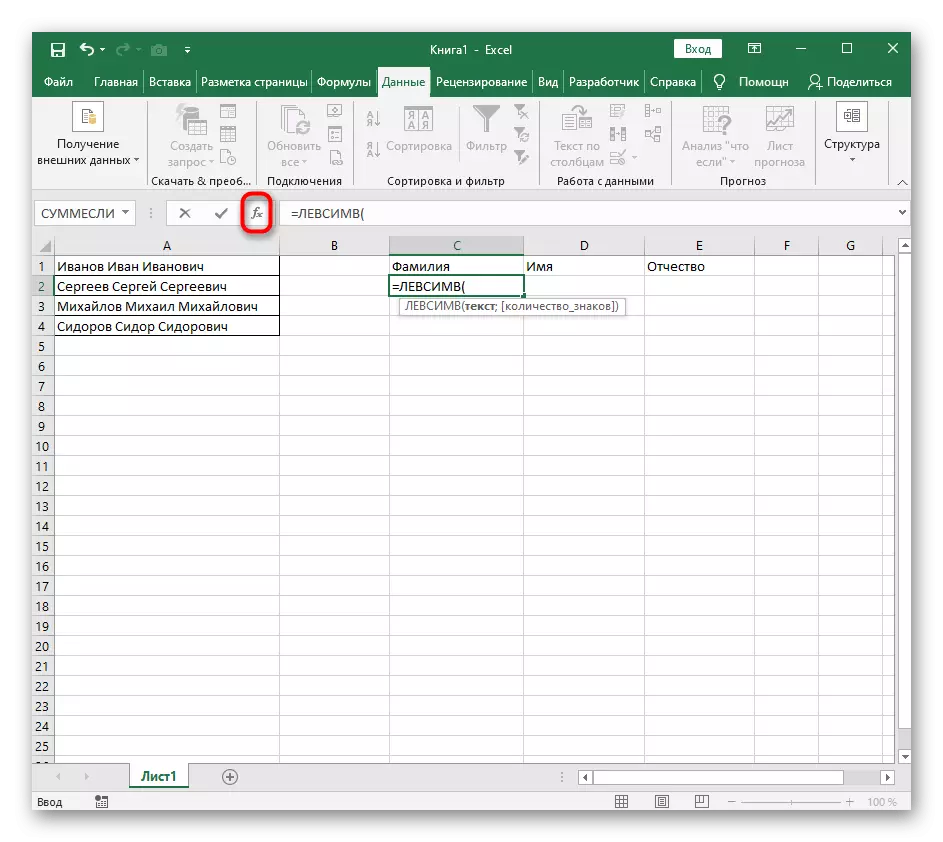
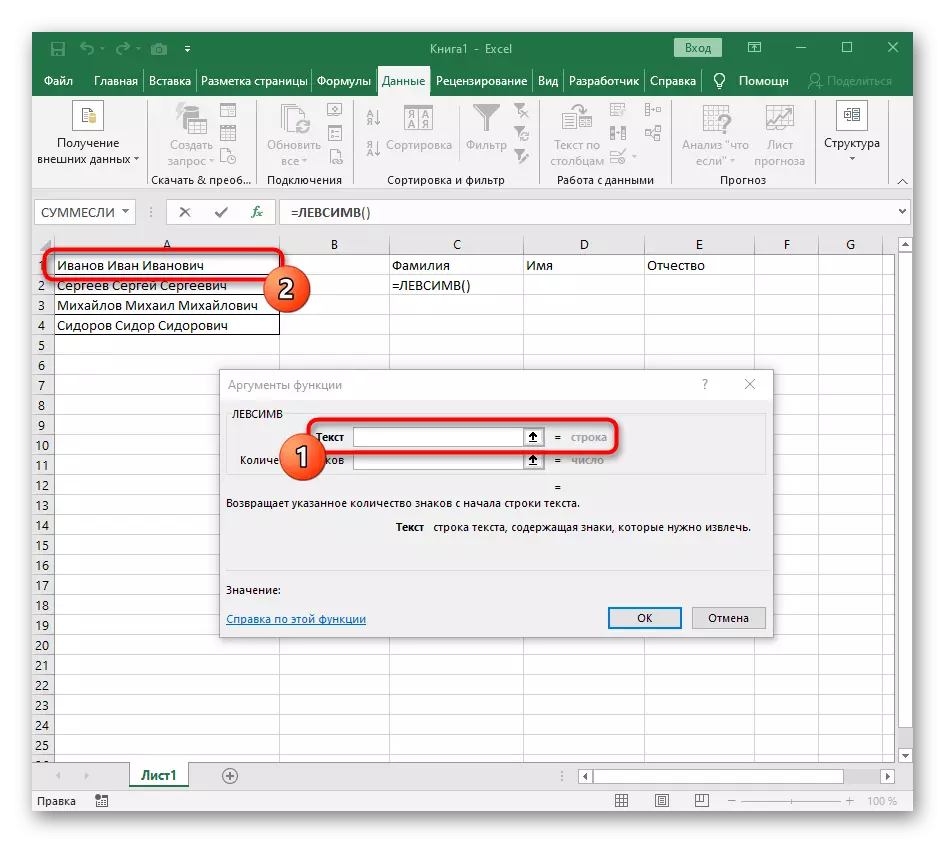
- 選擇要將第一個單詞定位的單元格,並記下公式= lessimv(。
- 之後,按“選項參數”按鈕,從而進入公式的圖形編輯窗口。
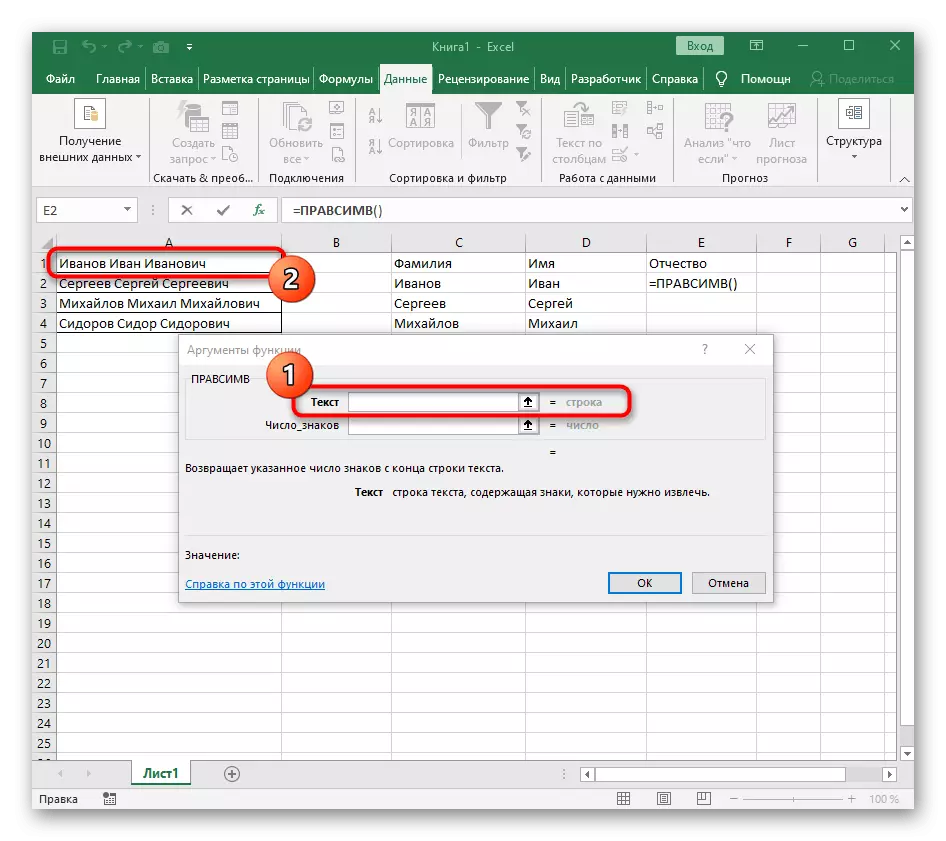
- 作為參數的文本,通過在表上的鼠標左鍵上單擊它來指定具有銘文的單元格。
- 空間或另一個分隔符的符號數將必須計算,但手動我們不會執行此操作,但我們將使用另一個公式 - 搜索()。
- 一旦您以這樣的格式錄製,它將出現在頂部的單元格文本中,並將以粗體突出顯示。單擊它以快速轉換到此功能的參數。
- 在“骨架”字段中,只需將空間或分隔符使用,因為它會幫助您了解單詞結束的位置。在“text_-search”中指定正在處理的相同單元格。
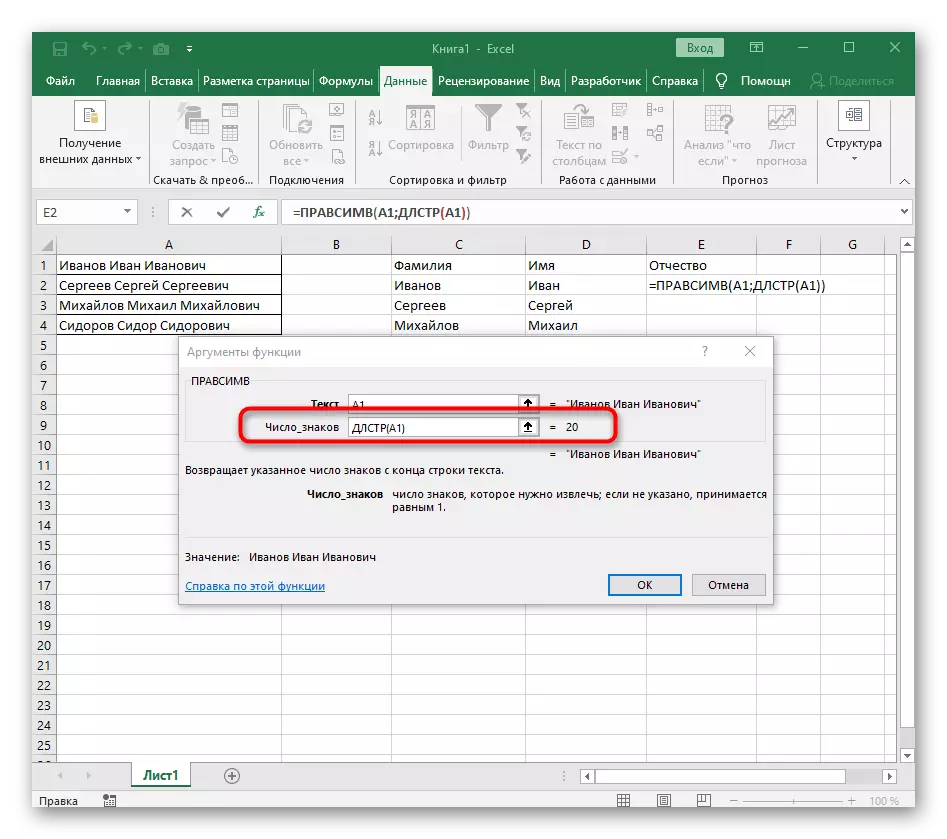
- 單擊第一個函數返回它,然後在第二個參數-1的末尾添加。這是必要的,以便為搜索公式考慮而不是所需的空間,而是對其的符號。可以在以下屏幕截圖中看到,結果顯示在沒有任何空間的情況下,這意味著進行公式編譯。
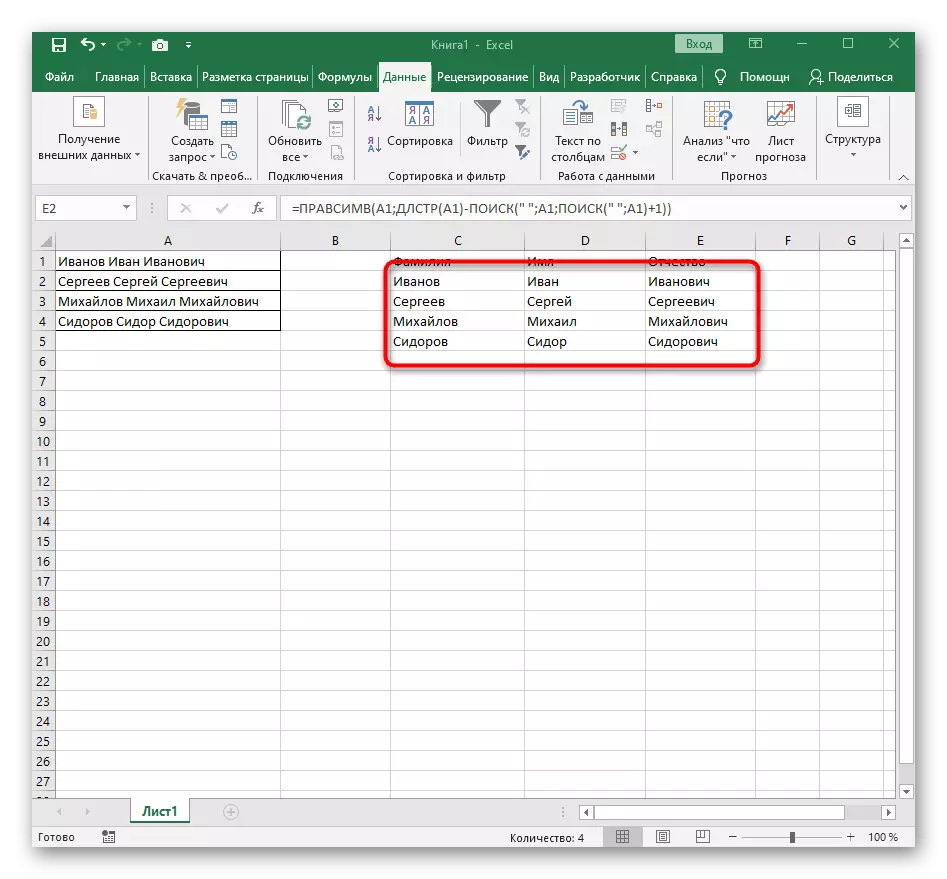
- 關閉功能編輯器並確保在新單元格中正確顯示該單詞。
- 握住右下角的單元格,然後拖動到所需的行數以延伸它。因此,其他表達的值是替代的,必須劃分,並且自動實現公式。




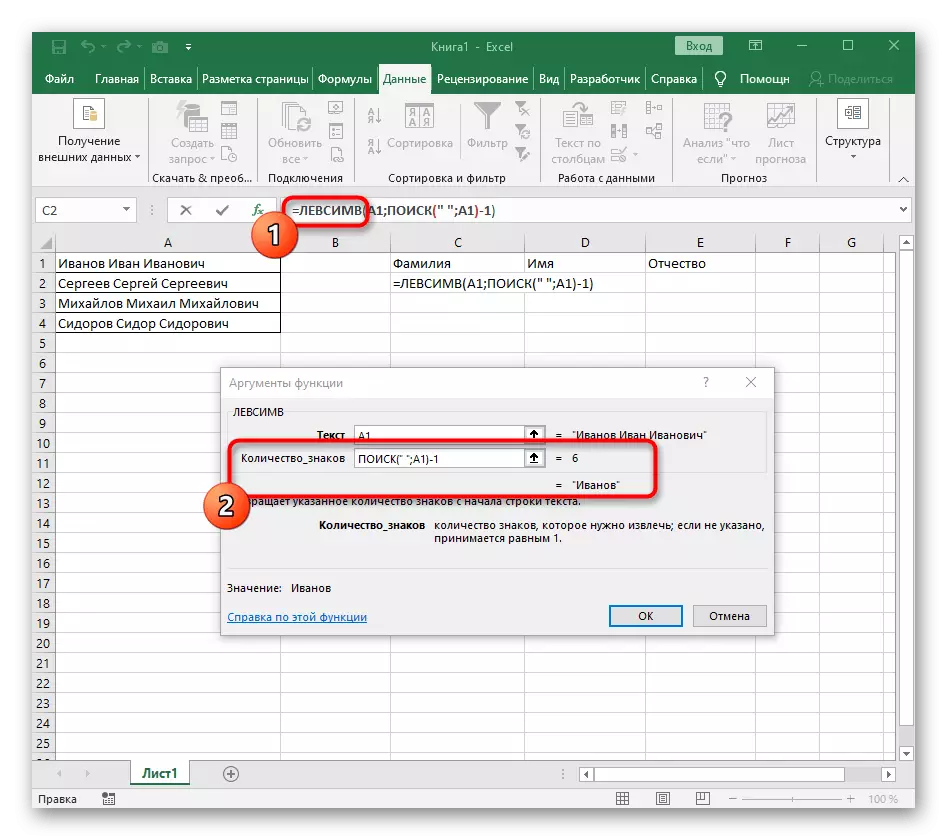
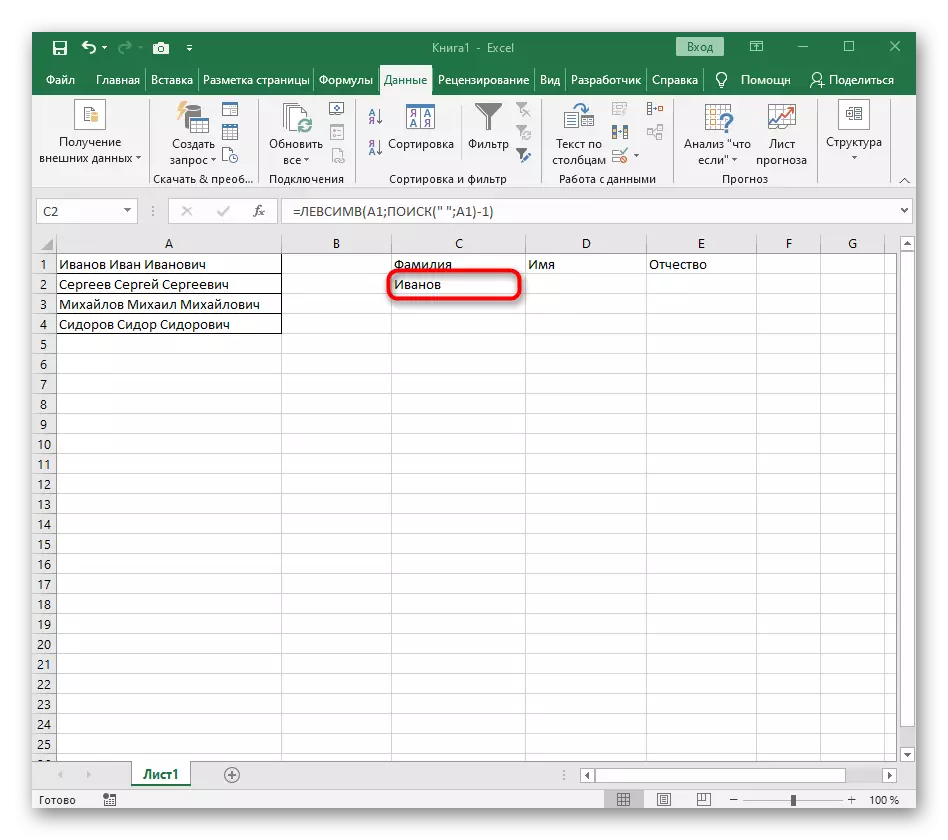

完全創建的公式具有表單= Levsimv(A1;搜索(“; a1)-1),您可以根據上述說明創建它,或者如果條件和分隔符適合,請插入此。不要忘記替換已加工的單元格。
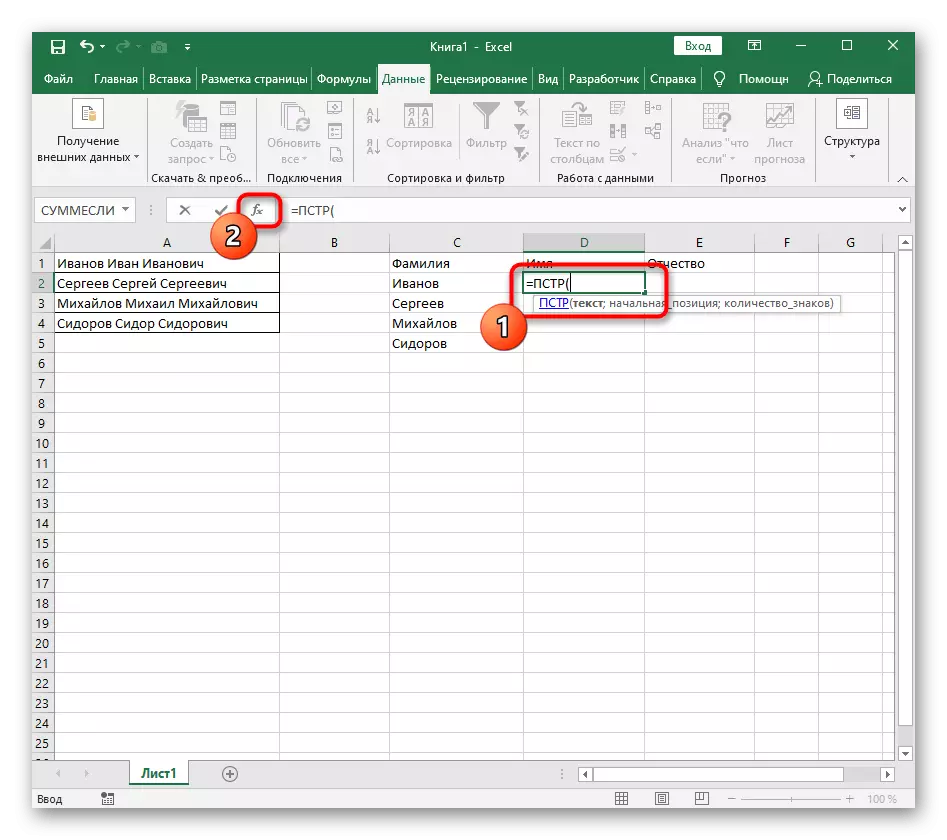
第2步:第二個單詞的分離
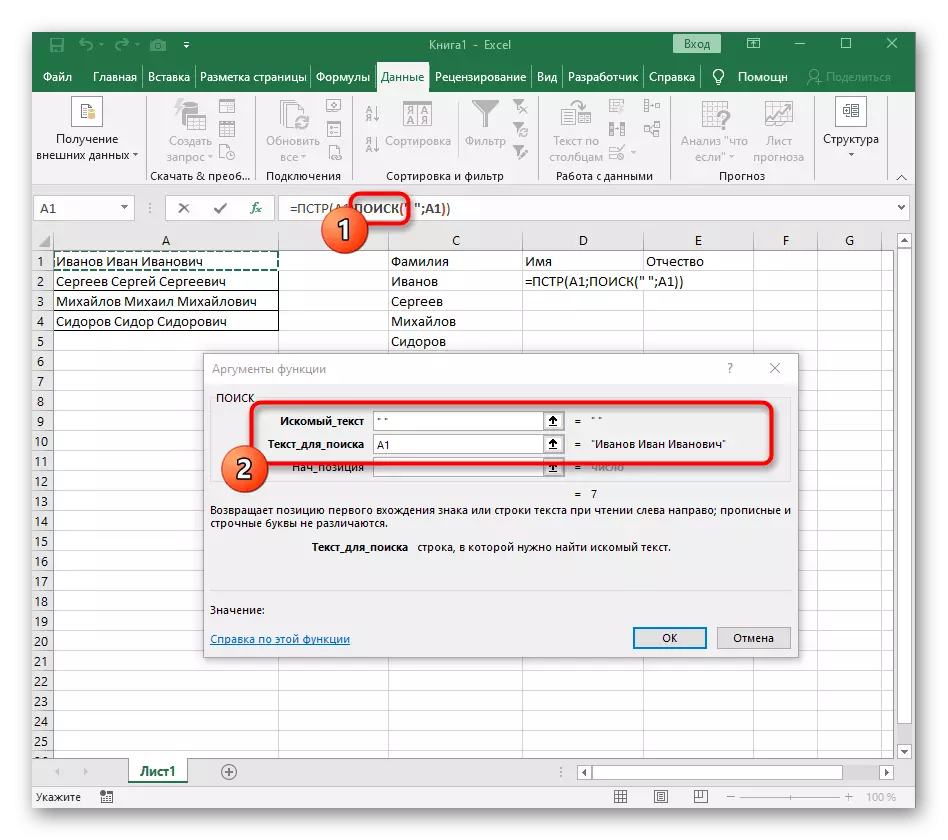
最難的是劃分第二個詞,在我們的案例中是名稱。這是由於它是由兩側的空間包圍,因此您必須考慮到兩者,以便正確計算該位置的大規模公式。
- 在這種情況下,主要公式將是= PST( - 以此形式寫入,然後轉到參數設置窗口。
- 此公式將在文本中搜索所需的字符串,該字符串由單元格/分離的銘文選擇。
- 必須使用已經熟悉的輔助公式搜索()來確定該線的初始位置。
- 向其創建和移動,以與前一步中所示的方式相同。作為所需文本,使用分隔符,並將單元格指定為要搜索的文本。
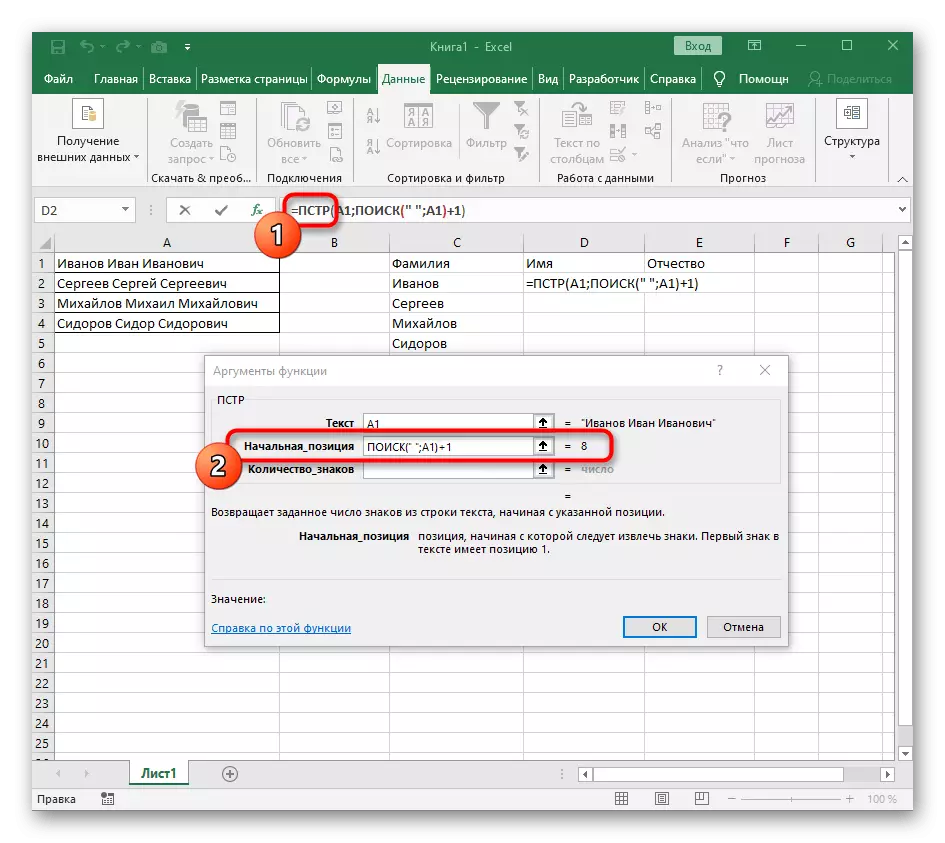
- 返回上一個公式,其中添加到“搜索”函數+1最後在找到的空間後從下一個字符開始一個帳戶。
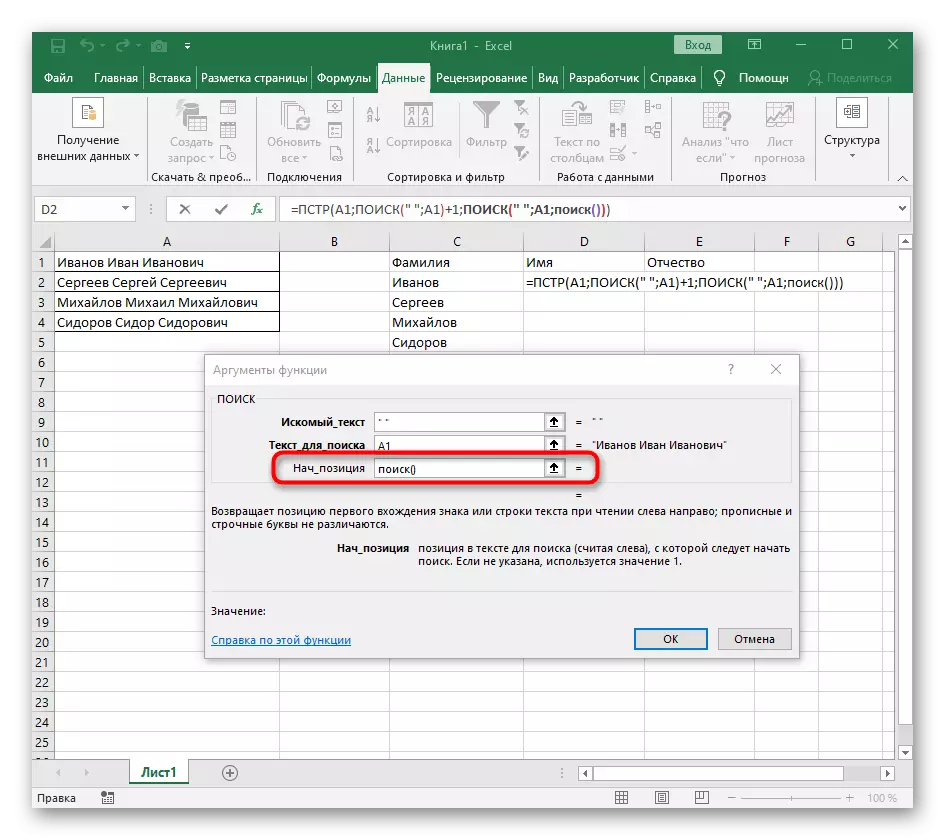
- 現在,公式已經開始從第一個字符名稱搜索行,但它仍然不知道在哪裡完成它,因此,在“ulity_names”中再次完成,寫下搜索公式()。
- 轉到其論點並以已熟悉的形式填寫它們。
- 以前,我們沒有考慮這個函數的初始位置,但現在有必要進入搜索(),因為此公式不應該找到第一個間隙,但第二個公式。
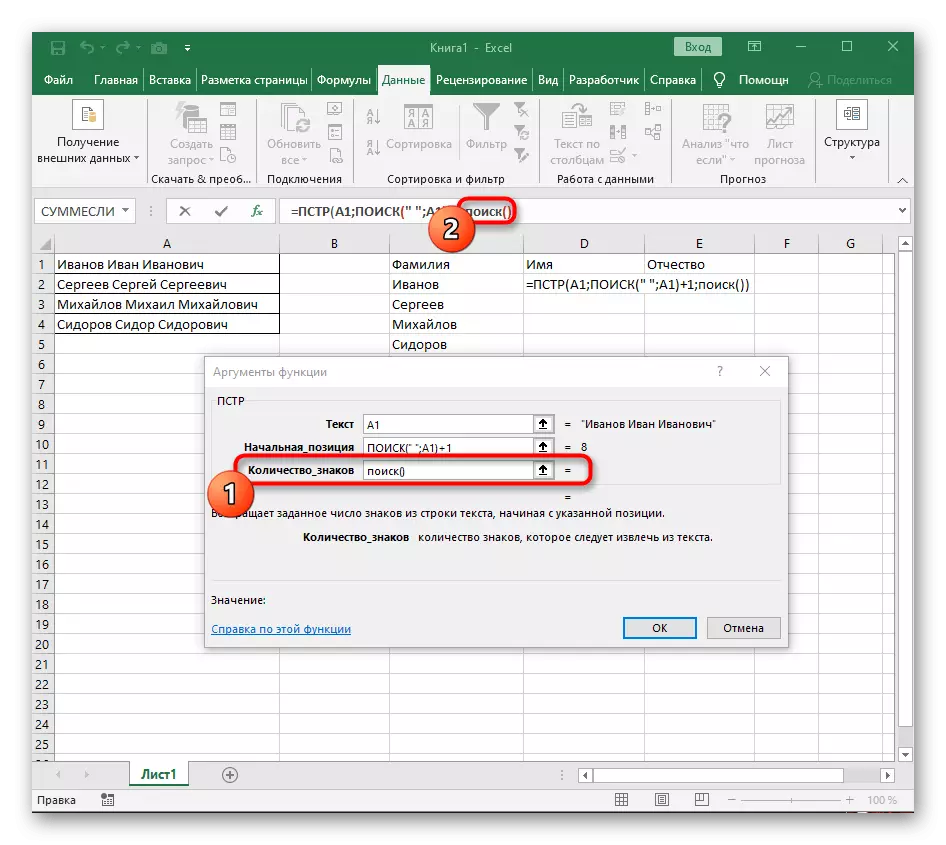
- 轉到創建的函數並以同樣的方式填充它。
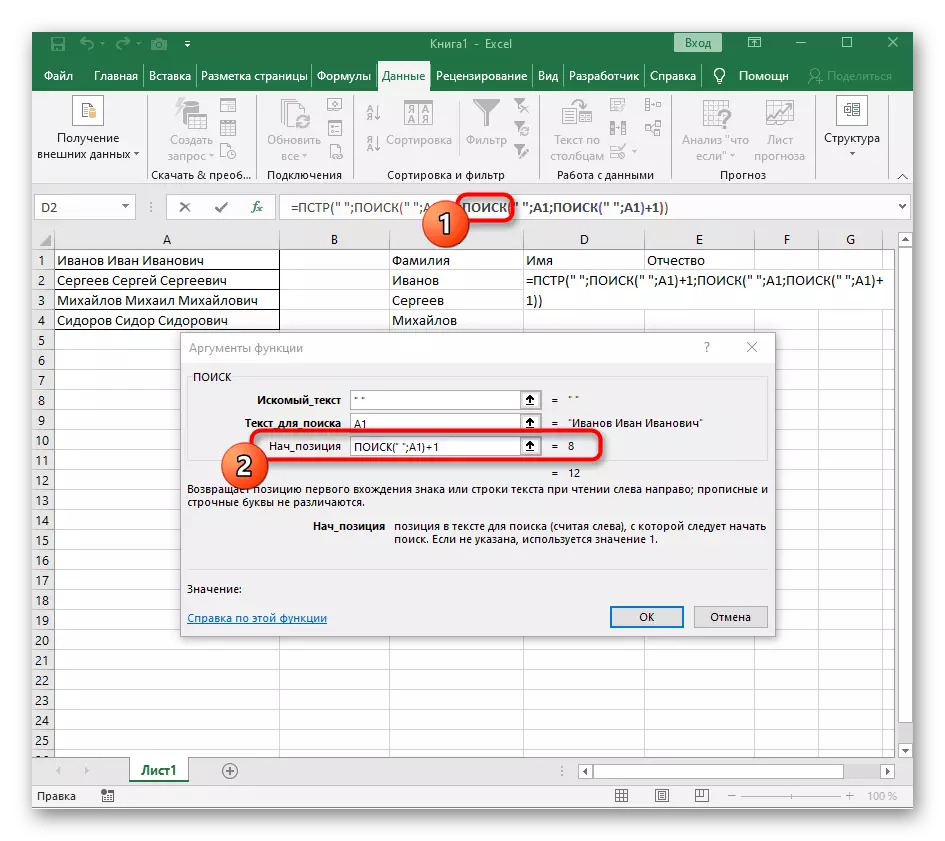
- 返回第一個“搜索”並在最後添加“nach_position”+1,因為它不需要搜索行的空間,而是下一個字符。
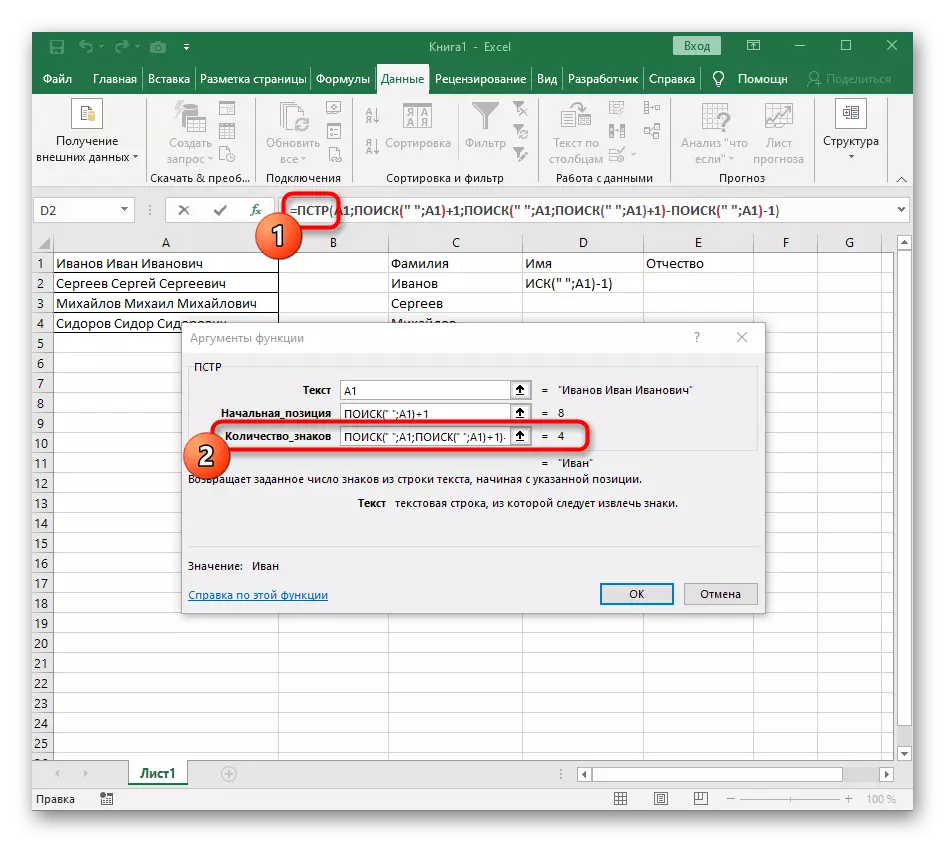
- 單擊root = PST並將光標放在行“Number_names”的末尾。
- 提取表達式的表達式(“; a1)-1以完成空間的計算。
- 返回表格,伸展公式並確保單詞顯示正確。


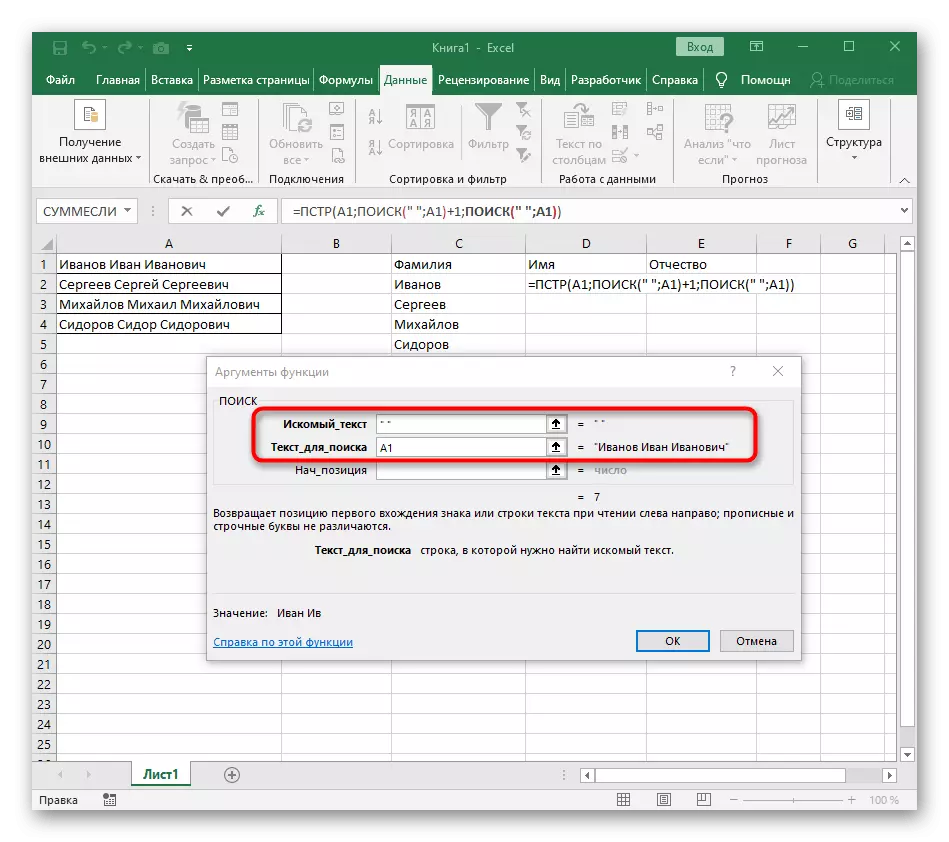

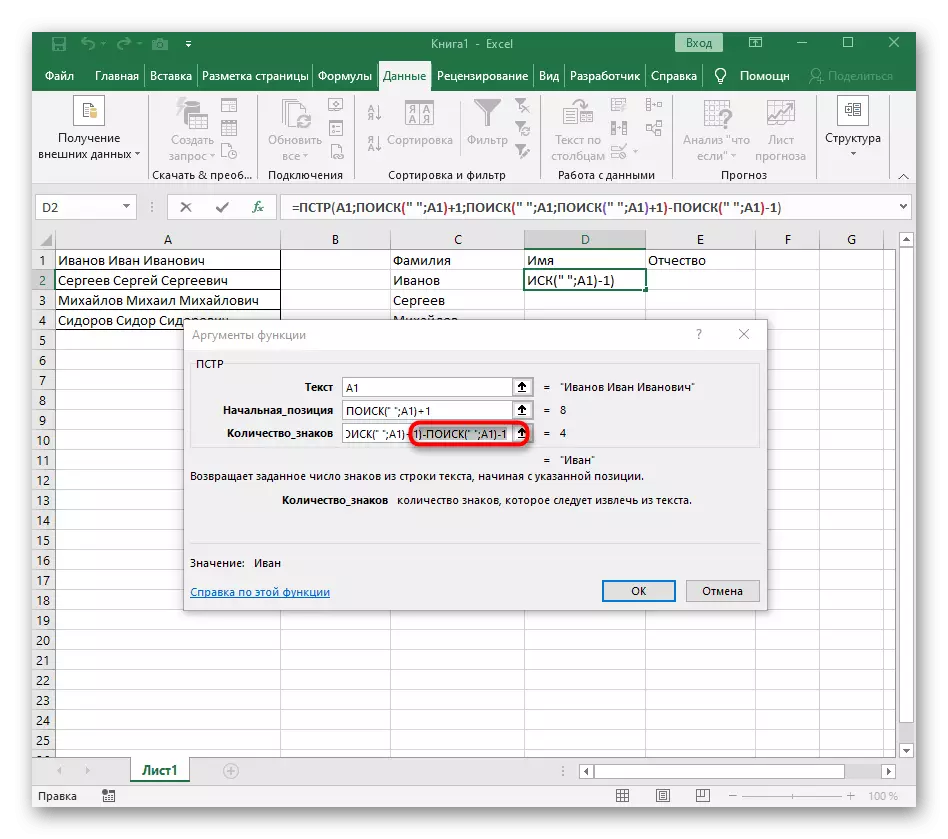
公式突出大,而且所有用戶都不了解它是如何工作的。事實上,為了搜索線路,我必須使用幾個函數來確定空格的初始和最終位置,然後一個符號從它們中奪走,以便顯示出這些大多數差距。結果,該公式是:= pstr(a1;搜索(“; a1)+1;搜索(”“a1; search(”; a1)+1)-poisk(“; a1) - 1)。用它作為一個例子,用文本替換小區號碼。
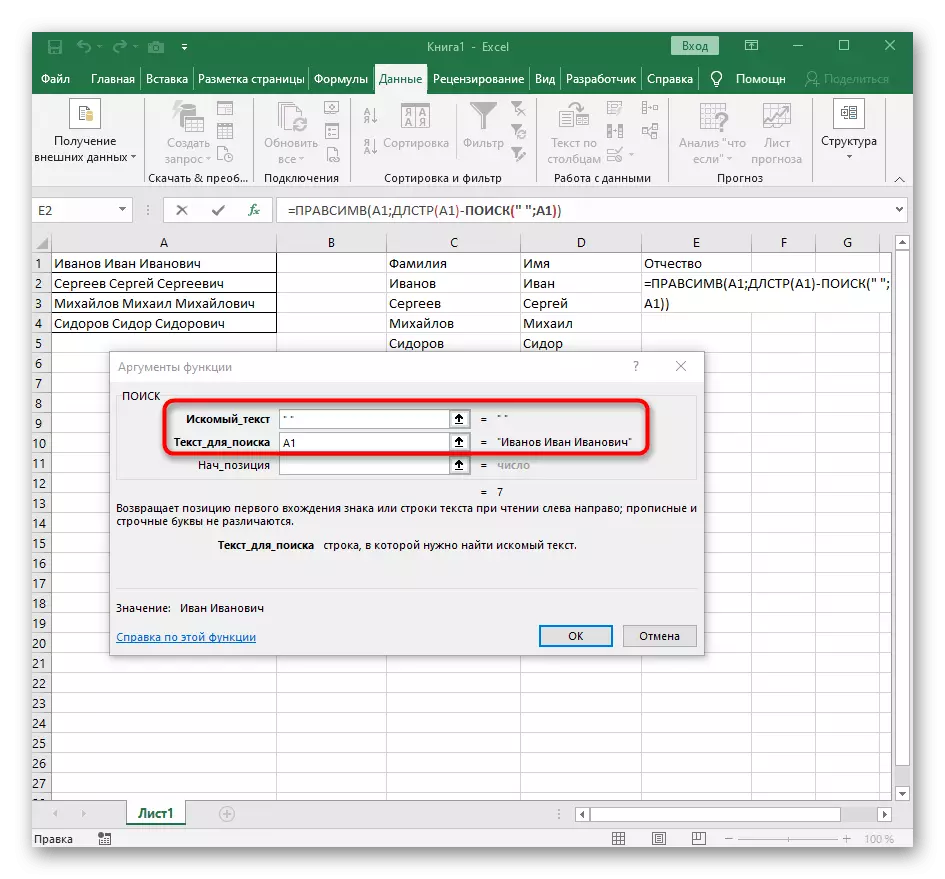
第3步:第三個詞的分離
我們指導的最後一步意味著第三個單詞的劃分,它看起來與第一個相同的方式,但通式略有變化。
- 在一個空的單元格中,對於未來文本的位置,write = rashesimv(並轉到此函數的參數。
- 作為文本,指定具有用於分離的銘文的單元格。
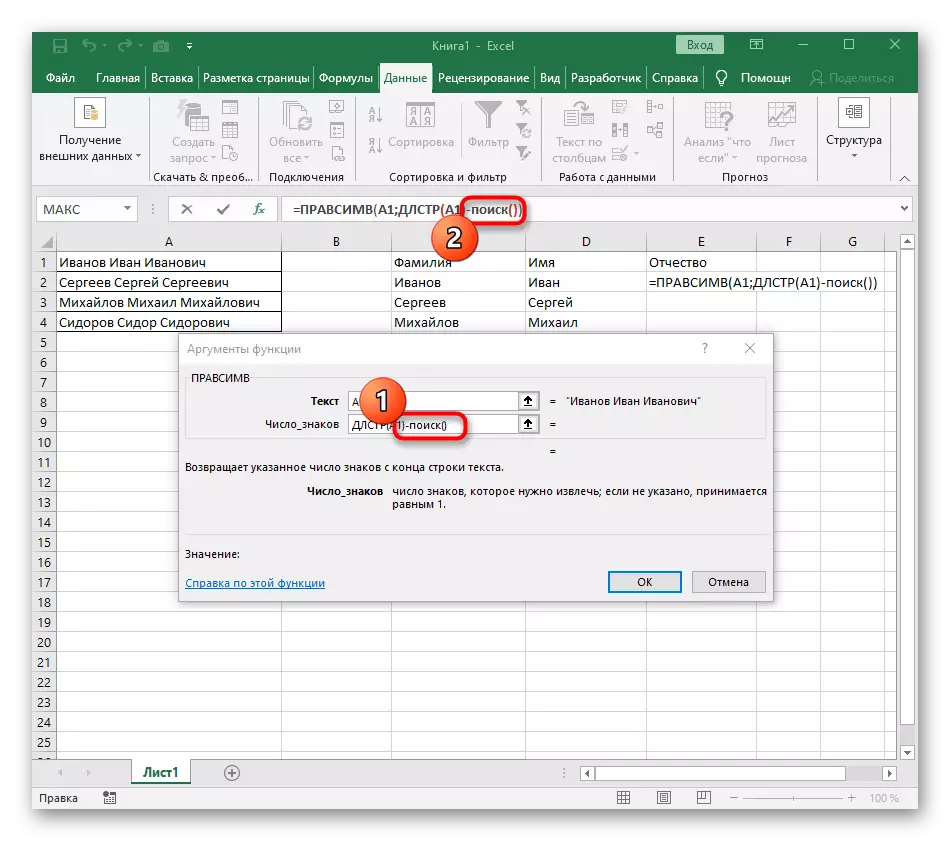
- 這次用於查找單詞的輔助功能稱為DLSTR(A1),其中A1是具有文本的相同單元格。此功能確定文本中的字符數,我們將保持僅適用於此。
- 要執行此操作,請添加-poisk()並轉到編輯此公式。
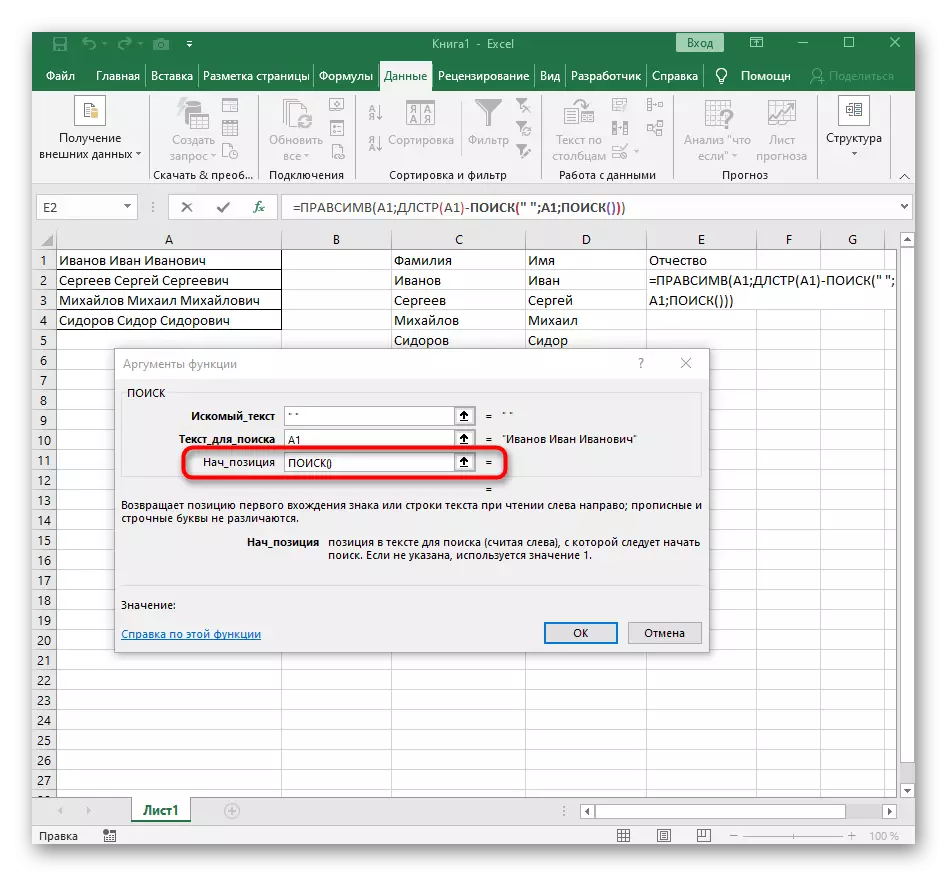
- 輸入已熟悉的結構以搜索字符串中的第一個分隔符。
- 添加另一個搜索起始位置()。
- 指定相同的結構。
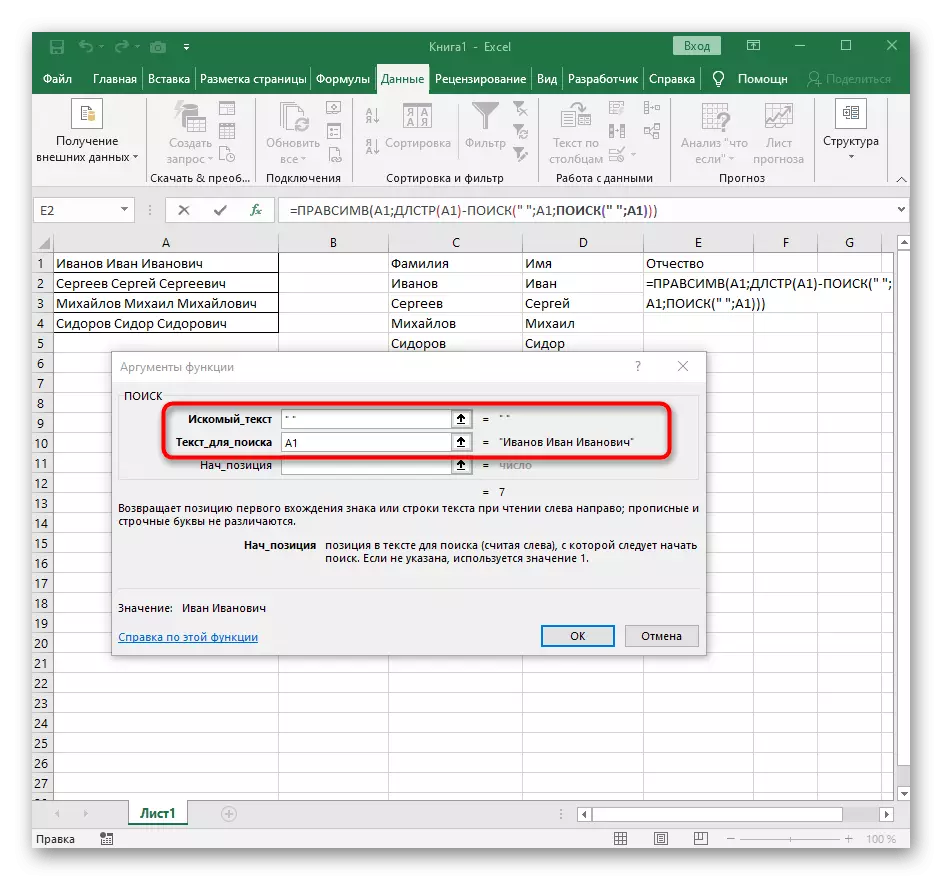
- 返回上一個搜索公式。
- 將+1添加到其初始位置。
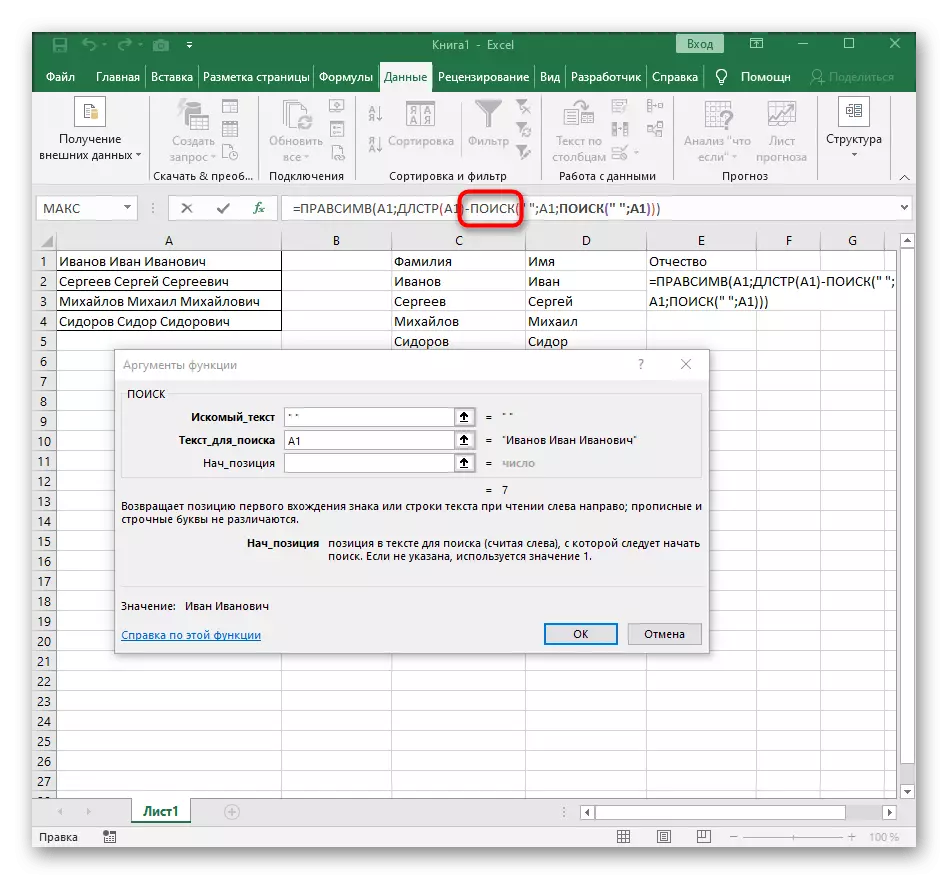
- 導航到公式Rascessv的根目錄,並確保正確顯示結果,然後確認更改。在這種情況下的完整公式看起來像= pracemir(a1; dlstr(a1)-poisk(“”; a1; search(“; a1)+1))。
- 因此,在下一個屏幕中,您可以看到所有三個單詞都正確分開,並在列中。為此,有必要使用各種公式和輔助功能,但它允許您動態擴展表,並且每次必須再次共享文本時,請不要擔心。如有必要,只需將其移動即可展開公式,以便自動影響以下單元格。