

最近,您可以越来越多地遇到需要将图像中包含的任何文本转换为电子文本形式的情况。为了节省时间而不是手动重印,您应该使用特殊的计算机应用程序来识别我们今天将告诉的文字。
如何数字化文本
在市场上有许多文本数字化应用程序的应用程序,因此每个用户都会找到满足要求的解决方案。方法1:ABBYY FINEREADER
来自俄罗斯开发人员的这种有条件的免费应用程序具有巨大的功能,不仅可以识别文本,还可以编辑它,以各种格式和扫描纸张来源保存。
- 要识别图片中的文本,首先,您需要将其上传到程序。要执行此操作,请在启动ABByy FineReader后,单击“在OCR编辑器”按钮中的“打开”按钮。
此操作后,将打开源选择窗口,您必须在其中查找和打开所需图像的位置。支持以下流行格式:JPEG,PNG,GIF,TIFF,XPS,BMP等以及PDF和DJVU文件。
- 在Abbyy FineReader下载后,文本识别在没有干预的情况下自动始于图片中。
如果要重复识别过程,只需按顶部菜单中的“识别”按钮。
- 有时并非所有符号程序都可以正确识别。这可能是如果源上的图像不是太高的质量,非常小的字体,文本中有几种不同的语言,使用非标准字符。但这没关系,因为可以使用文本编辑器和包含在其中包含的一组工具来手动纠正错误。
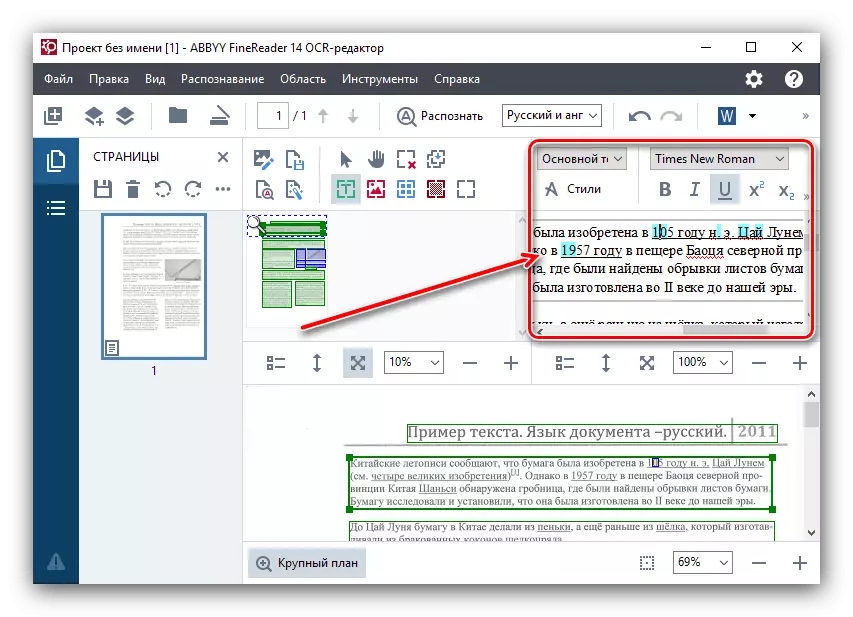
为了便于搜索数字化的不准确性,默认程序会分配具有绿松石颜色的可能错误。
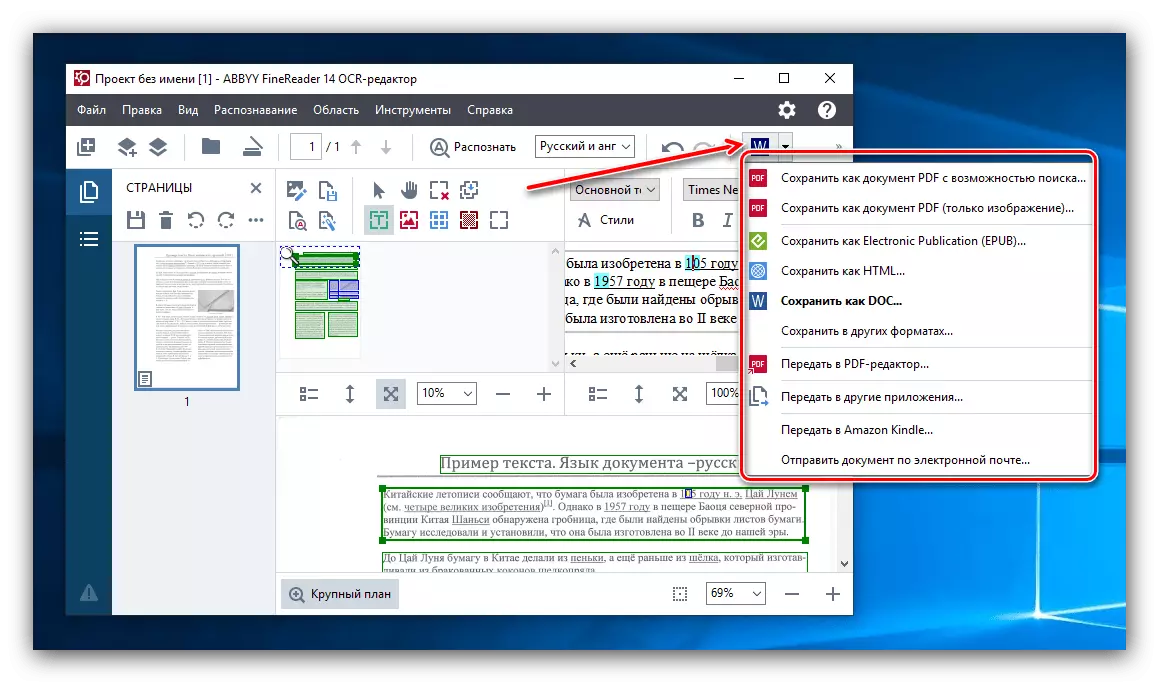
- 识别过程的逻辑到底是保留它的结果。要做到这一点,单击顶部菜单面板上的“保存”按钮。默认情况下,它的旧的Microsoft Word标志的图标视图。一个窗口出现在我们的面前,你可以自主确定将来在哪个位置与识别的文本文件将被定位,以及它的格式。下列选项可用于保存:DOC,DOCX,RTF,PDF,ODT,HTML,TXT,XLS,XLSX,PPTX,CSV,FB2,EPUB,DJVU。

ABBYY FineReader是目前最先进的解决方案,但它明确地建议,它可以防止分配和限制的试用版的付费模式。
方法2:的Readiris
Readiris应用程序加强了市场对上面提到的Fune骑士的最接近的竞争对手 - 它提供了这样的功能,某些方面执行好一点比ABBYY的产品。
- 从扫描仪或完成的图形文件 - 启动应用程序后,选择数据源数字化。
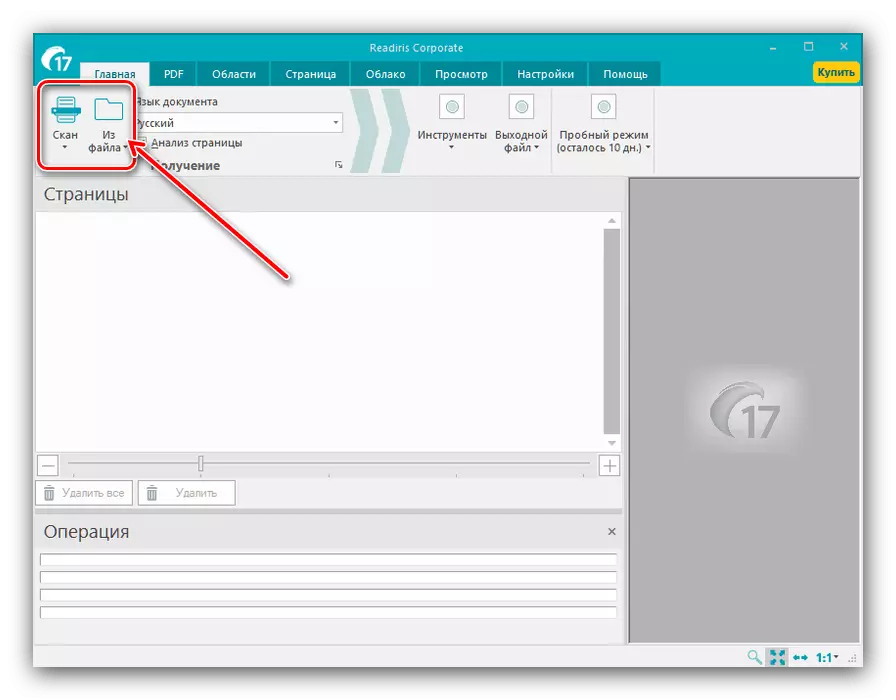
在这个例子中,我们将使用最后一个选项 - 它,使用“从文件”按钮。
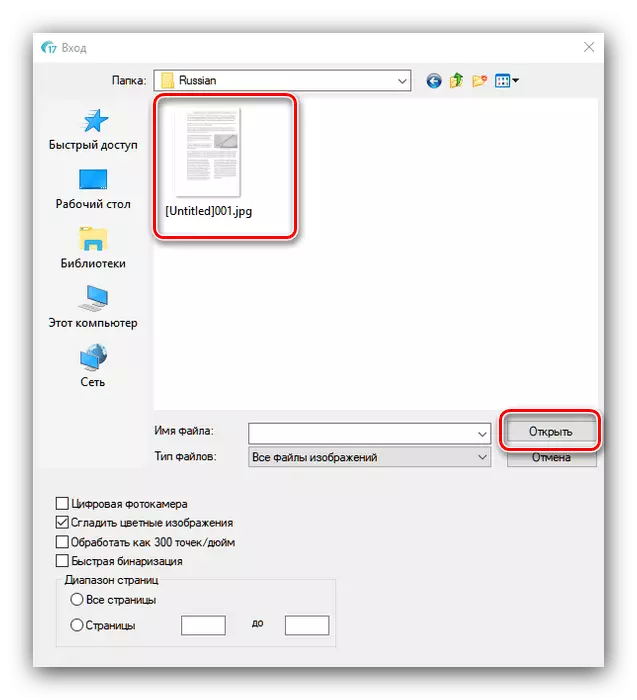
- 打开“资源管理器”对话框,在其中您应该选择必要的文件。大多数图形格式的支持,以及PDF。
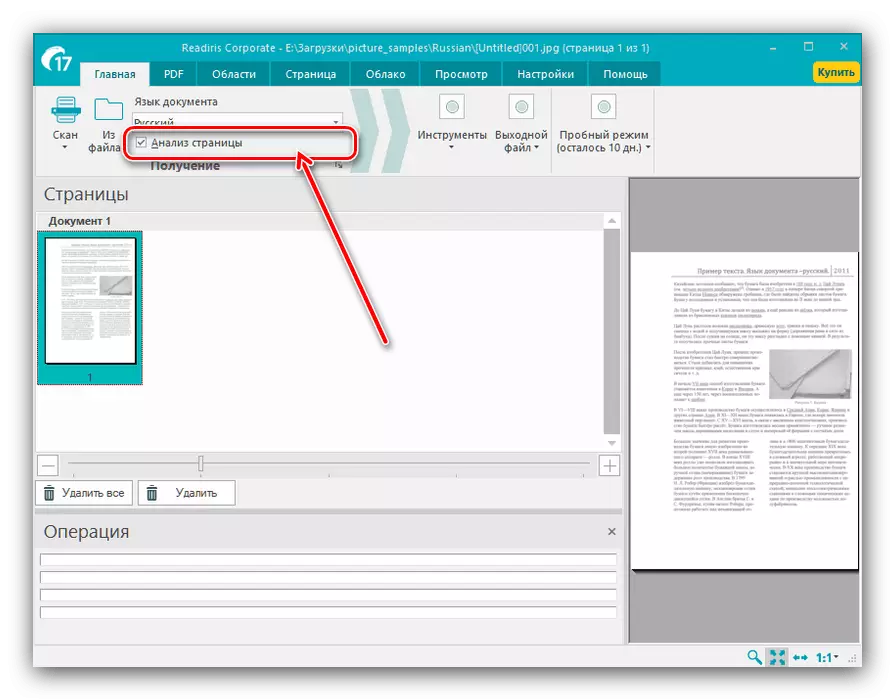
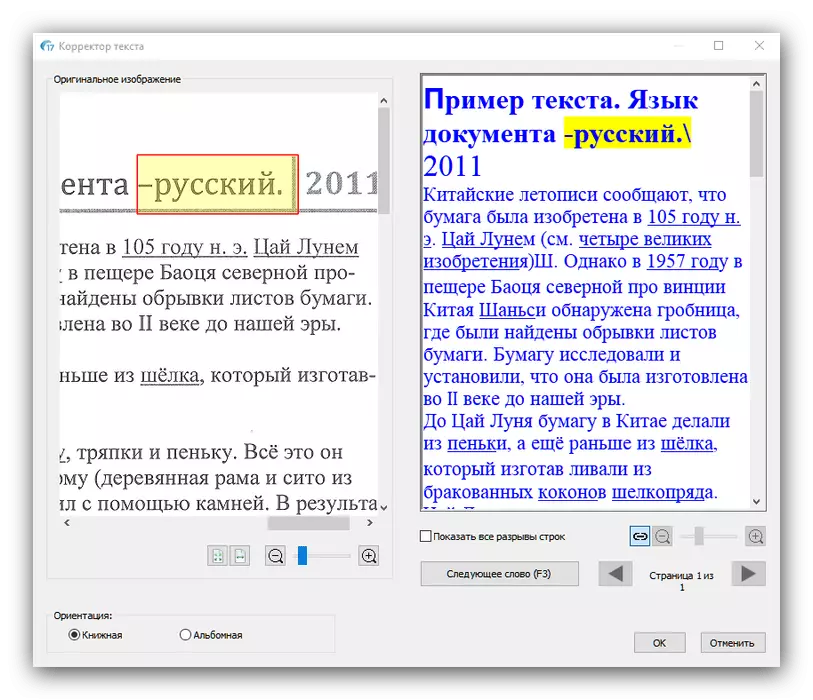
- 等到文档加载到程序,之后,文本识别应配置。首先,您需要安装的主要语言 - 从下拉菜单中选择。
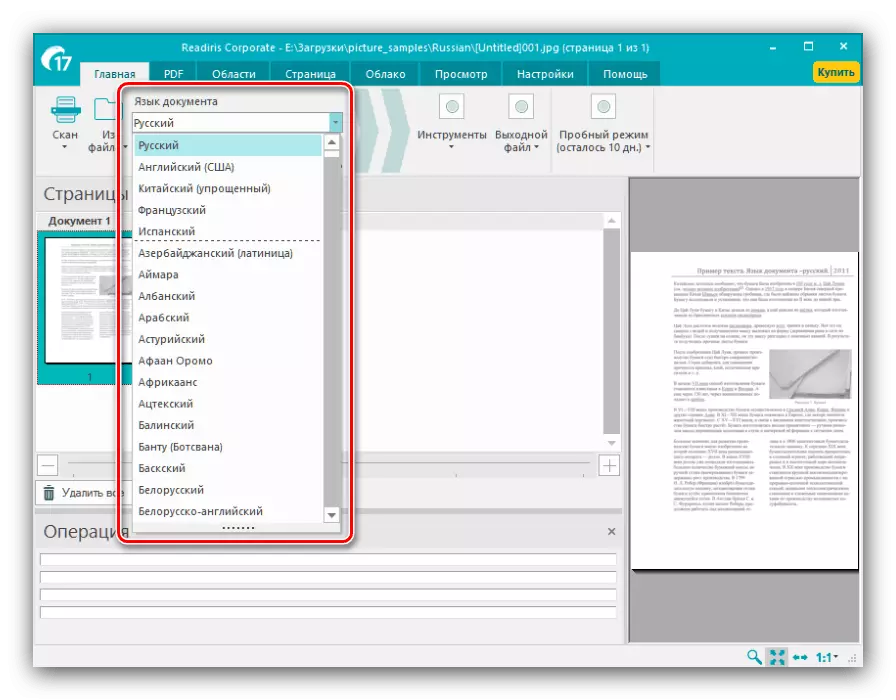
我们还建议指出“文本分析”选项,这要归功于其数字化的质量显著提高。
- 接下来,请参阅“工具”菜单 - 在其提供的参数将有助于解决一些扫描问题,如透视变形,图片或文本的相对位移到canvase的对比度不足。
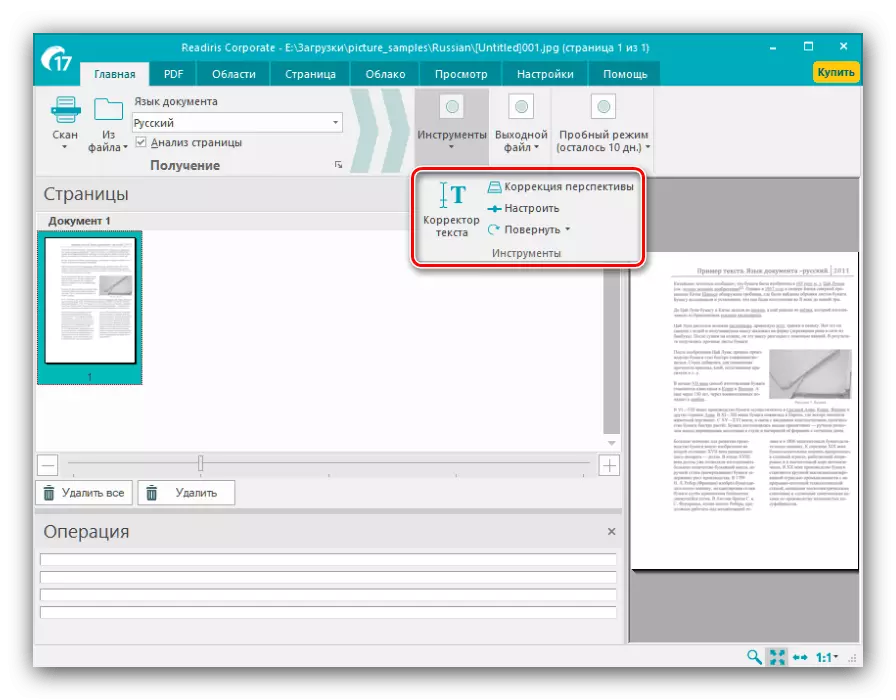
从这个菜单中,你也可以纠正文本如果识别不正确地工作。
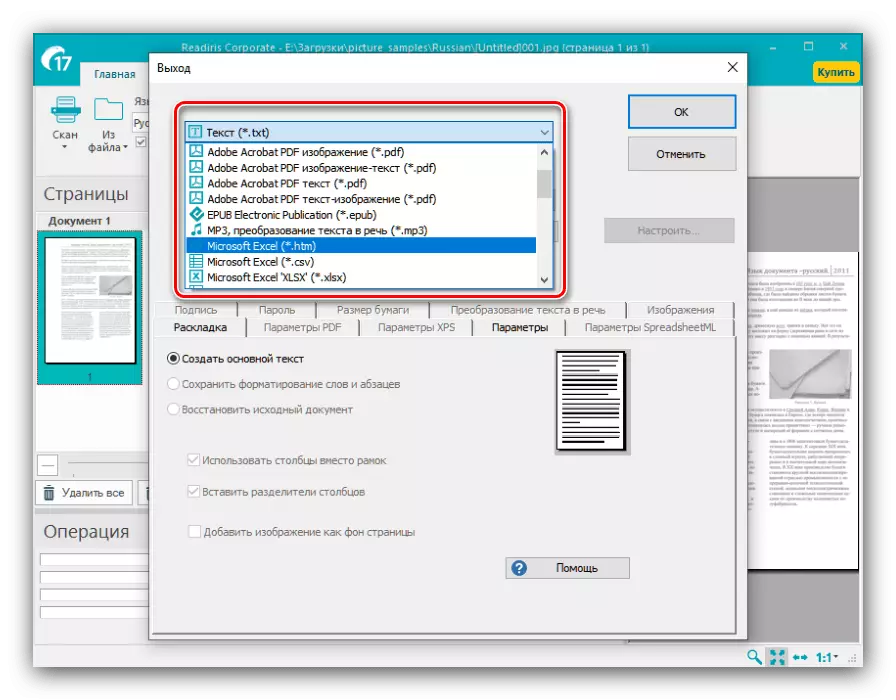
- 在更改识别的文本后,通过工具栏上的相同名称的菜单中设置的接收数据的输出格式。主要格式被认为是PDF,以及Microsoft Office文件(DOCX和XLSX) - 单击所需位置来选择。
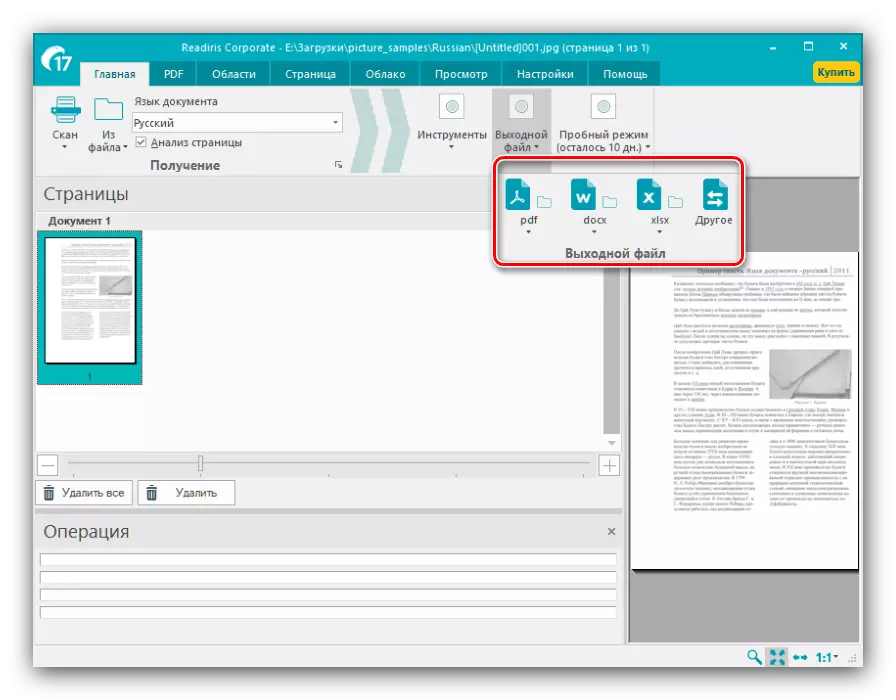
所有可能的导出格式都在“其他”段落中分组。除上面提到的文件类型的类型外,数字化文本还可以保存为OpenOffice数据,超文本文件或普通TXT。
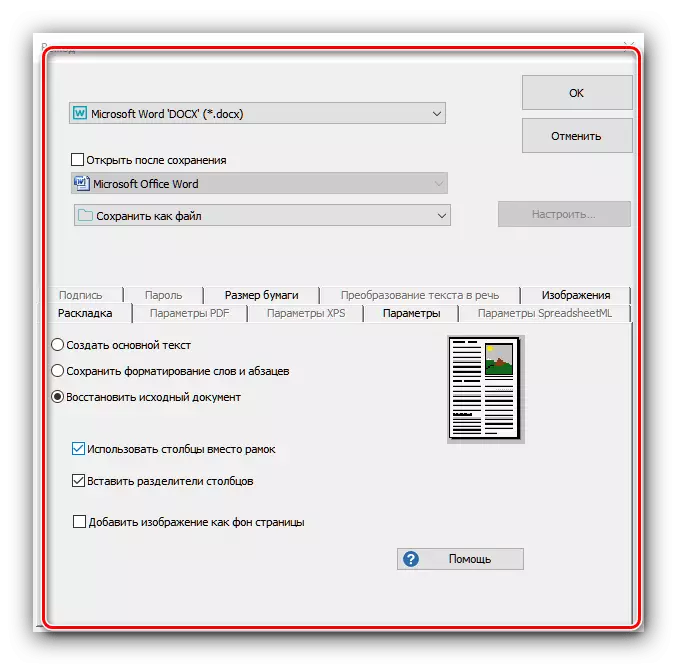
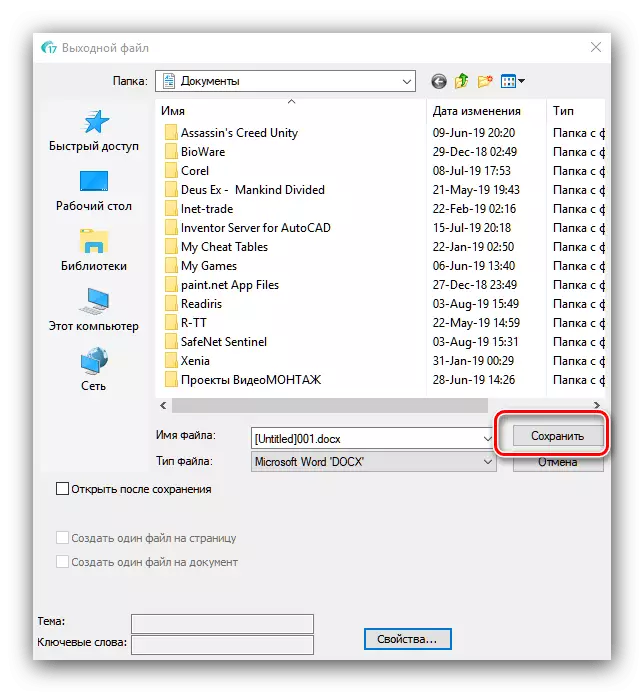
- 选择格式后,将打开“导出向导”窗口。在其中,您可以配置接收文件的一个或其他参数(取决于所选格式)和保存选项(本地或云服务)。完成所有必需的更改后,单击“确定”。
将再次出现“Explorer”窗口,您应该选择所需的目标保存目录。
通常,Readiris是一种方便而现代化的数字化文本的解决方案,但是,可以称为显着的分布模型。
方法3:Ridoc
但是,另一个专注于扫描仪,但可以使用不同格式的本地文件。
- 打开申请。要启动,请使用工具栏上的“打开”或“扫描仪”按钮 - 第一个负责识别本地文件中的文本,第二个允许您使用扫描同时启动数字化。例如,我们将使用第一个选项。
- 在“Explorer”窗口中,转到要从中获取文本并选择它的文档。还提供文档的批处理。
- 如果需要,可以处理结果文件:修剪图片,设置识别区域,修复扫描的漏洞。
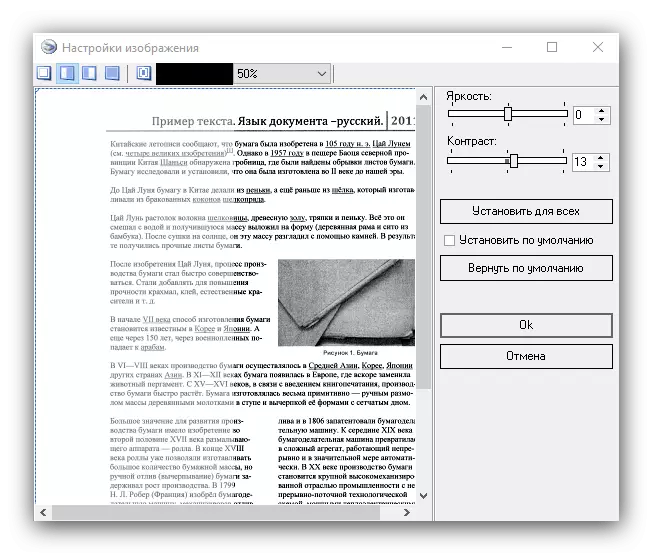
一个单独的项目是胶合的可能性 - 在这种情况下,multistagon文件将通过一个单一的文件进行保存。您可以选择DPI值和输出格式(仅可用图像文件)。
- 要识别窗口右侧的文本,请找到OCR选项卡并打开它。没有许多可用选项 - 您只能选择文档语言。更改包后,单击工具栏上的“识别”按钮。
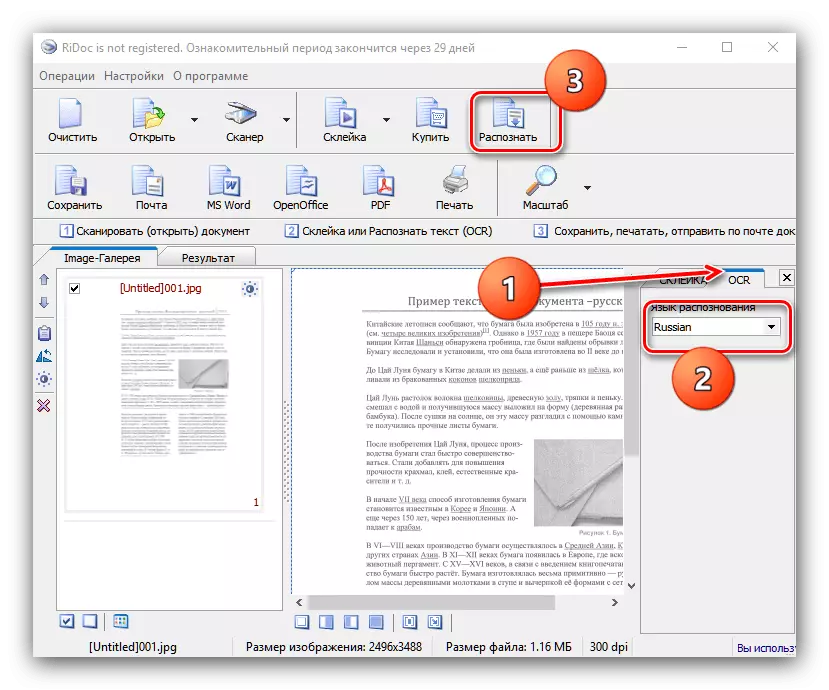
从这里您还可以调整数字化的结果。
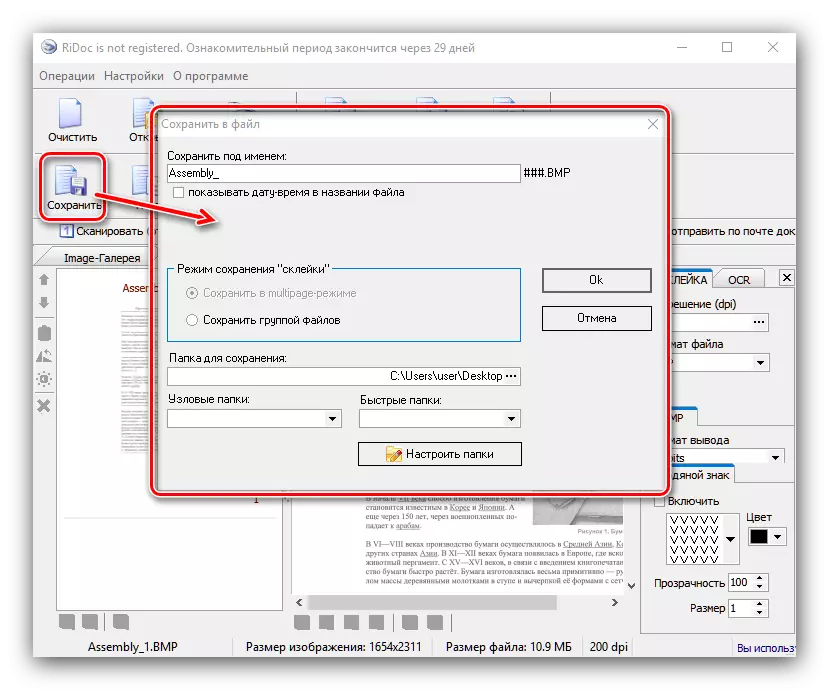
- 保存两个选项中可用的文档 - 直接或导出到Office应用程序。要执行第一个方法,请使用“保存”按钮。将打开一个窗口,您可以在其中选择保存的位置,以及类型(单个文件或一个多锁相单)。存储文件的格式取决于在舞台上选择的胶合。
Microsoft或OpenOffice Office Packages的文本处理器中可能是可能的,作为电子邮件(邮件按钮),PDF格式或打印机上的打印。要导出到Office程序,即使没有适当的应用程序,也必须安装在计算机上,同时保持PDF。

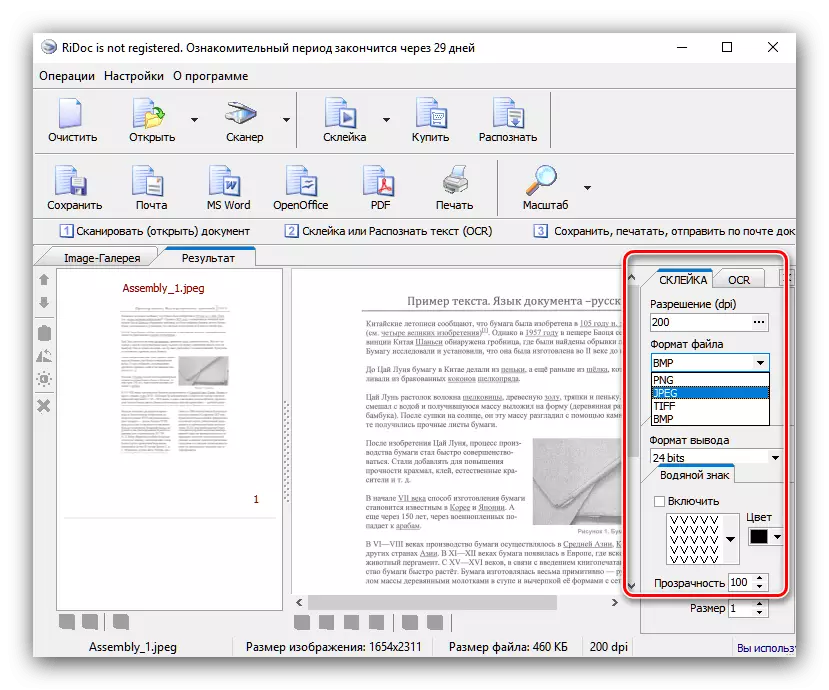
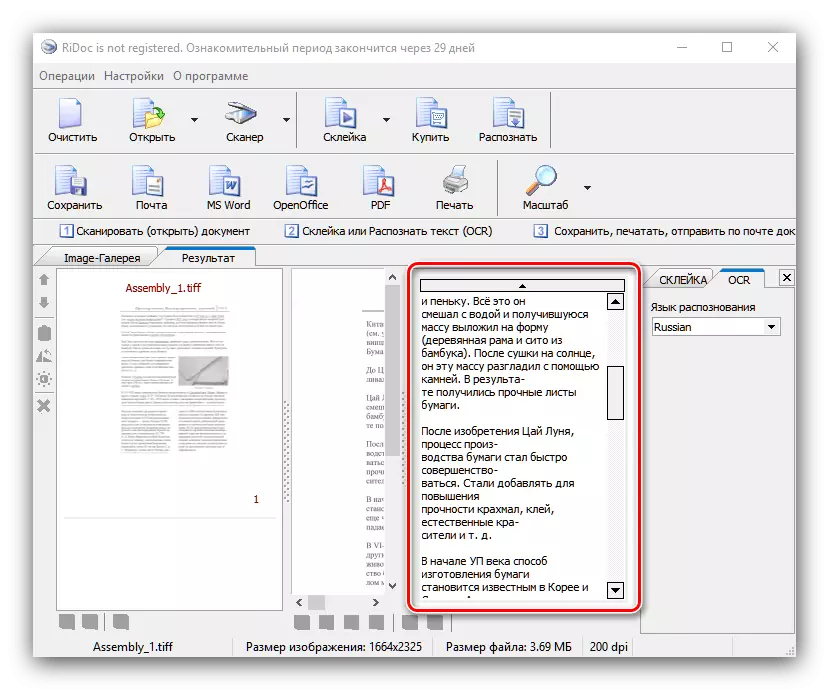
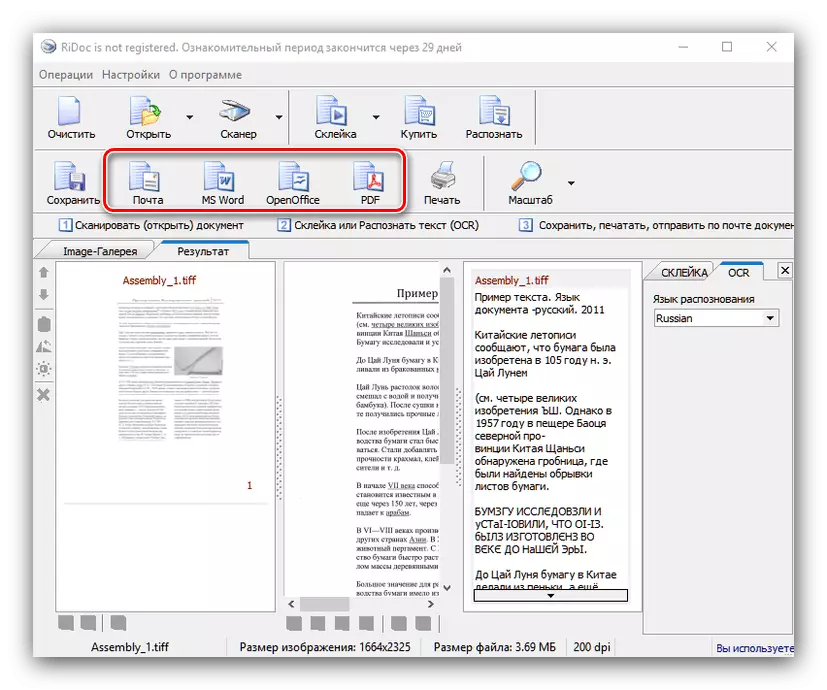
正如我们所看到的,谜语是一个强大的决定,但对于简单的变体,数字化非常适合。
方法4:Capture2Text
一个小实用程序,允许您从计算机屏幕上的任何区域识别文本,完全免费且易于使用。
从官方网站下载Capture2Text
- 使用程序加载存档并在任何方便的地方解压缩它。然后转到获取的目录并运行可执行文件。

接下来,打开系统托盘 - 实用程序图标应出现在其中。
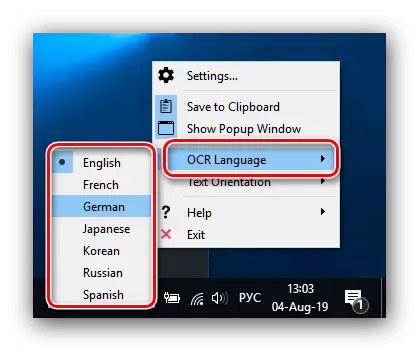
要改变识别语言,在系统托盘中的Capture2Text图标上单击右键,然后在设置中选择“OCR语言”,并设置所需的语言。
- 打开文件,要从中键入的文本,例如,文档DJVU没有文本图层。当文件打开时,按WIN + Q键组合并选择识别区域。
- 实用程序窗口将显示识别结果。所获得的数据可以复制到支持键入用户文本的任何应用程序。
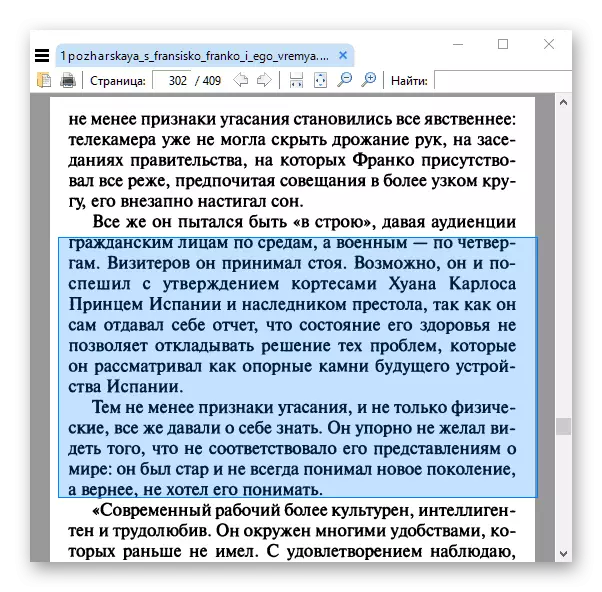
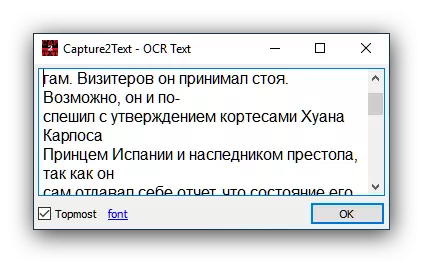
应用程序非常简单,但它变成了有限的功能,有时候,俄语文本的错误识别不正确。同样为缺点,我们可以将缺乏本地化归因于俄语。然而,对于一些用户来说,这些减数是微不足道的,主要的可能性就足够了。
方法5:楔形状
另一种决定将在苏联后空间中创建的文本进行数字化。尽管发展存在停止,但仍然是相关的。
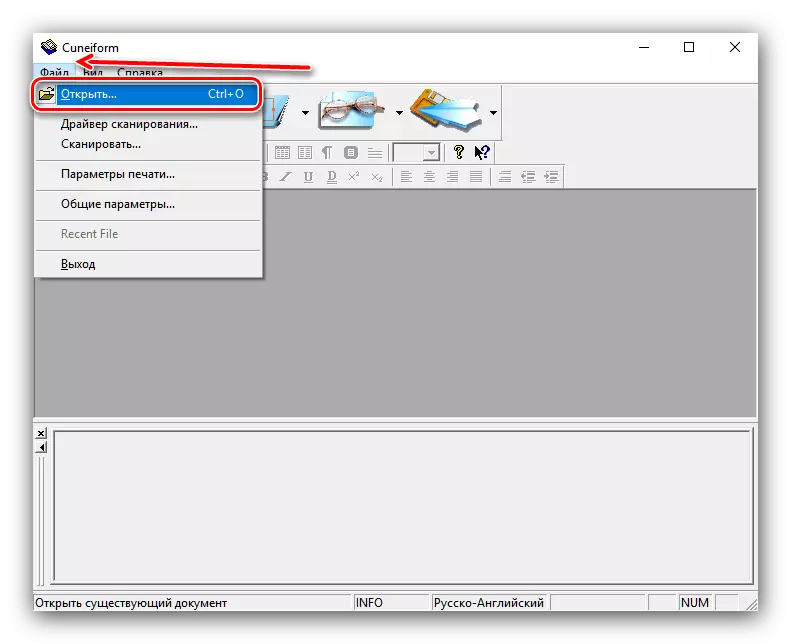
- 喜欢这篇文章中提出了许多其他程序,Kuneform知道如何与这两个现成图像的工作,并直接从扫描仪接收数据。我们用第一个选项 - 要做到这一点,打开“文件”菜单,然后选择打开项目。
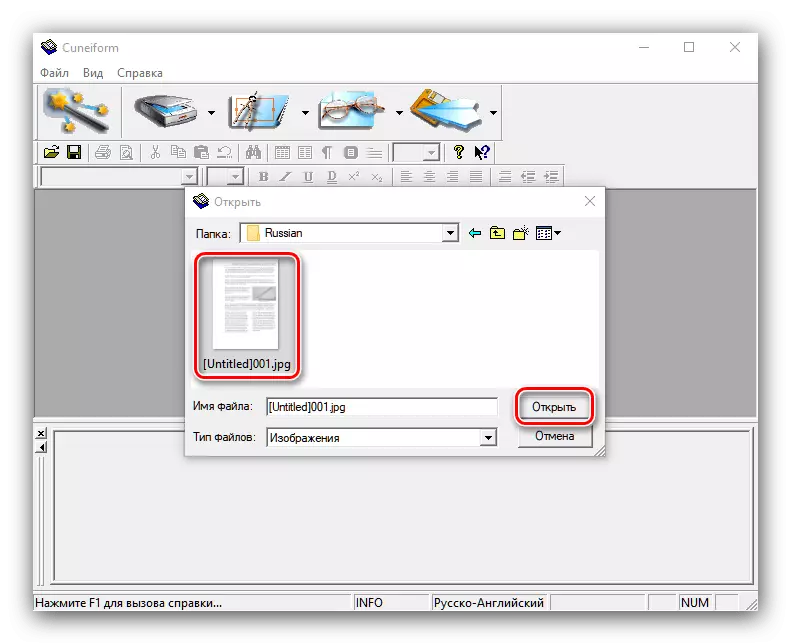
- 通过“资源管理器”,选择需要的文件或文件。
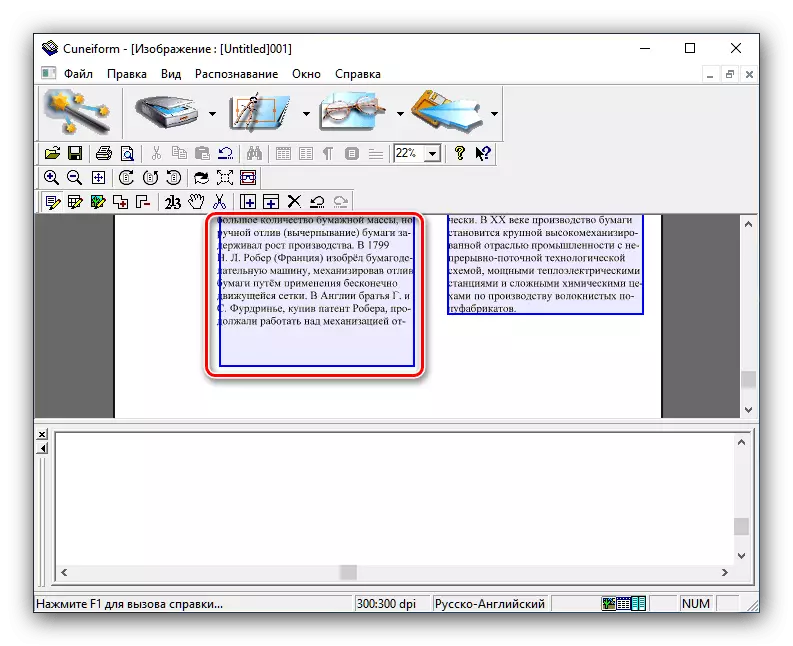
- 数据下载到程序后,使用“承认”项目 - “AutoSmetic”。

这将允许您使用文本的OCR模块的更正确的操作选择区域。如果自动算法错误地规定的页面,文本区域可以手动控制或除去。
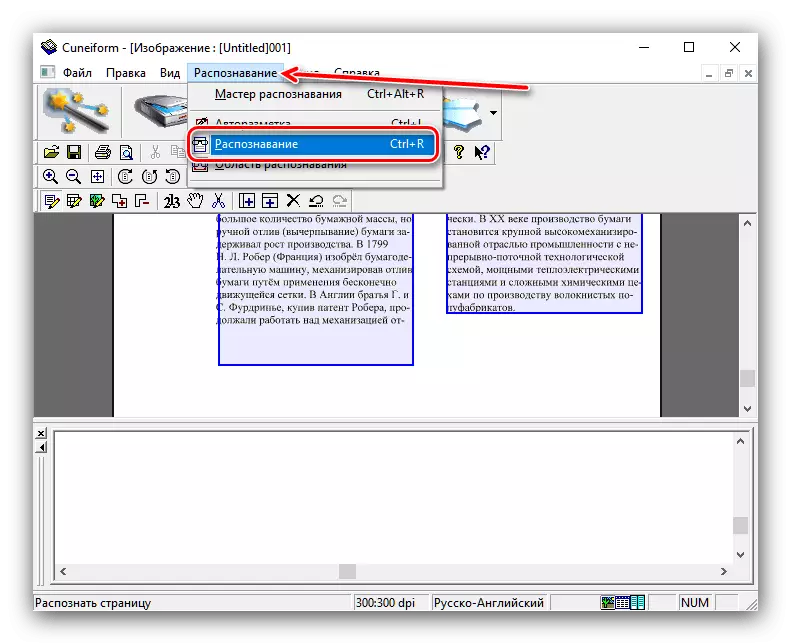
- 接下来,您可以通过数字化的直接参与。再次打开“识别”菜单,然后选择具有相同名称的选项。
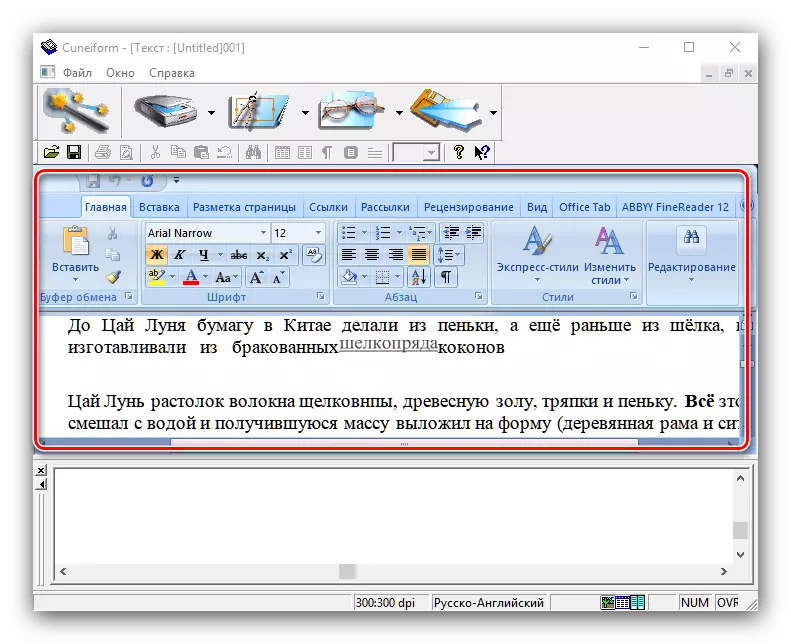
- 该识别的文本将在应用程序窗口,在这里还可以编辑被打开。特点是非常广泛,并对应于一个完整的文本编辑器。如果安装在计算机上的MS Word,所获得的数据将通过其接口打开。
- 保存工作成果的“文件”项可用 - “保存”。

在“资源管理器”,选择接收的文件及其格式的位置。没有多少选择的支持:TXT,RTF,内部FED格式,以及出口到Microsoft Office(Word和Excel)的应用。
正如你所看到的,楔形文字是一个简单的,并在同一时间,数字化文本的有力工具。重量上的优势将成为自由分布模型,然而,在支持的终止以及缺乏一个PDF格式的形式的缺点可能会导致应用到替代品。
结论
正如你所看到的,认识到从图片文字是如果你使用这个专门的应用程序很简单。此过程不会从你需要很大的努力,而且收益就会非常节省时间。