Metóda 1: Používanie automatického nástroja
Excel má automatický nástroj určený na rozdelenie textu v stĺpcoch. Nepracuje automaticky, takže všetky akcie sa budú musieť vykonať manuálne, výberom rozsahu spracovaných údajov. Nastavenie je však najjednoduchšie a rýchle pri implementácii.
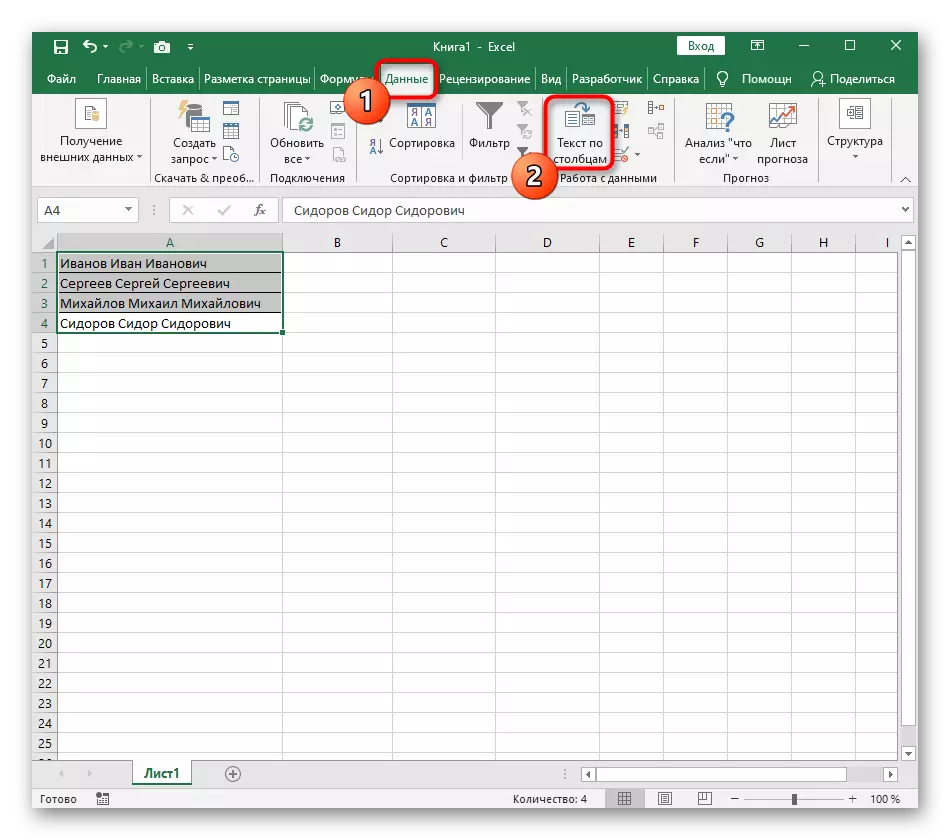
- Pomocou ľavého tlačidla myši vyberte všetky bunky, ktorých text chcete rozdeliť na stĺpci.
- Potom prejdite na kartu "Údaje" a kliknite na tlačidlo "Text a stĺpec".
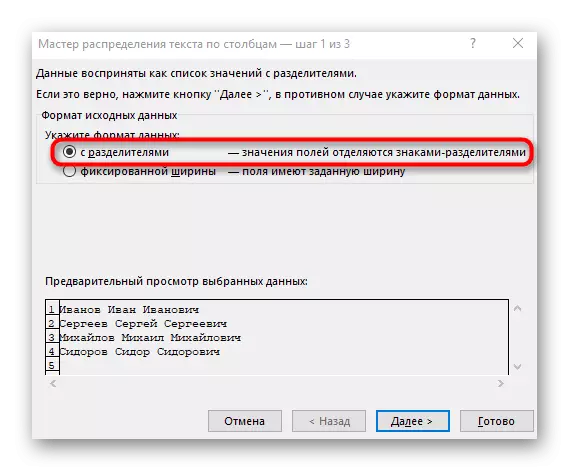
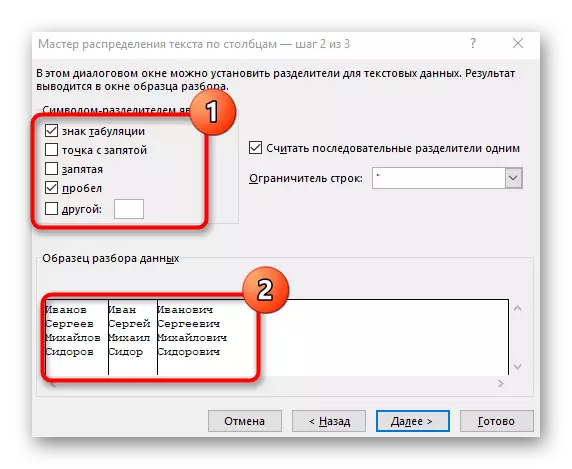
- Zobrazí sa okno "Stĺpcový text Wizard", v ktorom chcete vybrať formát údajov "so separátormi". Oddeľovač najčastejšie vykonáva priestor, ale ak je to iné interpunkčné znamenie, budete musieť zadať v nasledujúcom kroku.
- Zaškrtnite kontrolu sekvencie alebo manuálne zadajte ho a potom si prečítajte predbežný výsledok separácie v okne nižšie.
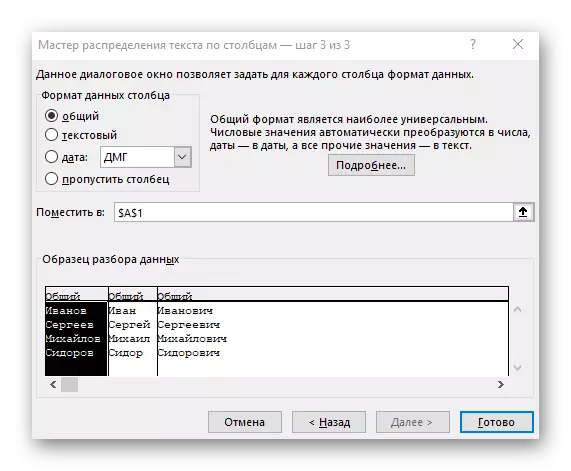
- V poslednom kroku môžete zadať nový formát stĺpca a miesto, kde musia byť umiestnené. Akonáhle je nastavenie dokončené, kliknite na tlačidlo "Dokončiť", ak chcete použiť všetky zmeny.
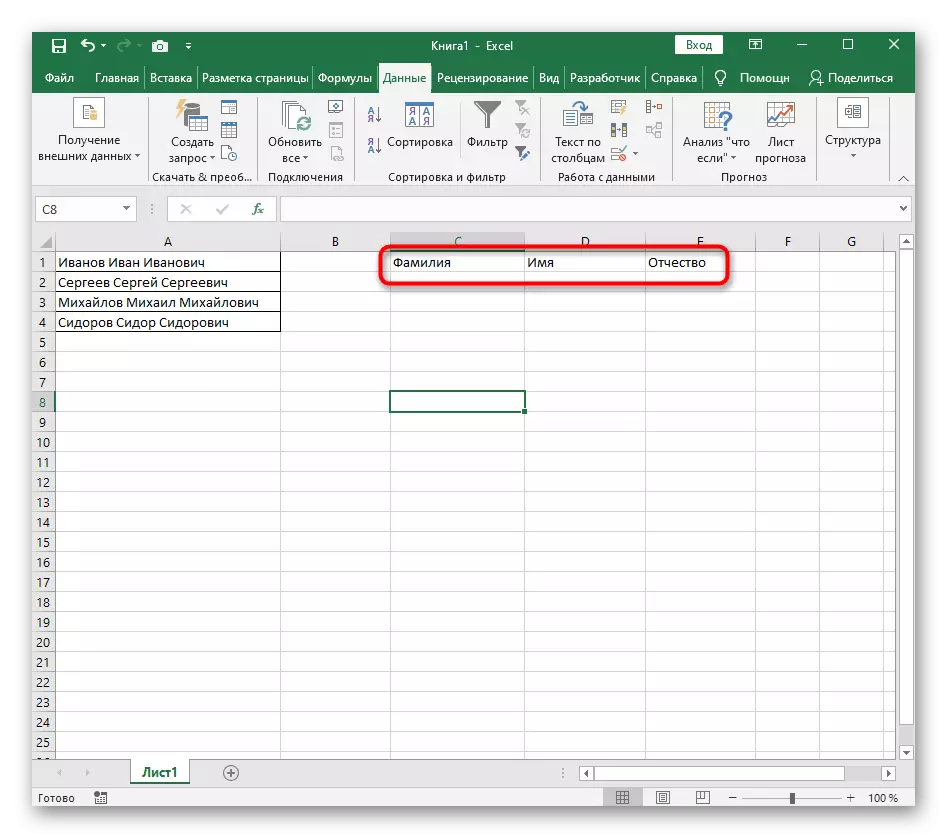
- Návrat do tabuľky a uistite sa, že oddelenie úspešne prešlo.


Z tohto pokynu môžeme dospieť k záveru, že použitie takéhoto nástroja je optimálne v tých situáciách, keď sa oddelenie musí vykonávať len raz, označuje každé slovo nový stĺpec. Avšak, ak sú nové údaje neustále zavedené do tabuľky, po celú dobu, keď ich rozdeľuje, takto nie je úplne pohodlné, takže v takýchto prípadoch odporúčame zoznámiť sa s ním nasledujúcim spôsobom.
Metóda 2: Vytvorenie textového rozdelenia textu
V programe Excel môžete samostatne vytvoriť relatívne komplexný vzorec, ktorý vám umožní vypočítať polohy slov v bunke, nájsť medzery a rozdeliť každý do samostatných stĺpcov. Ako príklad budeme mať bunku pozostávajúcu z troch slov oddelených medzerami. Pre každého z nich to urobí svoj vlastný vzorec, preto rozdelíme metódu do troch etáp.Krok 1: Oddelenie prvého slova
Vzorec pre prvé slovo je najjednoduchšie, pretože to bude musieť byť odpudzované len z jednej medzery, aby ste určili správnu pozíciu. Zvážte každý krok svojho stvorenia, takže kompletný vytvorený obraz je dôvod, prečo sú potrebné určité výpočty.
- Pre pohodlie vytvorte tri nové stĺpce so podpismi, kde pridáme oddelený text. Tento moment môžete urobiť to isté alebo preskočiť.
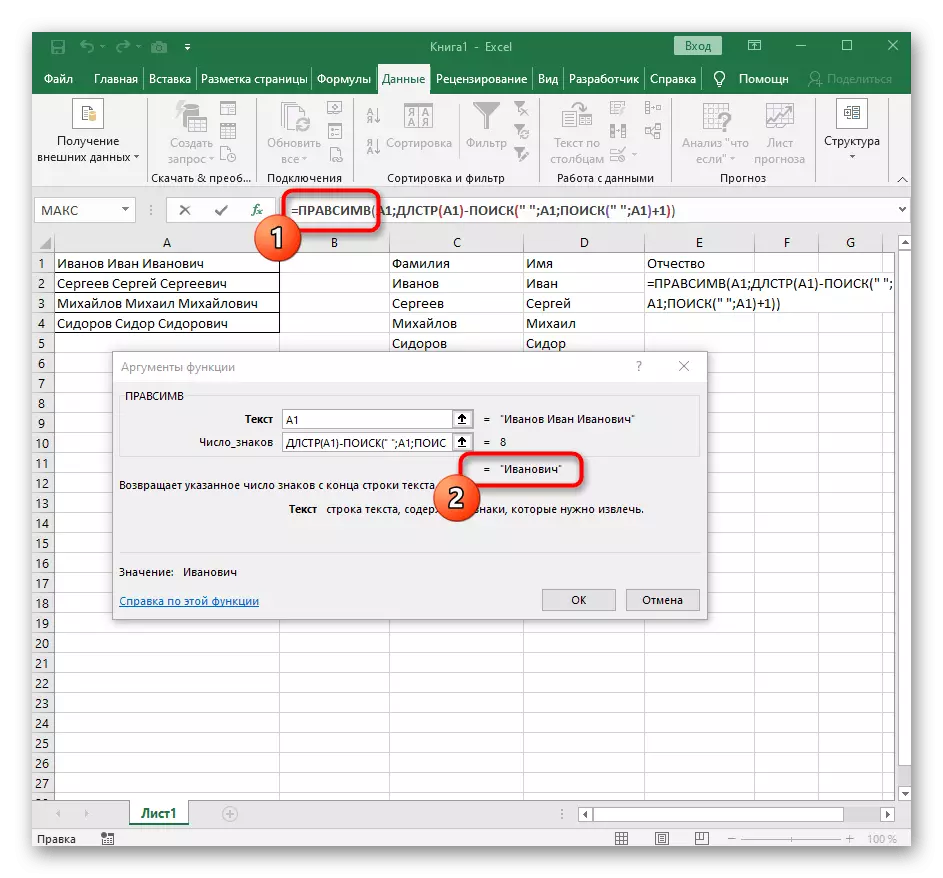
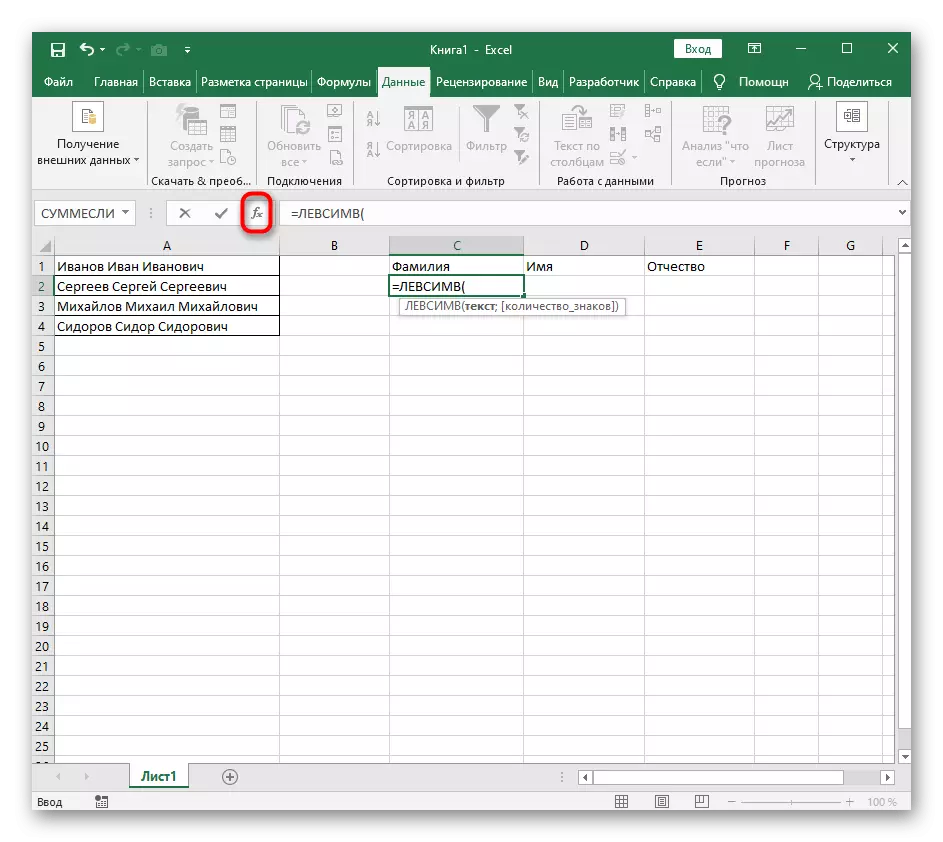
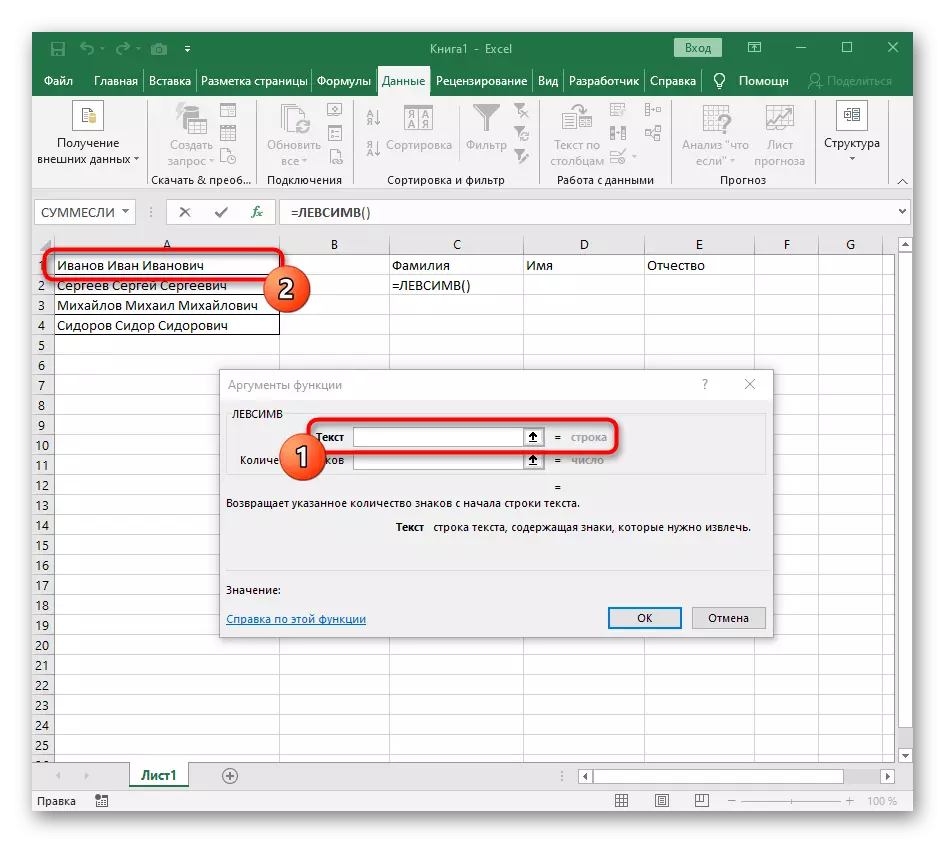
- Vyberte bunku, do ktorej chcete umiestniť prvé slovo a zapíšte si vzorca = LessMV (.
- Potom stlačte tlačidlo "OPTION ARGUMENTY", čím sa presuniete do okna grafického editovania vzorca.
- Ako text argumentu, špecifikujte bunku s nápisom kliknutím na neho ľavým tlačidlom myši na stole.
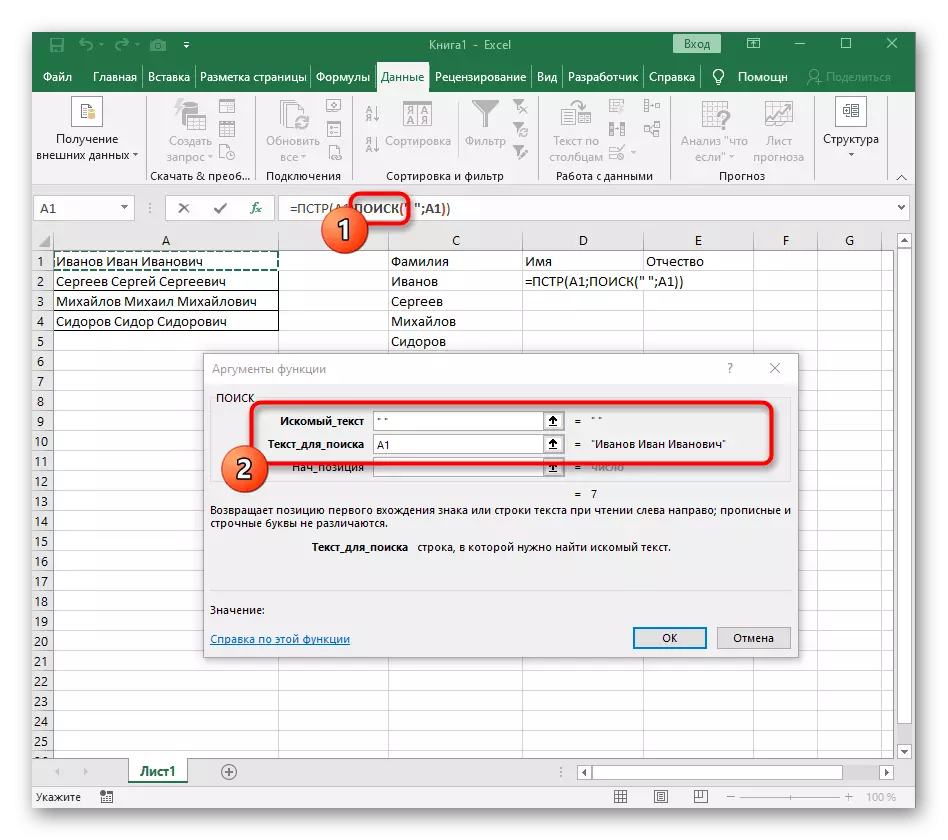
- Počet označení do priestoru alebo iného oddeľovača bude musieť vypočítať, ale ručne to neurobíme, ale použijeme inú vzorcu - vyhľadávanie ().
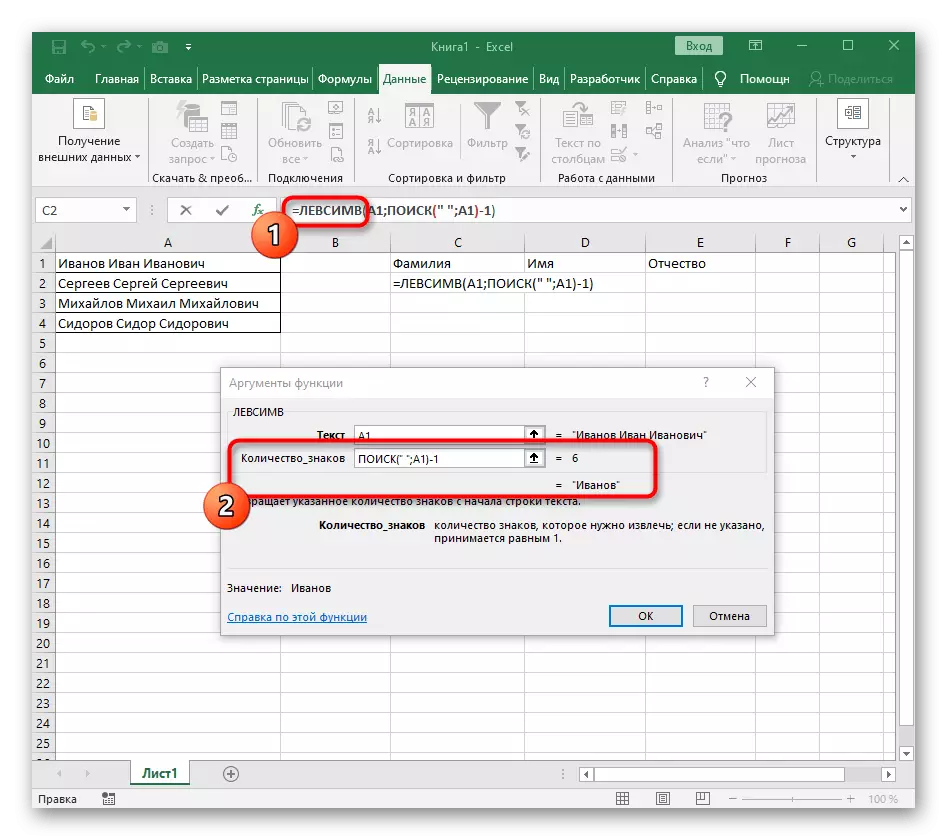
- Akonáhle to nahráte v takomto formáte, zobrazí sa v texte bunky na vrchole a bude zvýraznený tučným písmom. Kliknite naň, aby ste rýchlo prešli na argumenty tejto funkcie.
- V poli "Skeleton" jednoducho položte priestor alebo separátor použitý, pretože vám pomôže pochopiť, kde sa slovo končí. V "Text_-search" zadajte spracúvanú bunku.
- Kliknutím na prvú funkciu sa vrátite na ňu a pridajte na konci druhého argumentu -1. Toto je potrebné, aby sa vyhľadávacia receptor zohľadnila, že nie je požadovaný priestor, ale symbol. Ako je možné vidieť v nasledujúcej snímke, výsledok sa zobrazí bez akýchkoľvek miest, čo znamená, že kompilácia vzorca je vykonaná správne.
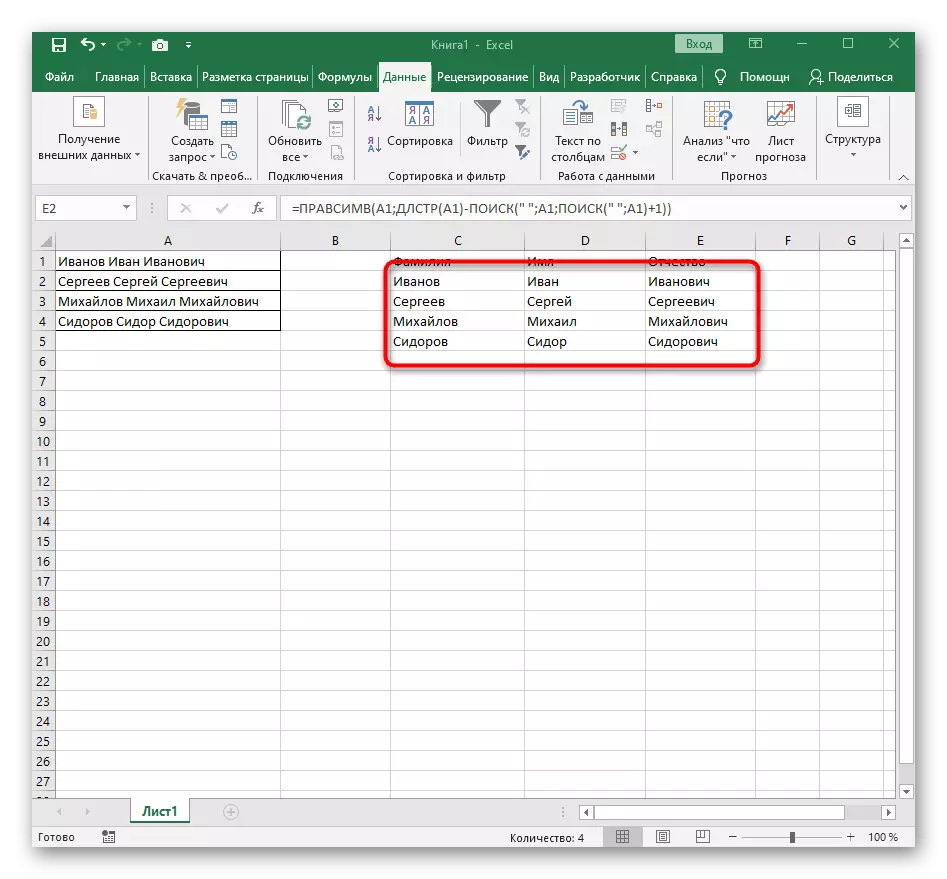
- Zatvorte editor funkcií a uistite sa, že slovo je správne zobrazené v novej bunke.
- Držte bunku v pravom dolnom rohu a potiahnite ho na požadovaný počet riadkov. Takže hodnoty iných výrazov sú substituované, ktoré musia byť rozdelené a naplnenie vzorca je automaticky.




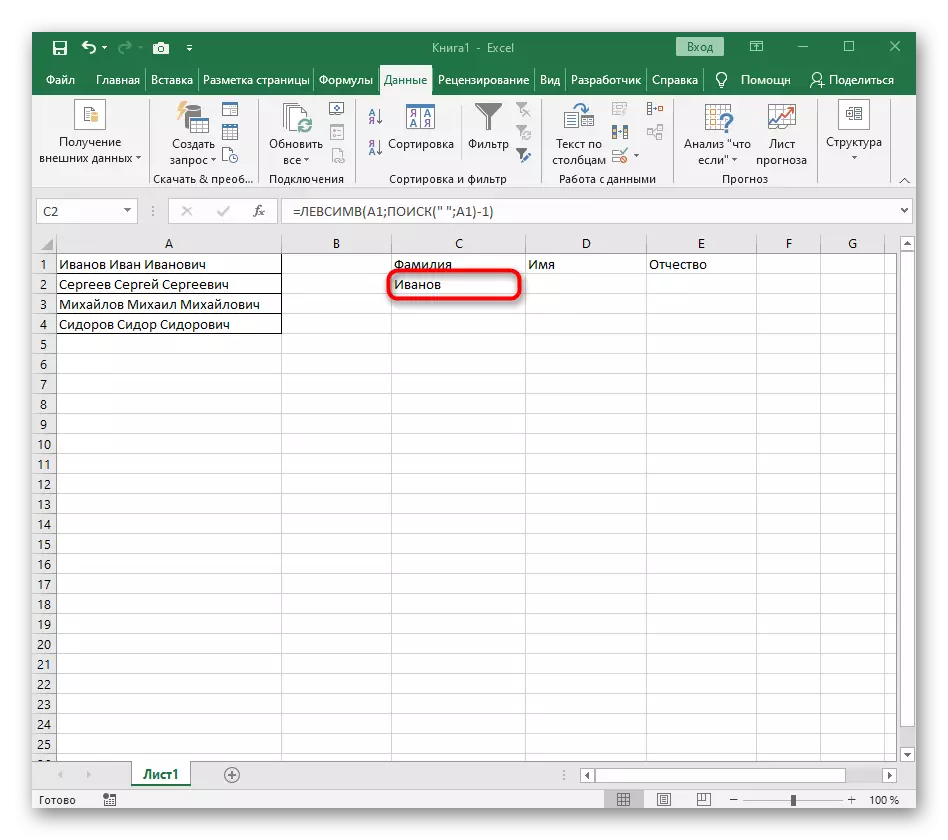

Plne vytvorený vzorec má formulár = Levsimv (A1; Hľadať ("", A1) -1), môžete ho vytvoriť podľa vyššie uvedených pokynov alebo vložiť toto, ak sú vhodné podmienky a separátor. Nezabudnite nahradiť spracovanú bunku.
Krok 2: Oddelenie druhého slova
Najťažšie je rozdeliť druhé slovo, ktoré je v našom prípade meno. Je to spôsobené tým, že je obklopený medzerami z oboch strán, takže budete musieť brať do úvahy oboje, vytvoriť masívny vzorec pre správny výpočet pozície.
- V tomto prípade bude hlavný vzorec = PST (- zapíšte ho v tomto formulári a potom prejdite do okna Nastavenia argumentu.
- Tento vzorec bude vyhľadávať požadovaný reťazec v texte, ktorý je vybraný bunkou s nápisom na separáciu.
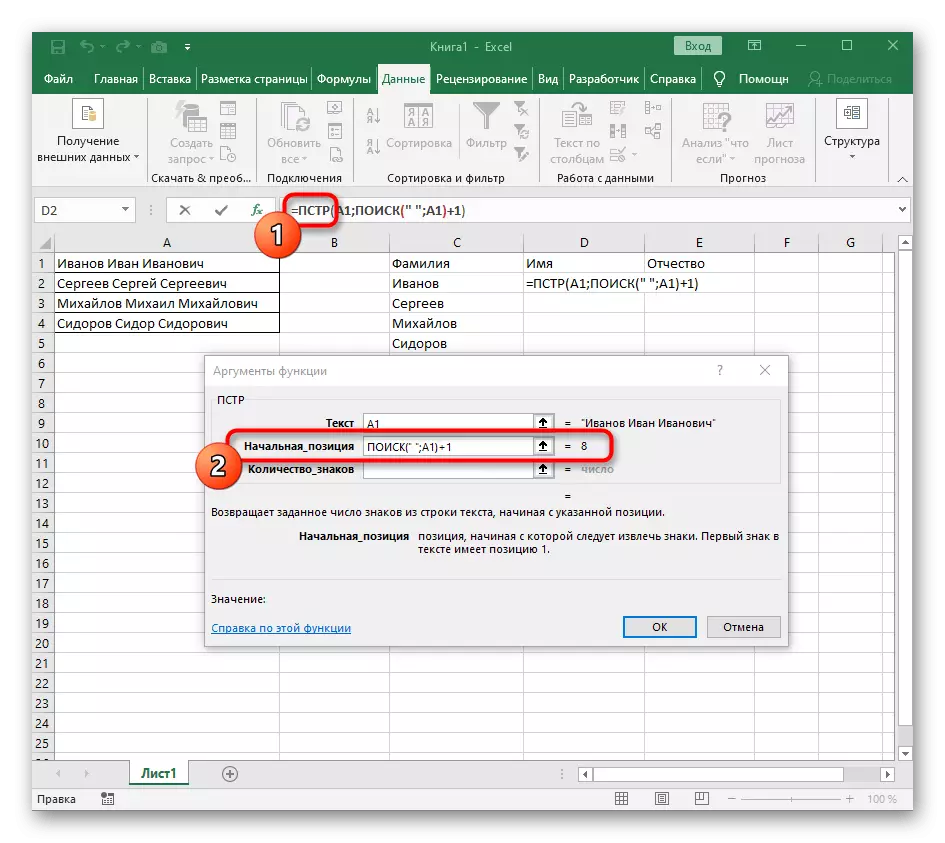
- Počiatočná poloha čiary sa bude musieť určiť pomocou už známej pomocného vyhľadávania vzorca ().
- Vytvorenie a pohyb smerom k nemu, vyplňte rovnakým spôsobom, ako bolo uvedené v predchádzajúcom kroku. Ako požadovaný text použite separátor a zadajte bunku ako text na vyhľadávanie.
- Vráťte sa na predchádzajúci vzorec, kde pridajte do funkcie "Hľadať" +1 na konci, aby ste spustili účet z nasledujúceho charakteru po zistenom priestore.
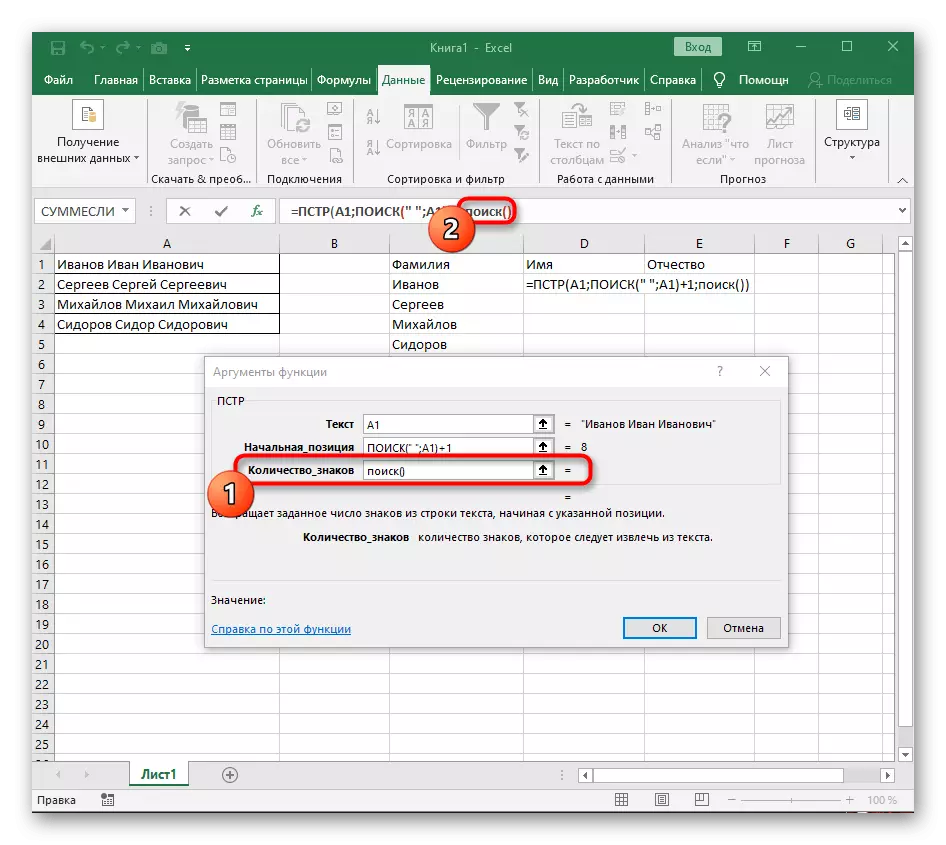
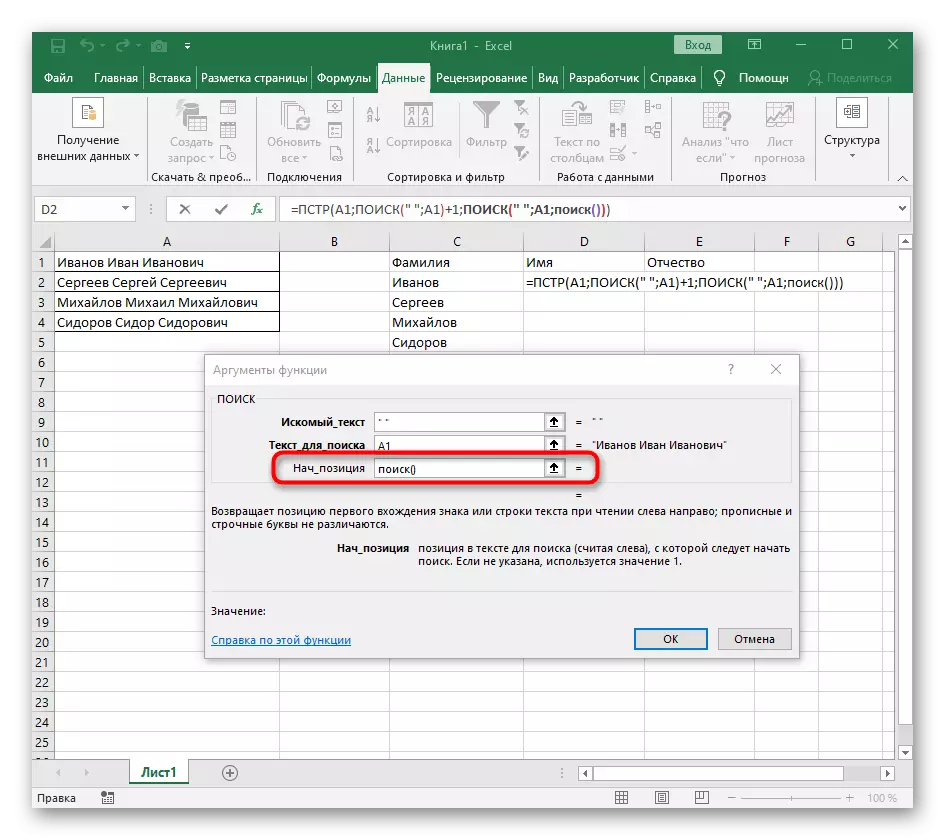
- TERAZ FORMULÁR TERAZ môže začať hľadať riadok z prvého názvu znaku, ale stále nevie, kde dokončiť ho, preto v poli "Množstvo_names" opäť napíšte vyhľadávacie vzorca ().
- Choďte na svoje argumenty a naplňte ich v už známej forme.
- Predtým sme nepovažovali počiatočnú pozíciu tejto funkcie, ale teraz je potrebné zadať vyhľadávanie (), pretože tento vzorec by nemal nájsť prvú medzeru, ale druhý.
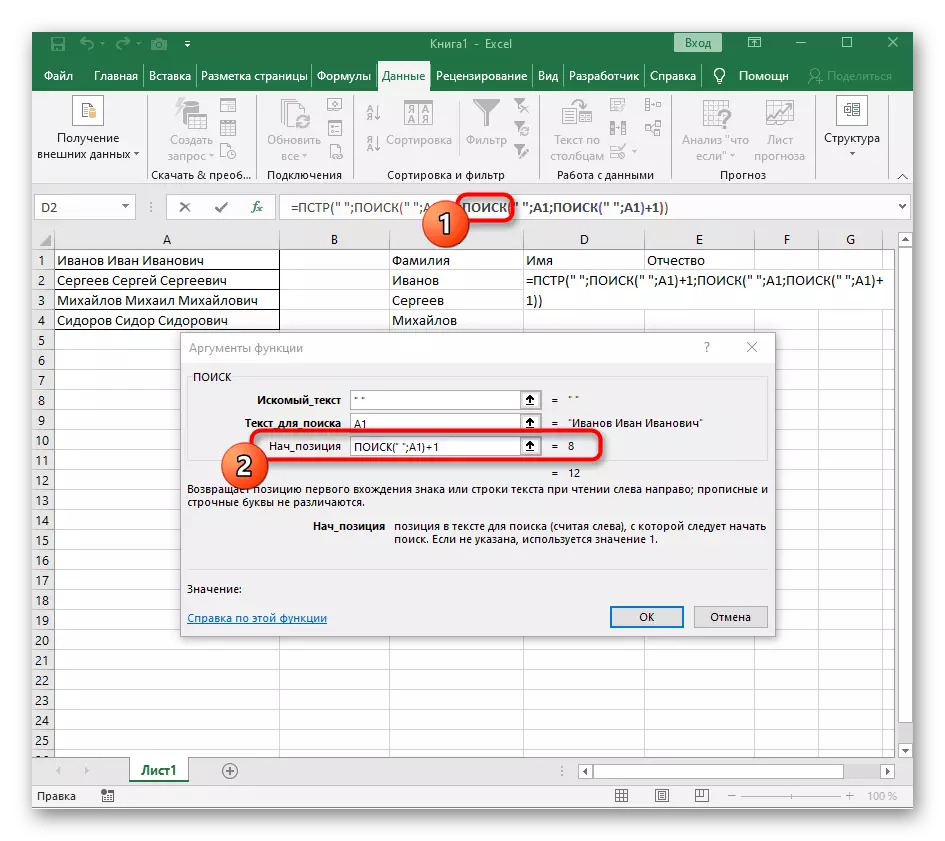
- Prejdite na vytvorenú funkciu a vyplňte ho rovnakým spôsobom.
- Vráťte sa na prvé "vyhľadávanie" a pridajte na konci "Nach_Position" +1 na konci, pretože nepotrebuje priestor na vyhľadávanie na riadku, ale nasledujúci znak.
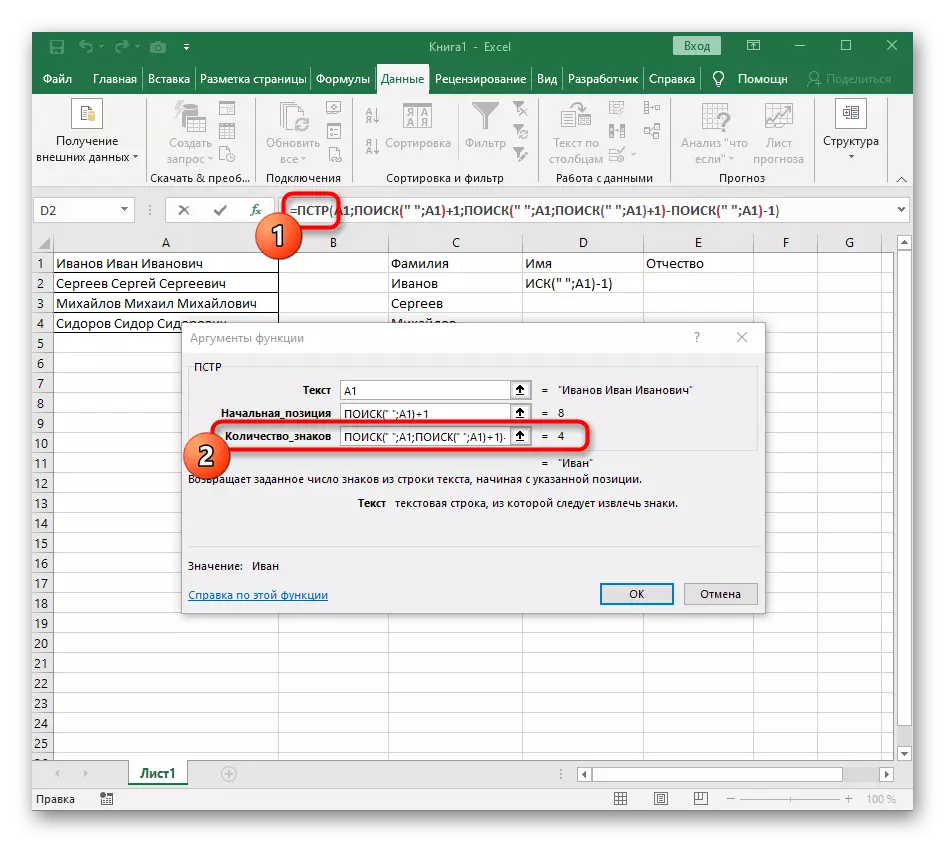
- Kliknite na koreň = PST a vložte kurzor na konci riadku "Number_names".
- Extrahovať expresiu výrazu ("" A1) -1 na dokončenie výpočtov medzier.
- Vráťte sa na tabuľku, roztiahnite vzorec a uistite sa, že sa slová zobrazia správne.


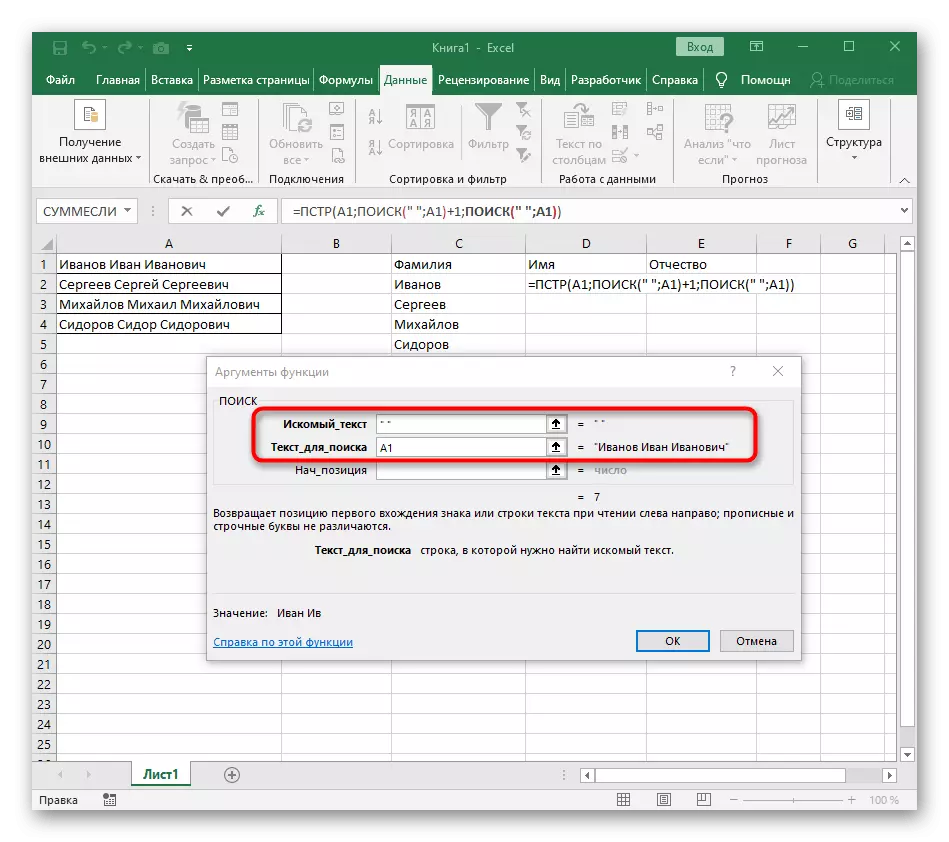

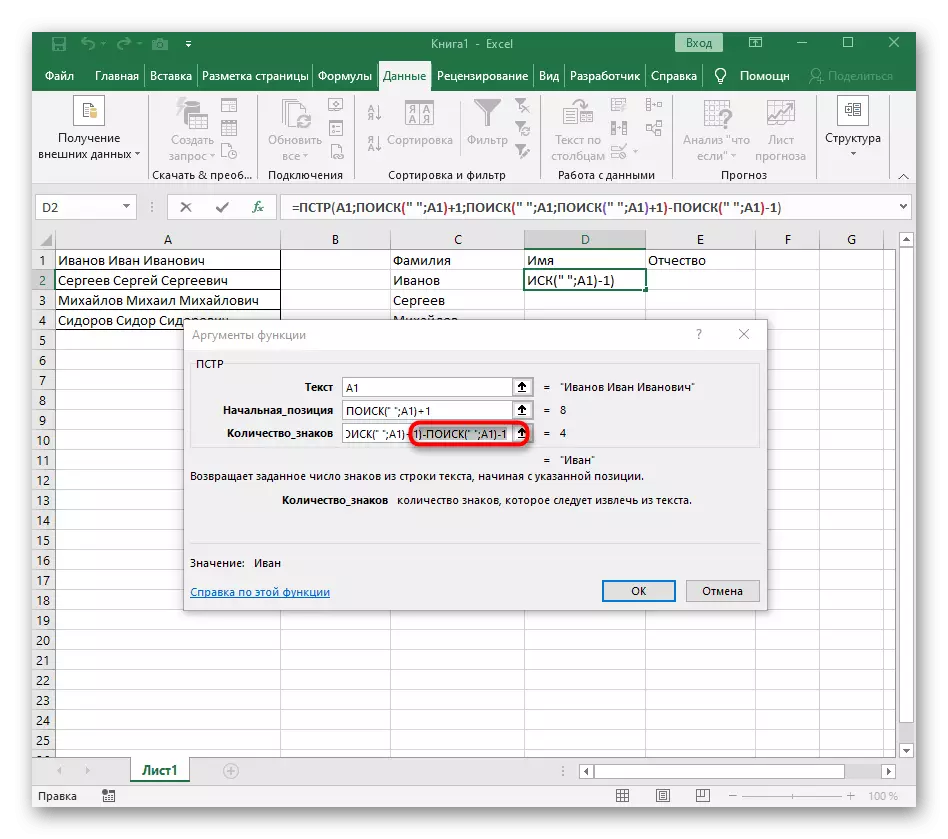
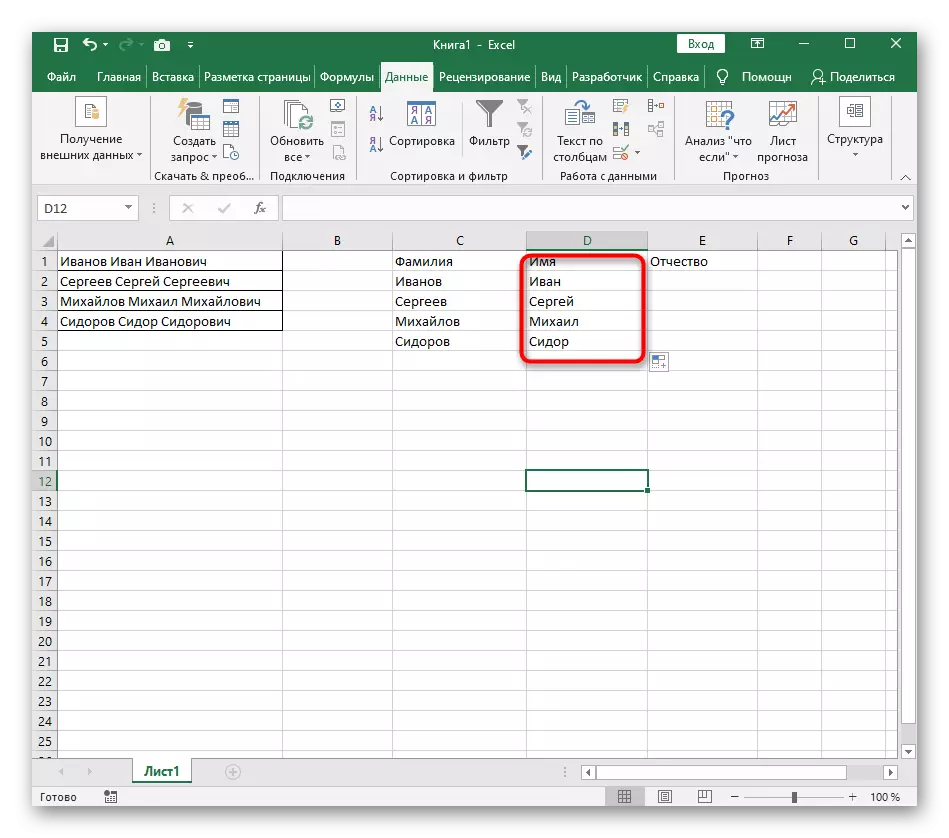
Vzorec sa ukázal, a nie všetci používatelia presne pochopia, ako to funguje. Faktom je, že hľadať líniu, ktorú som musel použiť niekoľko funkcií, ktoré určujú počiatočné a konečné polohy medzier, a potom jeden symbol odobral od nich tak, že v dôsledku toho boli tieto väčšiny medzier zobrazená. Výsledkom je, že vzorec je tento: = pst (A1; hľadanie (""; A1) +1; hľadanie (""; A1; Hľadať (""; A1) +1) -POIZK (""; A1) - 1). Použite ho ako príklad, nahradenie čísla buniek textom.
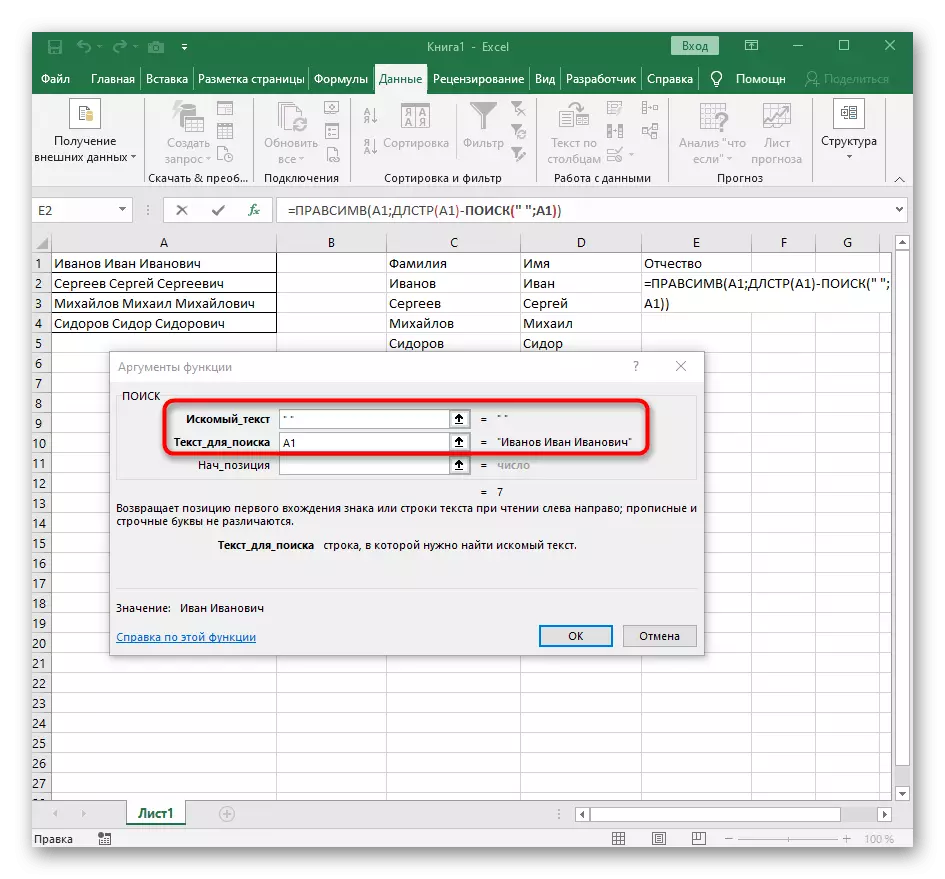
Krok 3: Oddelenie tretieho slova
Posledným krokom nášho inštrukcie znamená rozdelenie tretieho slova, ktoré vyzerá rovnako, ako sa to stalo s prvým, ale všeobecný vzorca sa mierne zmení.
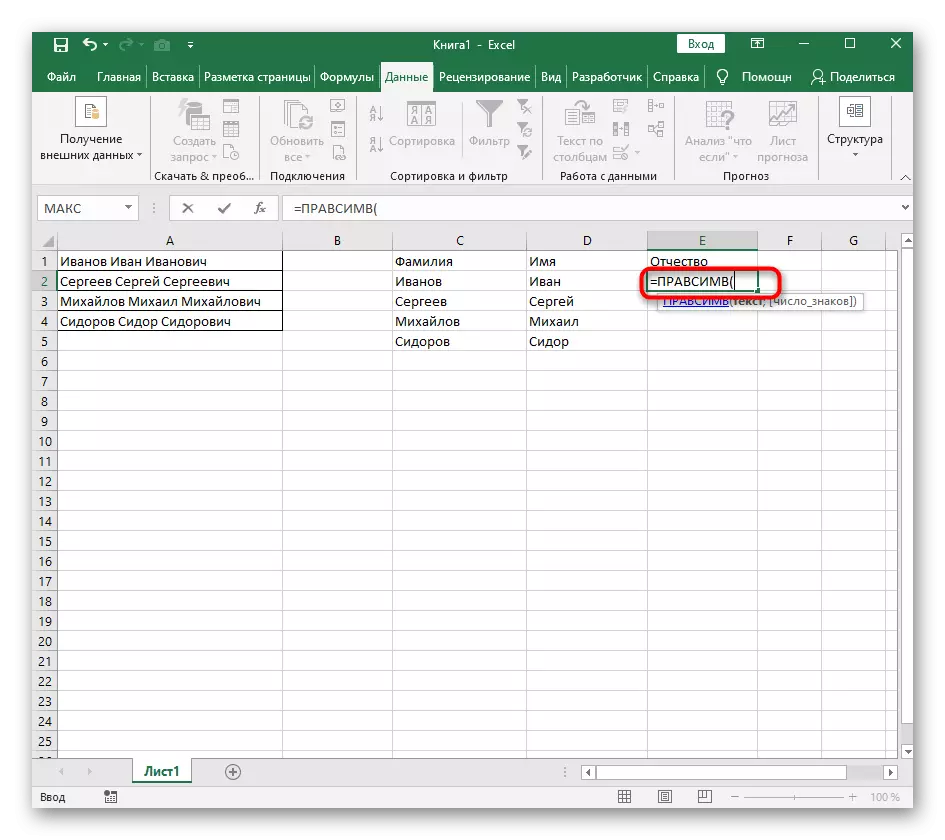
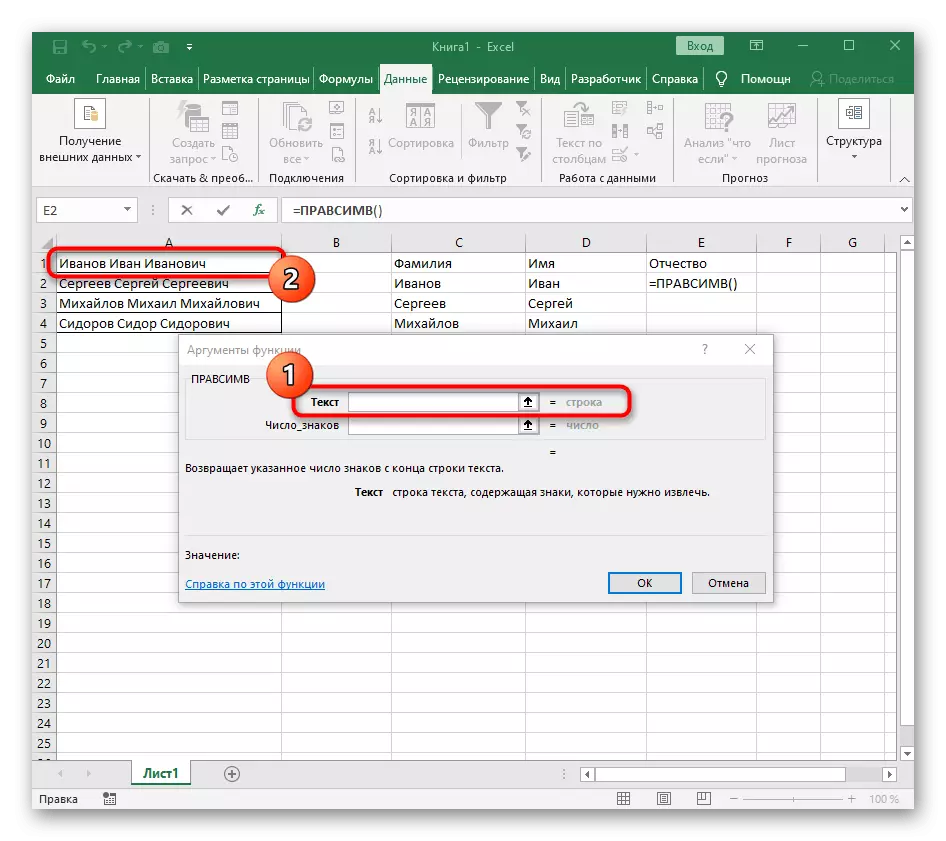
- V prázdnej bunke, pre umiestnenie budúceho textu, zápis = Rashesimv (a prejdite na argumenty tejto funkcie.
- Ako text špecifikujte bunku s nápisom na separáciu.
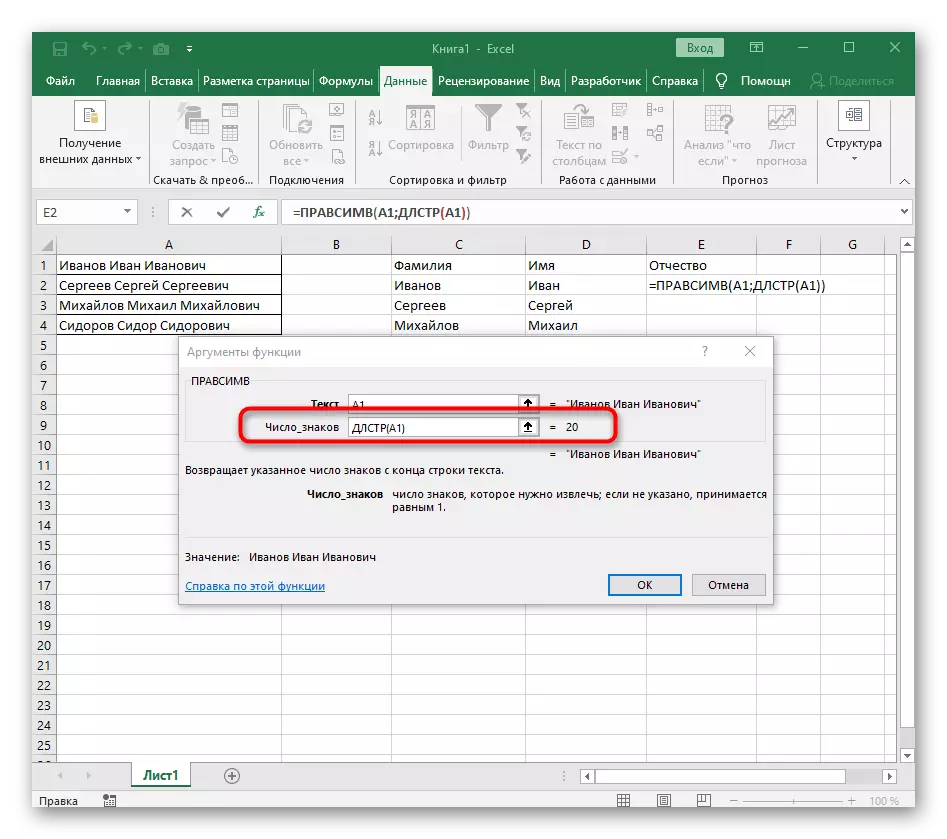
- Tentokrát pomocná funkcia pre nájdenie slova sa nazýva DLSTR (A1), kde A1 je rovnaká bunka s textom. Táto funkcia určuje počet znakov v texte a zostaneme len vhodný.
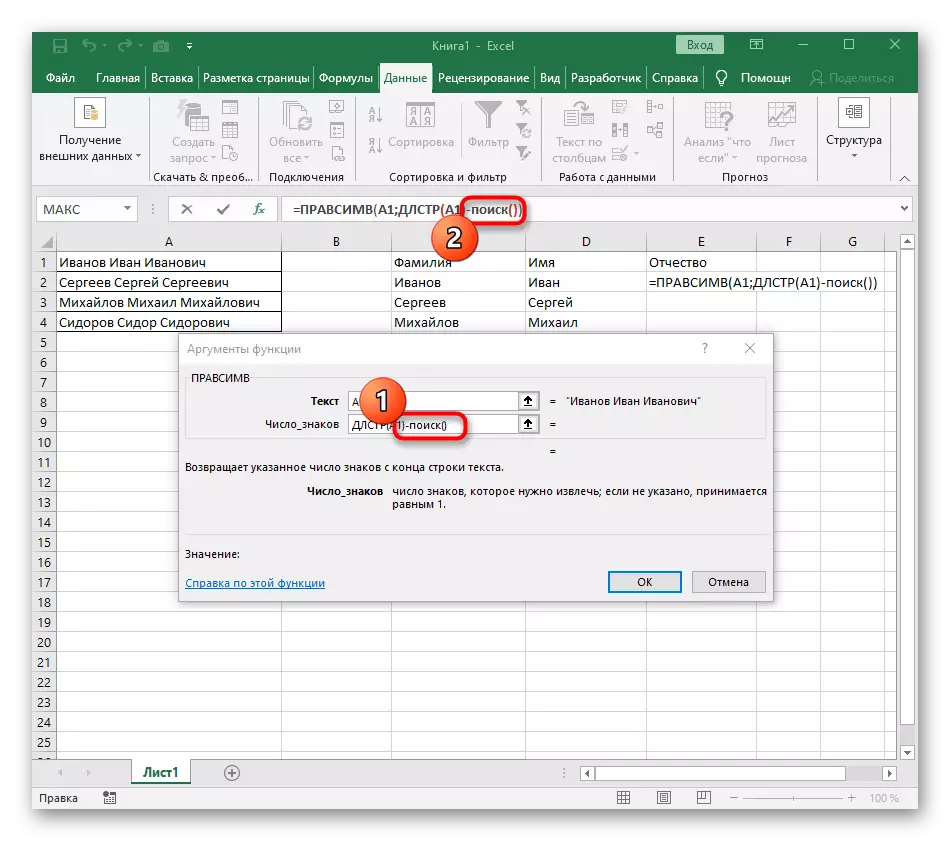
- Ak to chcete urobiť, pridajte -poisk () a prejdite na úpravu tohto vzorca.
- Zadajte už známe štruktúru na vyhľadávanie prvého oddeľovača v reťazci.
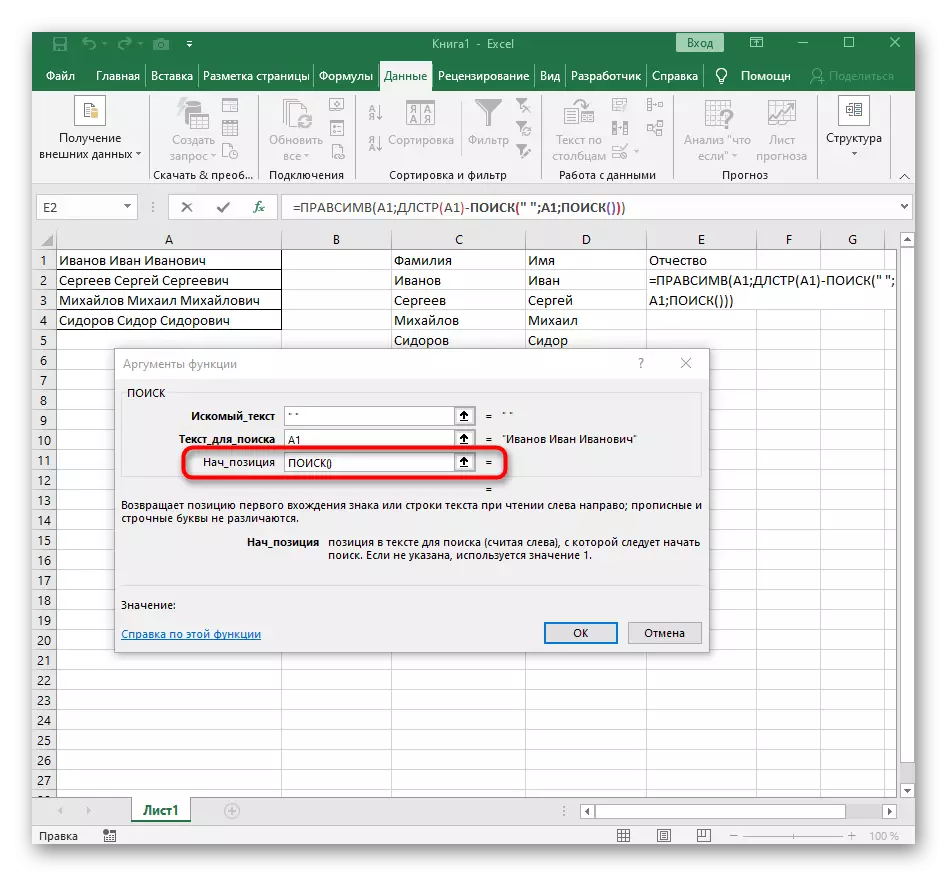
- Pridajte ďalšie vyhľadávanie na východiskovú pozíciu ().
- Uveďte to rovnakú štruktúru.
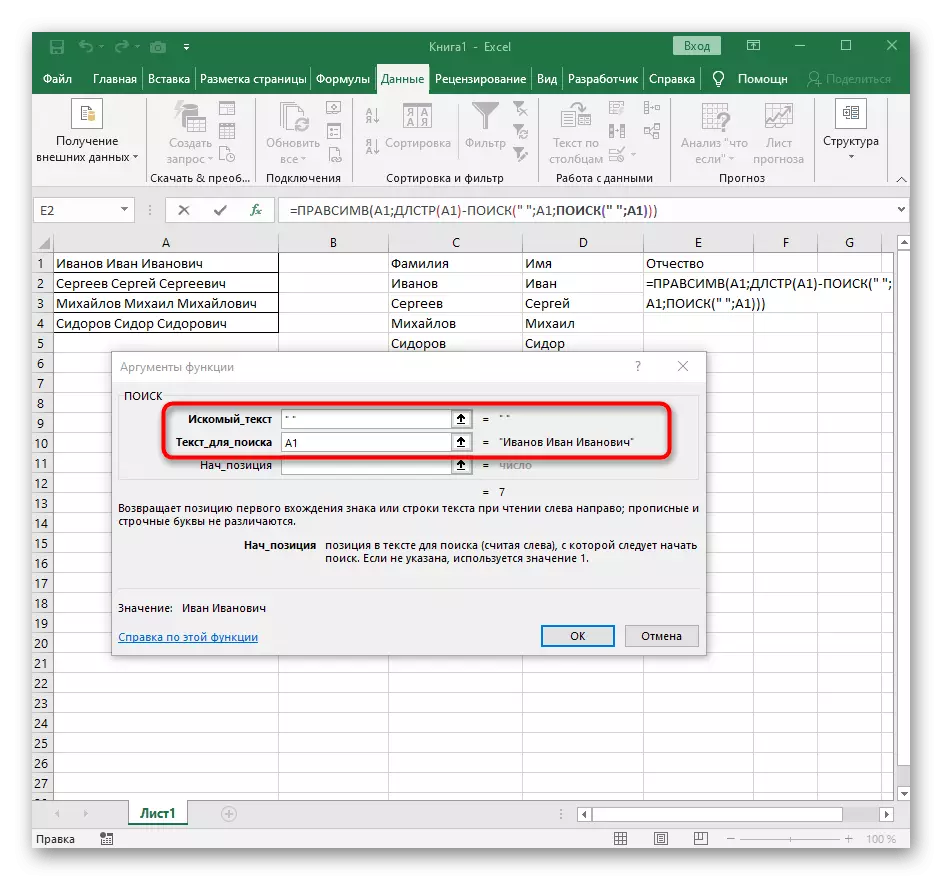
- Vráťte sa na predchádzajúce vyhľadávacie vzorca.
- Pridajte +1 do jeho počiatočnej polohy.
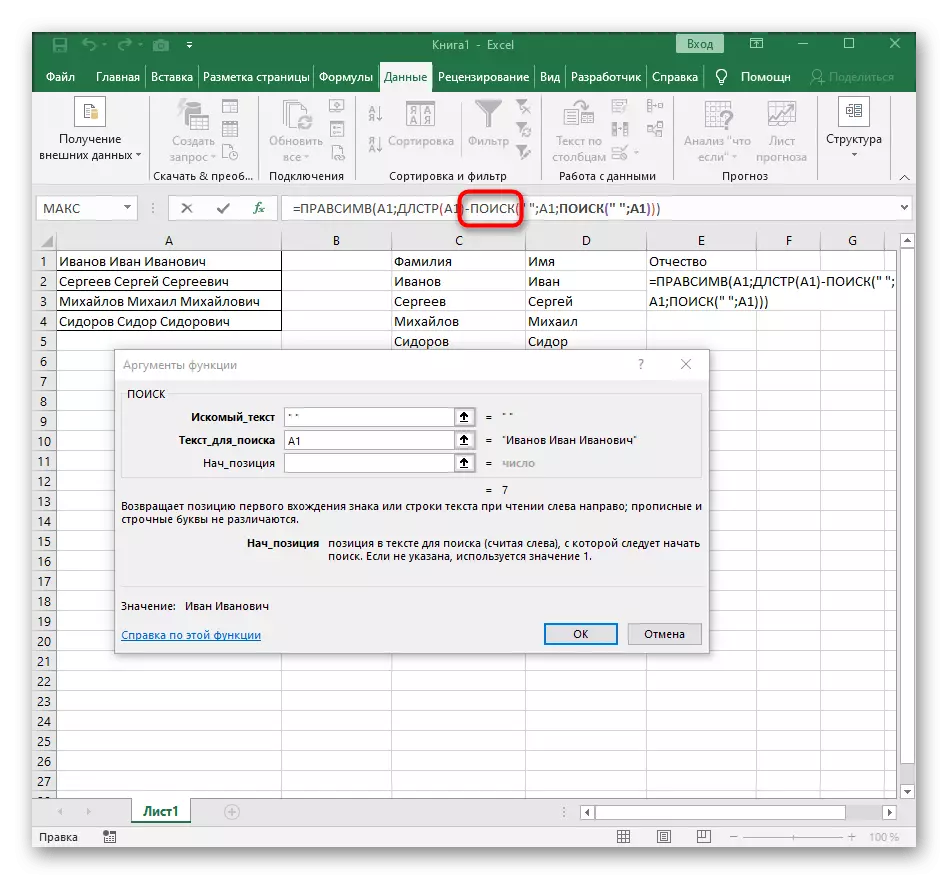
- Prejdite do koreňa vzorca RACCESSV a uistite sa, že sa výsledok zobrazí správne, a potom potvrďte zmeny. Kompletný vzorec v tomto prípade vyzerá = pracemír (A1; DLSTR (A1) -POIZK ("" A1; Hľadať ("" A1) +1)).
- V dôsledku toho, v nasledujúcom screenshote, vidíte, že všetky tri slová sú oddelené správne a sú v ich stĺpci. Na tento účel bolo potrebné použiť rôzne vzorce a pomocné funkcie, ale umožňuje dynamicky rozšíriť tabuľku a nebojte sa, že zakaždým, keď budete musieť zdieľať text znova. V prípade potreby jednoducho roztiahnite vzorec presunutím, aby sa automaticky ovplyvnili nasledujúce bunky.