पद्धत 1: स्वयंचलित साधन वापरणे
एक्सेलमध्ये कॉलममध्ये मजकूर विभाजित करण्यासाठी डिझाइन केलेले स्वयंचलित साधन आहे. हे स्वयंचलितपणे कार्य करत नाही, म्हणून प्रक्रिया केलेल्या डेटाची श्रेणी निवडून सर्व कारवाई स्वहस्ते करावी लागतील. तथापि, अंमलबजावणीमध्ये सेटिंग सर्वात सोपी आणि वेगवान आहे.
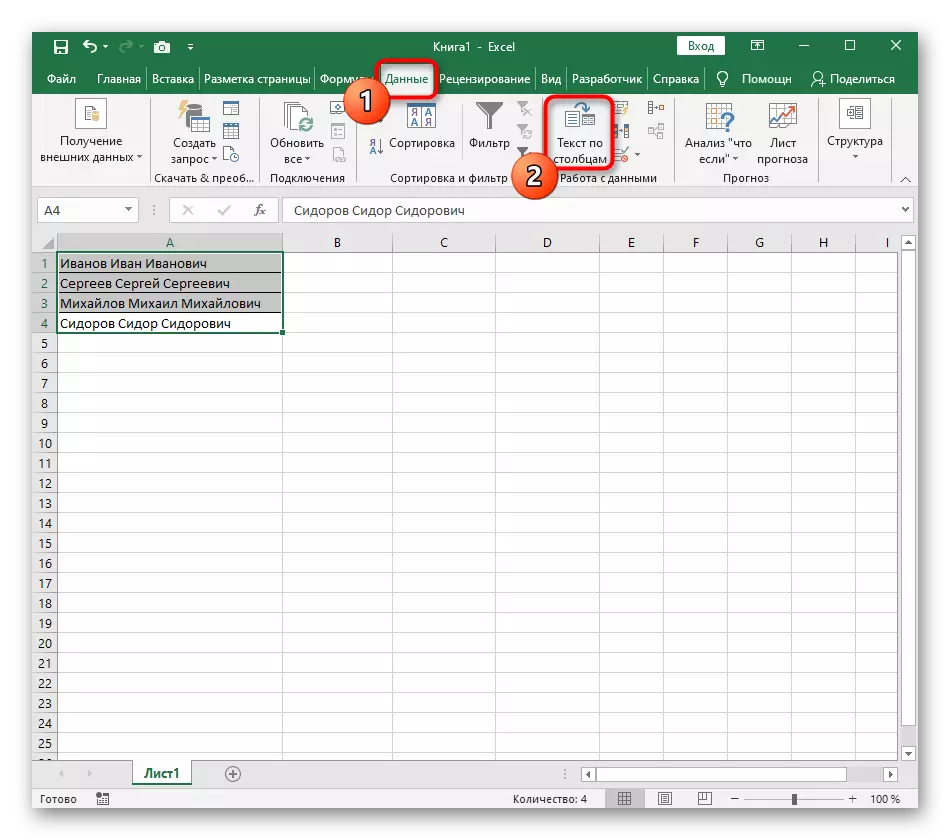
- माऊस बटणासह, आपण कॉलमवर विभाजित करू इच्छित असलेल्या सर्व पेशी निवडा.
- त्यानंतर, "डेटा" टॅबवर जा आणि "टेक्स टू स्तंभ" बटणावर क्लिक करा.
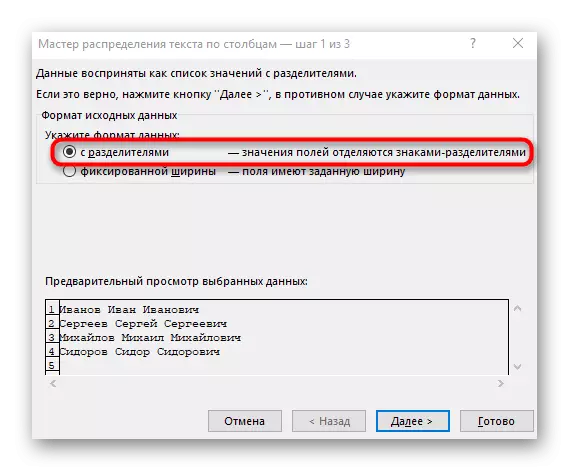
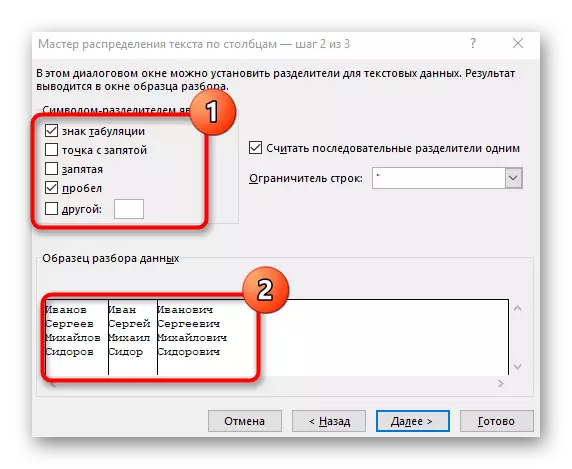
- "स्तंभ मजकूर विझार्ड" विंडो दिसते, ज्यामध्ये आपण "विभाजकांसह" डेटा स्वरूप निवडू इच्छित आहात. विभाजक बहुतेकदा स्पेस करतो, परंतु जर हे एक विरामचिन्ह चिन्ह असेल तर आपल्याला पुढील चरणात निर्दिष्ट करणे आवश्यक आहे.
- अनुक्रम चिन्ह तपासा किंवा मॅन्युअली प्रविष्ट करा आणि नंतर खालील विंडोमध्ये प्रारंभिक पृथक्करण परिणाम वाचा.
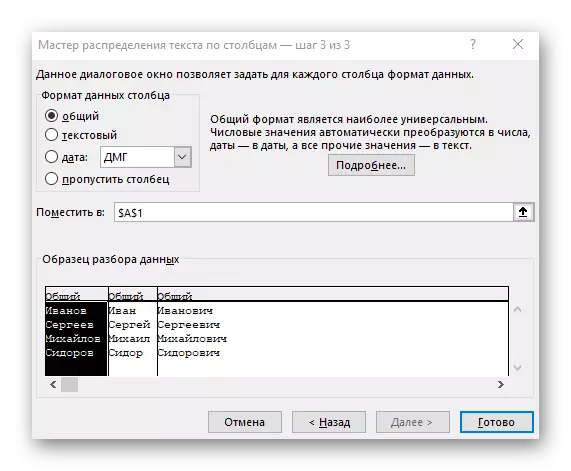
- अंतिम चरणात, आपण नवीन स्तंभ स्वरूप निर्दिष्ट करू शकता आणि जेथे ते ठेवावे. एकदा सेटअप पूर्ण झाल्यानंतर, सर्व बदल लागू करण्यासाठी "समाप्त" क्लिक करा.
- टेबलवर परत जा आणि खात्री करा की विभेद यशस्वीरित्या पास झाली आहे.


या सूचनामधून, आम्ही निष्कर्ष काढू शकतो की अशा प्रकारच्या साधनाचा वापरास अशा परिस्थितीत अनुकूल आहे जेथे विभेद केवळ एकदाच सादर करणे आवश्यक आहे, प्रत्येक शब्द नवीन स्तंभावर denoting. तथापि, जर नवीन डेटा टेबलमध्ये सतत ओळखला जातो, तर त्यांना विभाजित करण्यासाठी नेहमीच सोयीस्कर नसेल, म्हणून अशा प्रकरणांमध्ये आम्ही खालील प्रकारे स्वत: ला परिचित करण्याचा सल्ला देतो.
पद्धत 2: मजकूर स्प्लिट फॉर्म्युला तयार करणे
एक्सेलमध्ये, आपण स्वतंत्रपणे तुलनेने जटिल फॉर्म्युला तयार करू शकता ज्यामुळे आपल्याला सेलमधील शब्दांच्या पोजीशनची गणना करण्याची परवानगी दिली जाईल, अंतर शोधा आणि प्रत्येक विभाजित स्तंभांमध्ये विभाजित करण्यास अनुमती देईल. उदाहरण म्हणून, आम्ही रिक्त स्थानांद्वारे विभक्त केलेल्या तीन शब्दांचा सेल घेतो. त्यापैकी प्रत्येकासाठी, ते स्वतःचे सूत्र घेतील, म्हणून आम्ही पद्धती तीन टप्प्यांमध्ये विभागून टाकतो.चरण 1: पहिल्या शब्दाचे पृथक्करण
प्रथम शब्दासाठी सूत्र सर्वात सोपा आहे, कारण ते केवळ योग्य स्थिती निर्धारित करण्यासाठी फक्त एका अंतराने पुन्हा समाप्त करणे आवश्यक आहे. त्याच्या निर्मितीच्या प्रत्येक चरणावर विचार करा, जेणेकरून एक संपूर्ण चित्र तयार केले जाते की काही गणना आवश्यक आहेत.
- सोयीसाठी, सिग्नलसह तीन नवीन स्तंभ तयार करा जेथे आपण विभक्त मजकूर जोडतो. आपण तेच करू शकता किंवा हा क्षण वगळा.
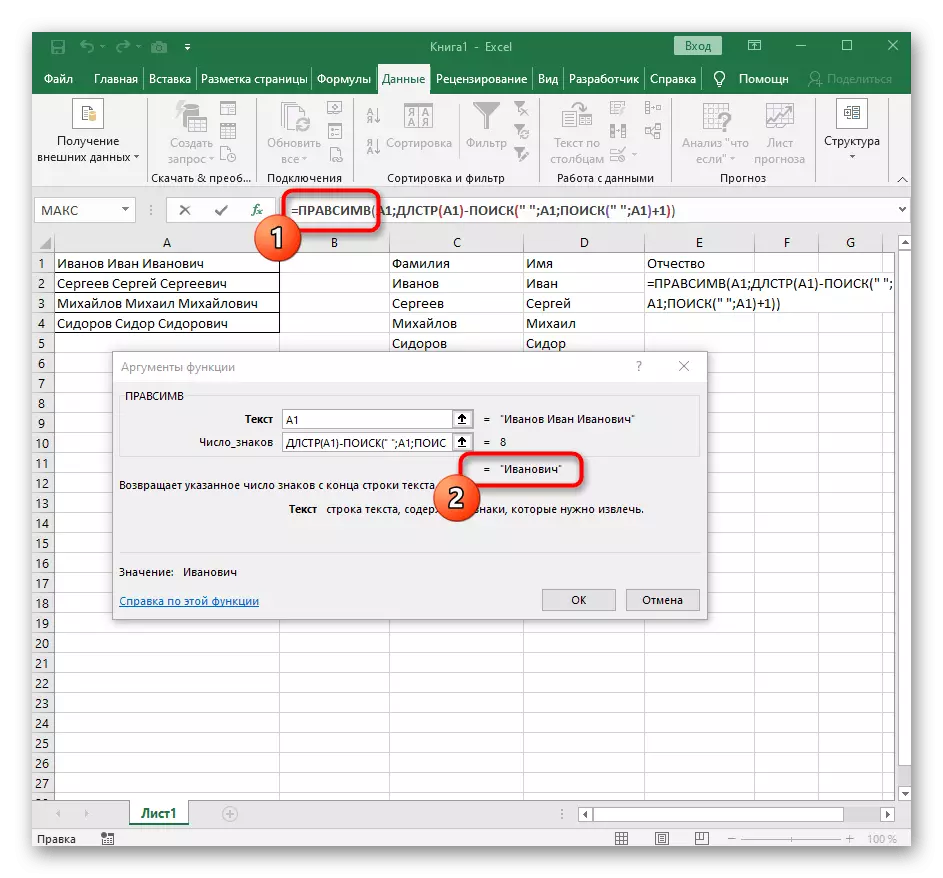
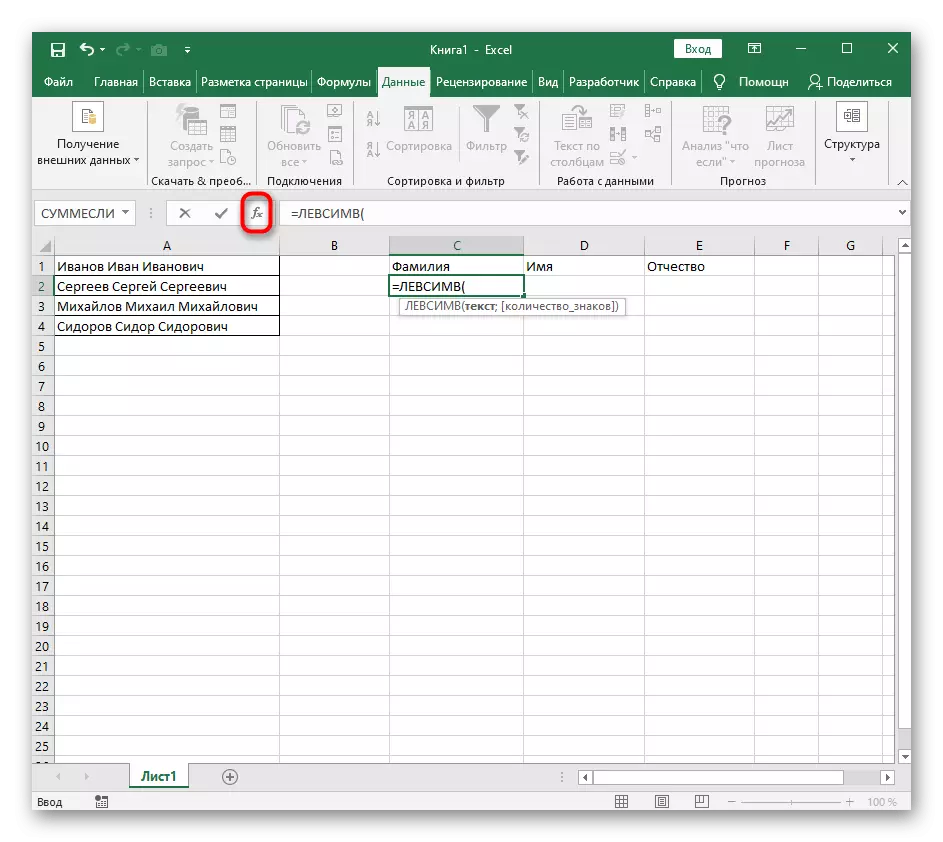
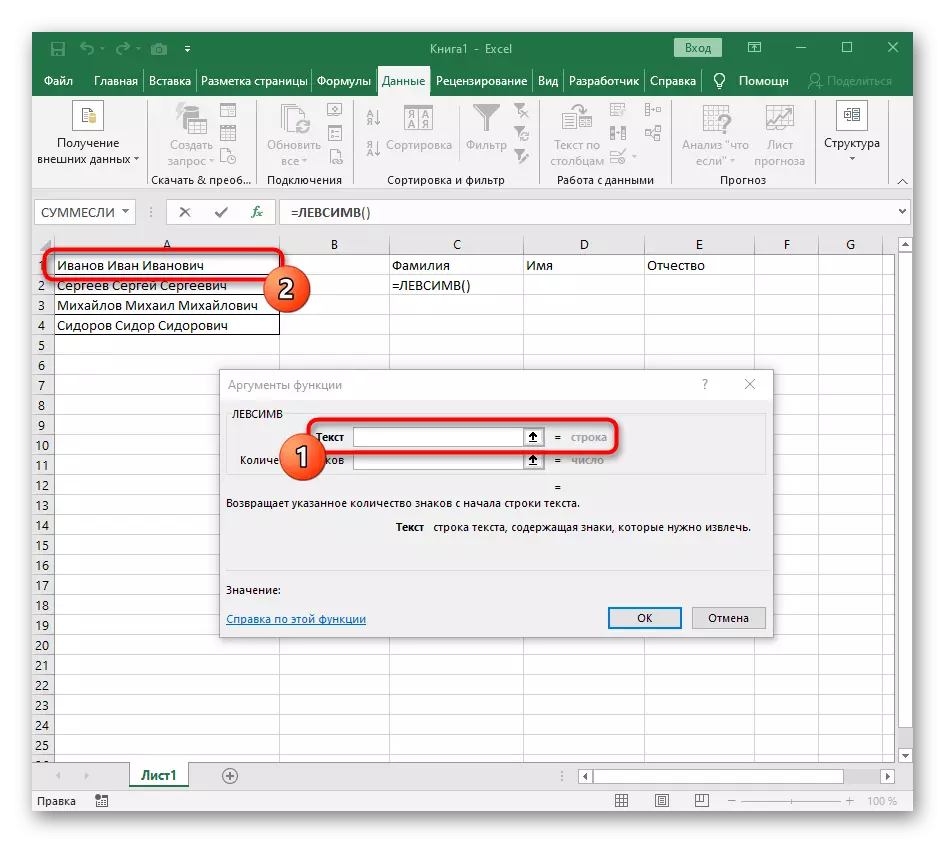
- आपण जेथे प्रथम शब्द स्थान ठेवू इच्छिता तेथे सेल निवडा आणि फॉर्म्युला = कमीम्व्ह (.
- त्यानंतर, "पर्याय आर्ग्युमेंट्स" बटण दाबा, अशा प्रकारे फॉर्म्युला ग्राफिक संपादन विंडोमध्ये हलवून.
- वितर्क मजकूर म्हणून, टेबलवरील डाव्या माऊस बटणासह त्यावर क्लिक करून शिलालेखासह सेल निर्दिष्ट करा.
- स्पेस किंवा दुसर्या विभाजकांना चिन्हांची संख्या मोजावी लागेल परंतु स्वहस्ते आम्ही हे करणार नाही, परंतु आम्ही दुसर्या सूत्राचा वापर करू - शोध ().
- जसे की आपण अशा स्वरूपात ते रेकॉर्ड करता तेव्हा ते शीर्षस्थानी असलेल्या सेलच्या मजकुरात दिसून येईल आणि बोल्डमध्ये हायलाइट केले जाईल. या फंक्शनच्या वितर्कांना द्रुतपणे संक्रमण करण्यासाठी त्यावर क्लिक करा.
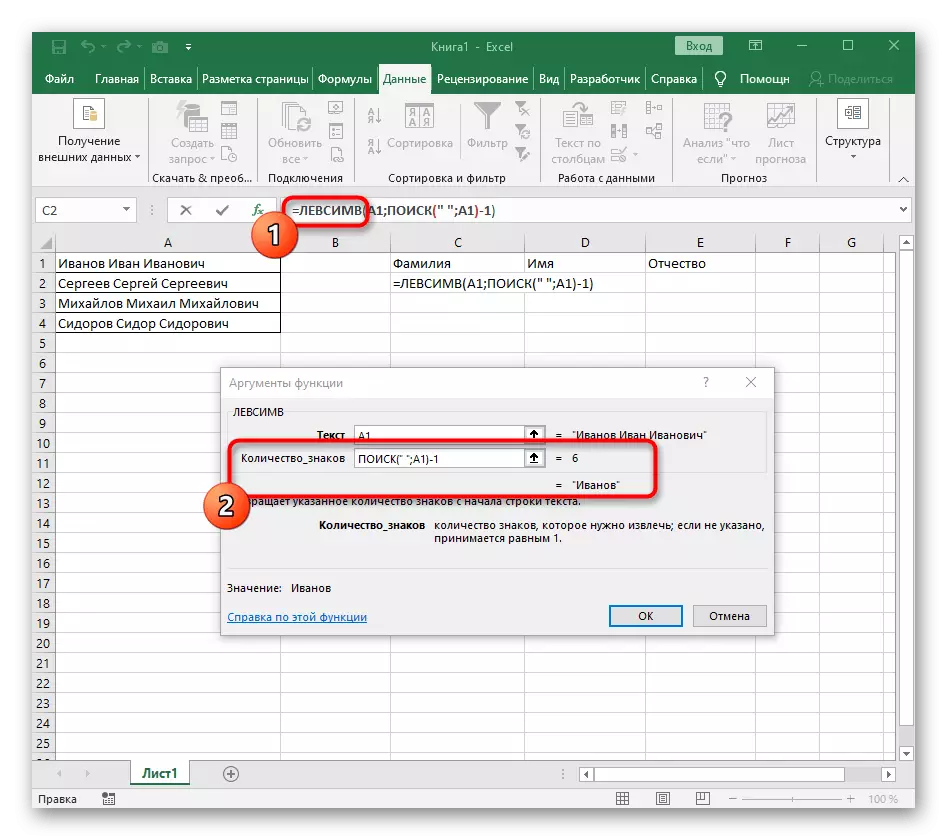
- "कंकाल" क्षेत्रात फक्त जागा किंवा विभाजक वापरला कारण शब्द कुठे संपतो हे समजून घेण्यास मदत करेल. "Text_-शोध" मध्ये समान सेल प्रक्रिया केली जात असल्याचे निर्दिष्ट.
- त्याकडे परत येण्यासाठी प्रथम कार्यावर क्लिक करा आणि दुसर्या वितर्क -1 च्या शेवटी जोडा. शोध फॉर्म्युला विचारात घेणे आवश्यक आहे इच्छित जागा, परंतु त्यावर प्रतीक आवश्यक आहे. खालील स्क्रीनशॉटमध्ये पाहिले जाऊ शकते म्हणून, परिणाम कोणत्याही स्पेसशिवाय प्रदर्शित होतो, याचा अर्थ फॉर्म्युला संकलन योग्यरित्या केले जाते.
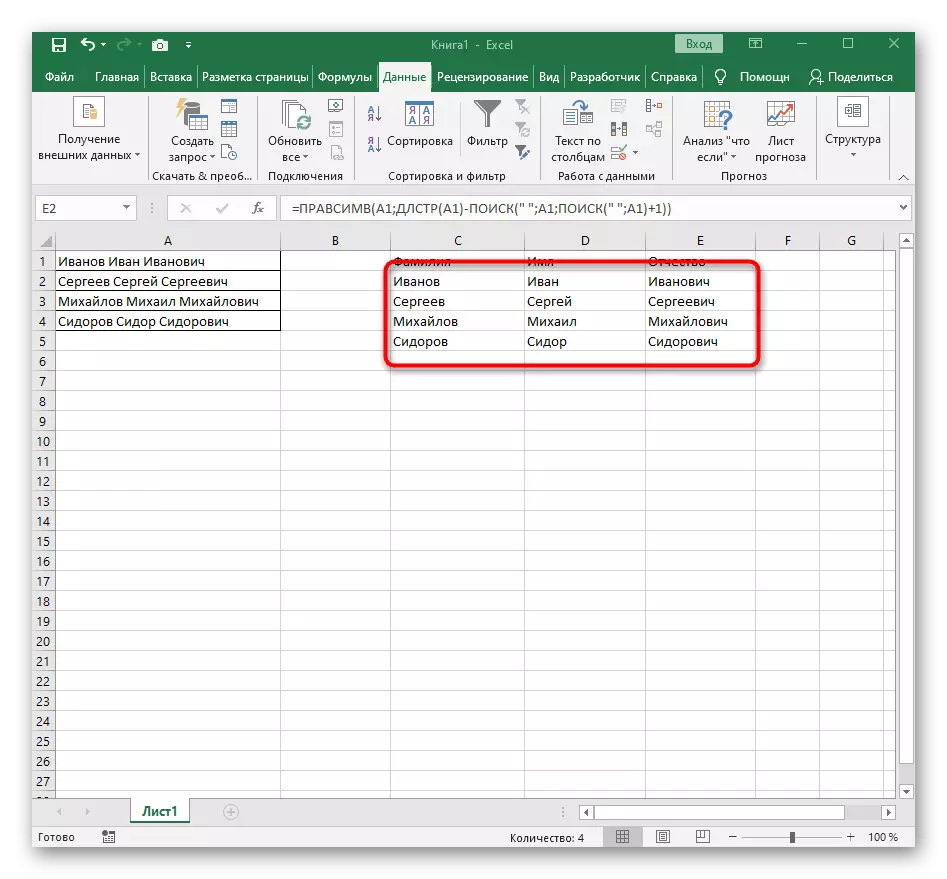
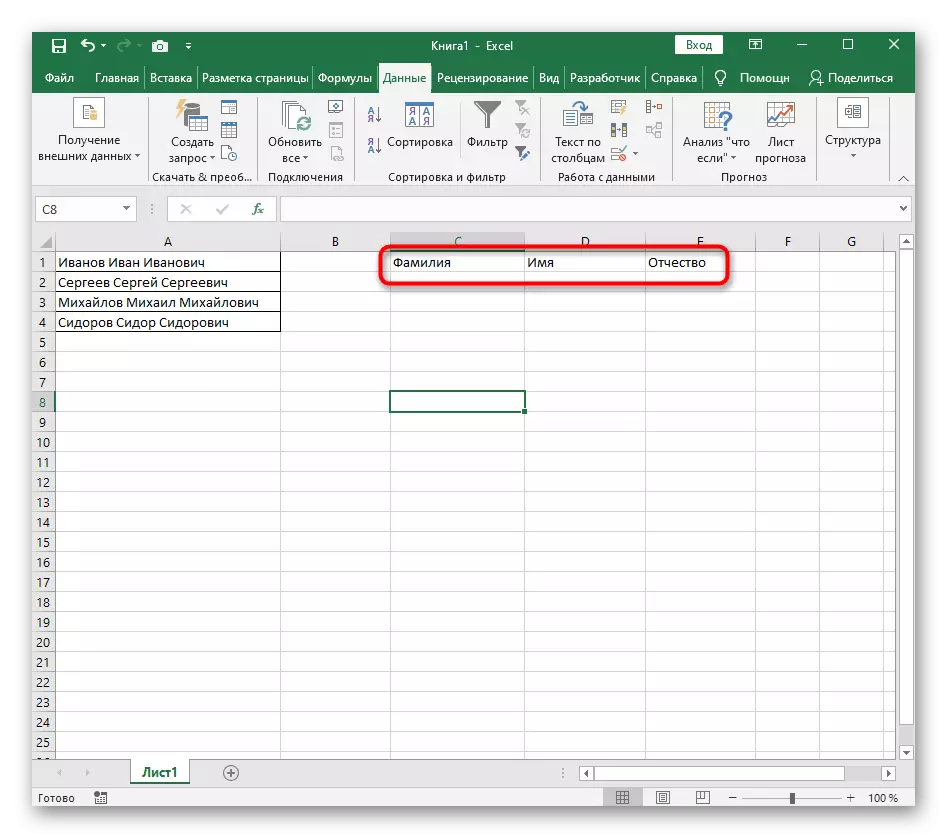
- फंक्शन एडिटर बंद करा आणि नवीन सेलमध्ये शब्द योग्यरित्या प्रदर्शित केला असल्याचे सुनिश्चित करा.
- लोअर उजव्या कोपर्यात सेल धरून ठेवा आणि त्यास आवश्यक असलेल्या पंक्तीवर ड्रॅग करा. म्हणून इतर अभिव्यक्तीचे मूल्य बदलले आहे, जे विभाजित केले जावे, आणि सूत्राची पूर्तता स्वयंचलितपणे आहे.




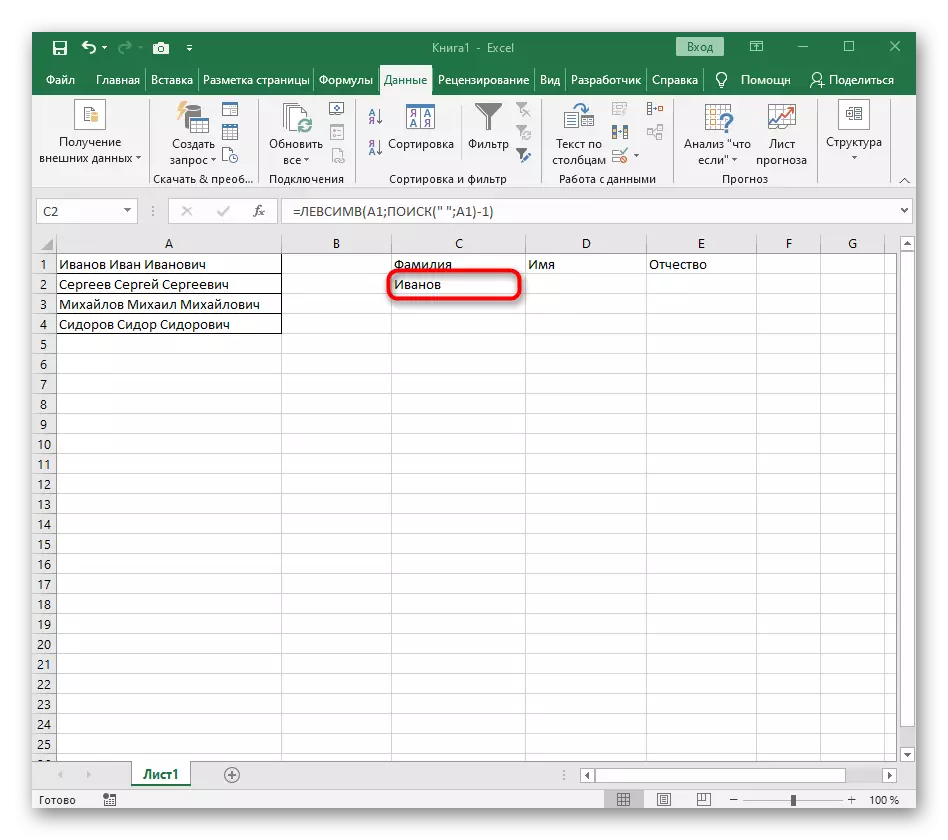

पूर्णपणे तयार फॉर्म्युला फॉर्म = levsimv आहे (ए 1; शोध ("a1) -1-1) आहे, आपण वरील सूचनांनुसार ते तयार करू शकता किंवा परिस्थिती आणि विभाजक योग्य असल्यास हे समाविष्ट करू शकता. प्रक्रिया केलेल्या सेल पुनर्स्थित करणे विसरू नका.
चरण 2: दुसर्या शब्दाचे पृथक्करण
सर्वात कठीण गोष्ट म्हणजे दुसरा शब्द विभाजित करणे, जे आमच्या प्रकरणात नाव आहे. हे असे आहे की हे दोन्ही बाजूंच्या रिक्त स्थानांमुळे घसरले आहे, म्हणून आपल्याला स्थितीच्या योग्य गणनासाठी मोठ्या प्रमाणावर फॉर्म्युला तयार करणे आवश्यक आहे.
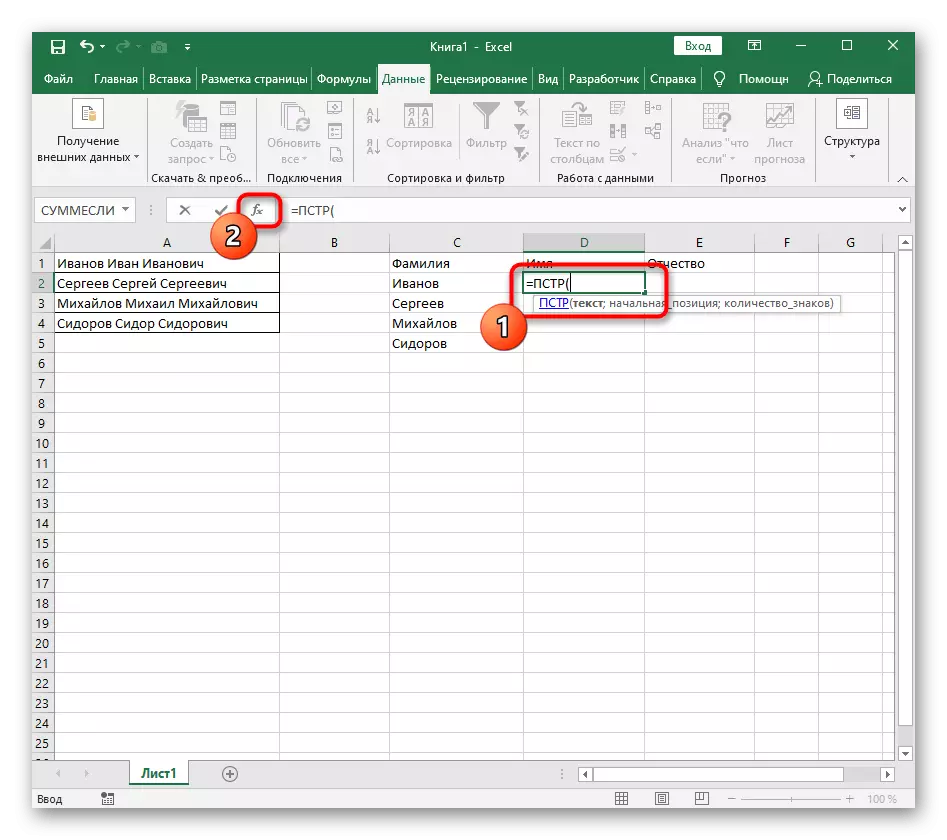
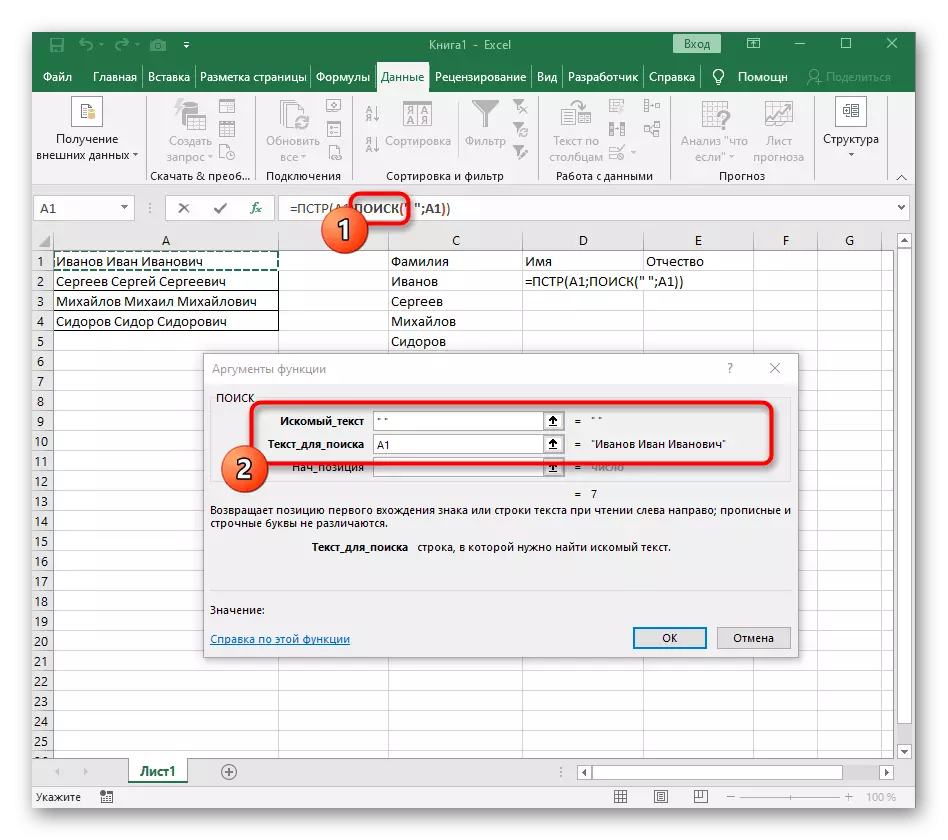
- या प्रकरणात मुख्य फॉर्म्युला = पीएसटी (- या फॉर्ममध्ये लिहा आणि नंतर युक्तिवाद सेटिंग्ज विंडोवर जा.
- हा फॉर्म्युला मजकूर मधील इच्छित स्ट्रिंग शोधेल, जो विभक्ततेसाठी शिलालेखाने सेलद्वारे निवडलेला आहे.
- ओळखीची प्रारंभिक स्थिती आधीच परिचित सहायक फॉर्म्युला शोध () वापरून निर्धारित करणे आवश्यक आहे.
- त्याकडे तयार करणे आणि फिरणे, मागील चरणात दर्शविल्याप्रमाणे त्याच प्रकारे भरा. इच्छित मजकूर म्हणून, विभाजक वापरा आणि शोधण्यासाठी सेल म्हणून सेल निर्दिष्ट करा.
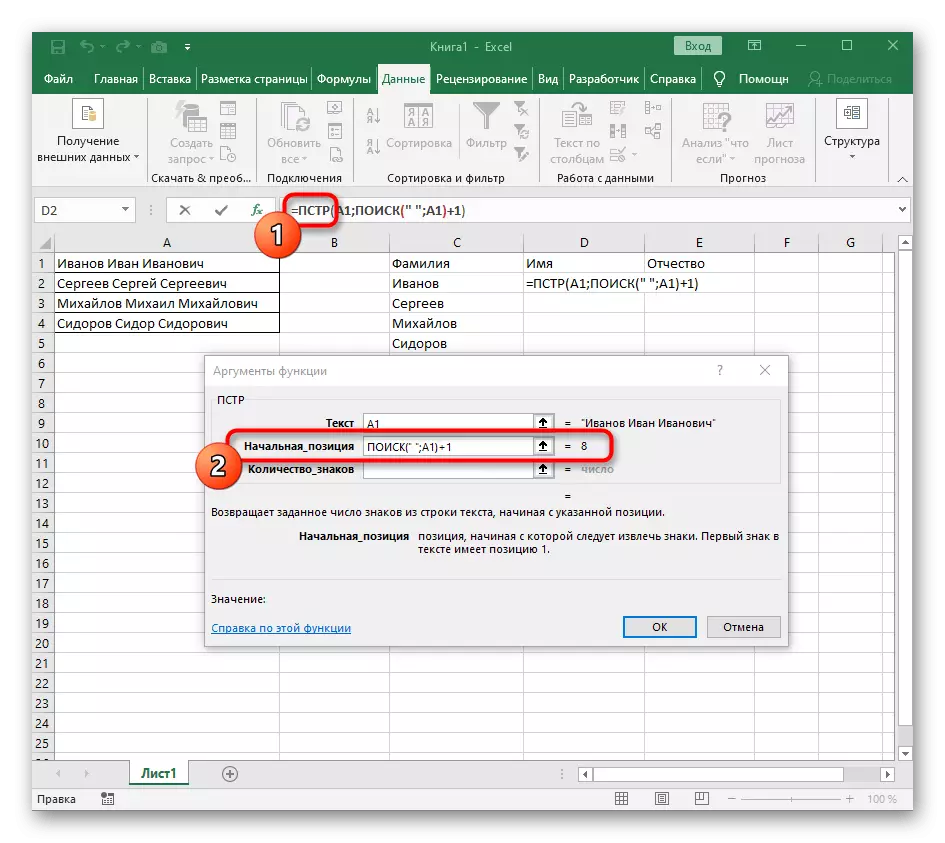
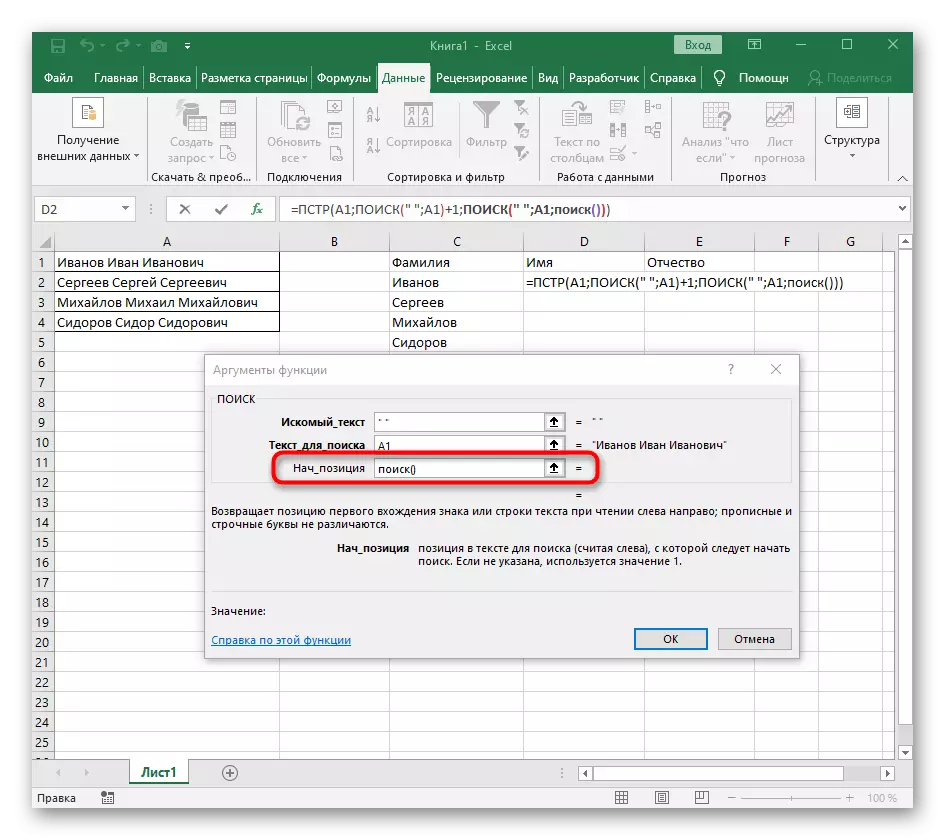
- मागील फॉर्म्युलाकडे परत जा, जेथे स्थान आढळल्यानंतर पुढील पात्रांमधून खाते सुरू करण्यासाठी "शोध" फंक्शन +1 जोडा.
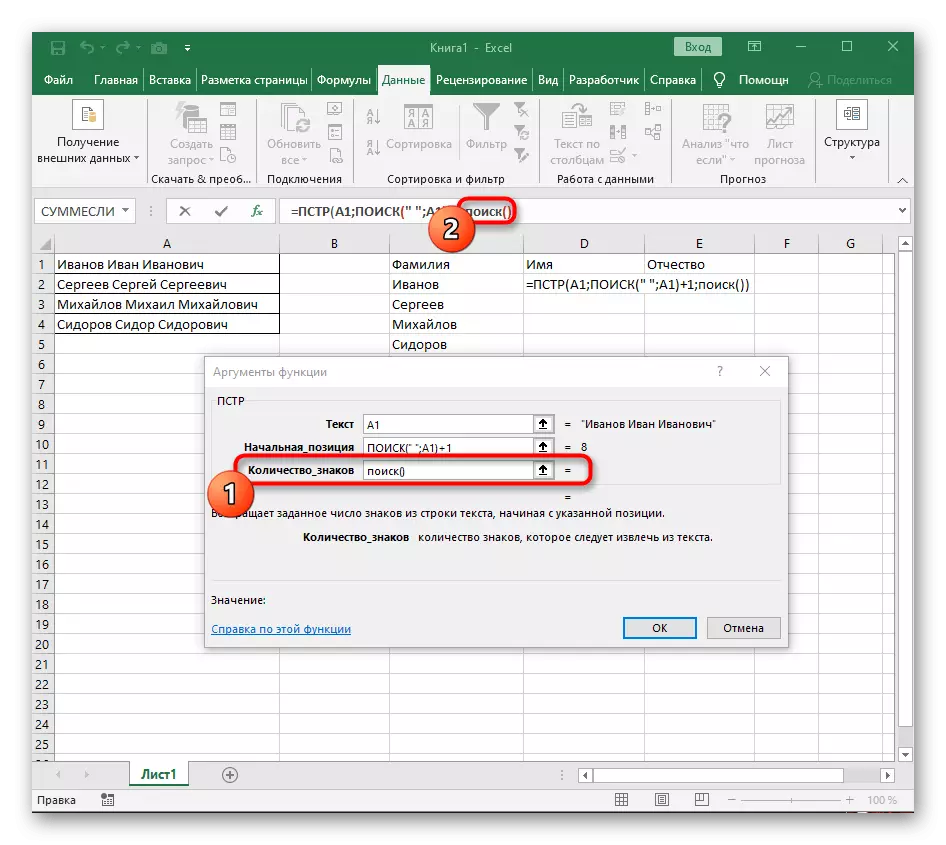
- आता फॉर्म्युला पहिल्या वर्ण नावापासून ओळ शोधत आहे, परंतु तरीही ते कुठे पूर्ण करावे हे माहित नाही, म्हणून, "क्वांटी_नीम" पुन्हा पुन्हा, शोध फॉर्म्युला () लिहा.
- त्याच्या युक्तिवादांवर जा आणि आधीच परिचित फॉर्ममध्ये भरा.
- पूर्वी, आम्ही या कार्याची प्रारंभिक स्थिती मानली नाही, परंतु आता शोध प्रविष्ट करणे आवश्यक आहे (), कारण या सूत्राने प्रथम अंतर शोधू नये, परंतु दुसरी.
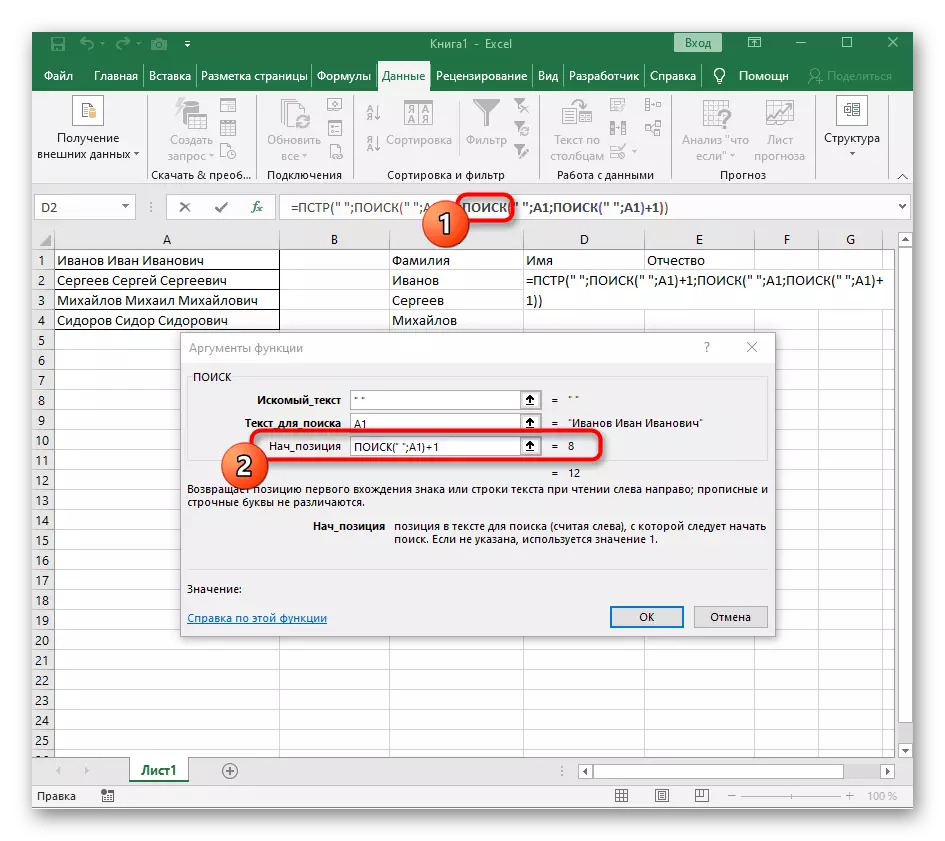
- तयार केलेल्या फंक्शनवर जा आणि त्याच प्रकारे भरा.
- पहिल्या "शोधात परत जा आणि शेवटी" nach_position "+1 मध्ये जोडा, कारण त्याला ओळ शोधण्यासाठी जागा आवश्यक नाही, परंतु पुढील पात्र.
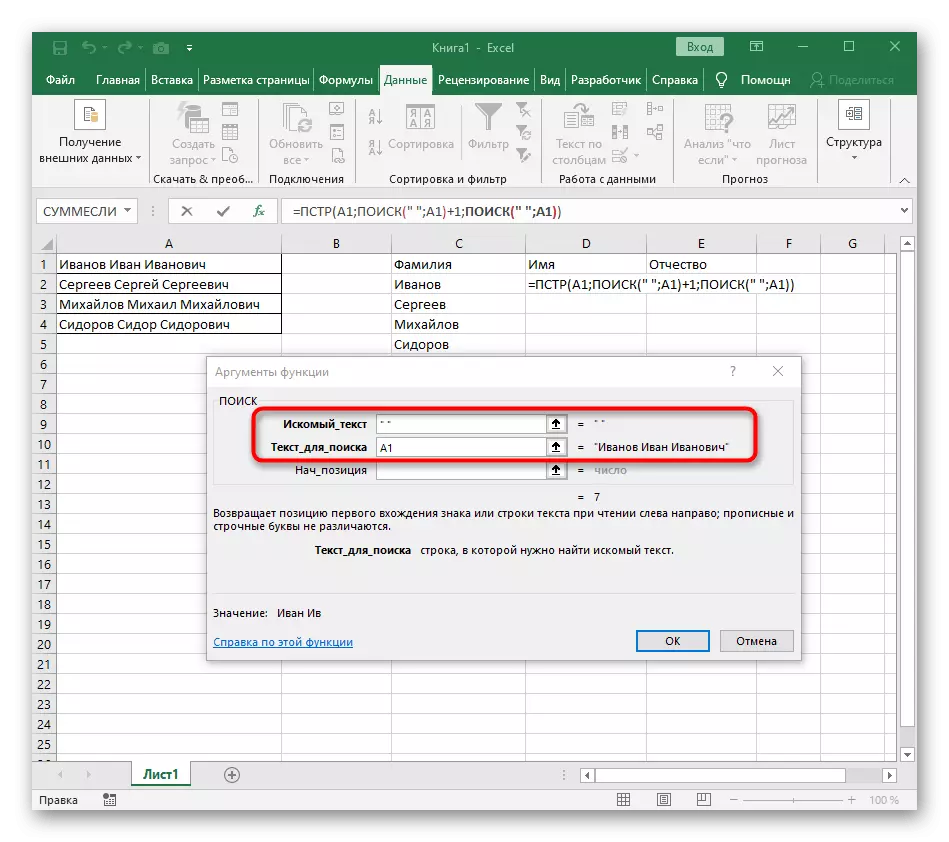
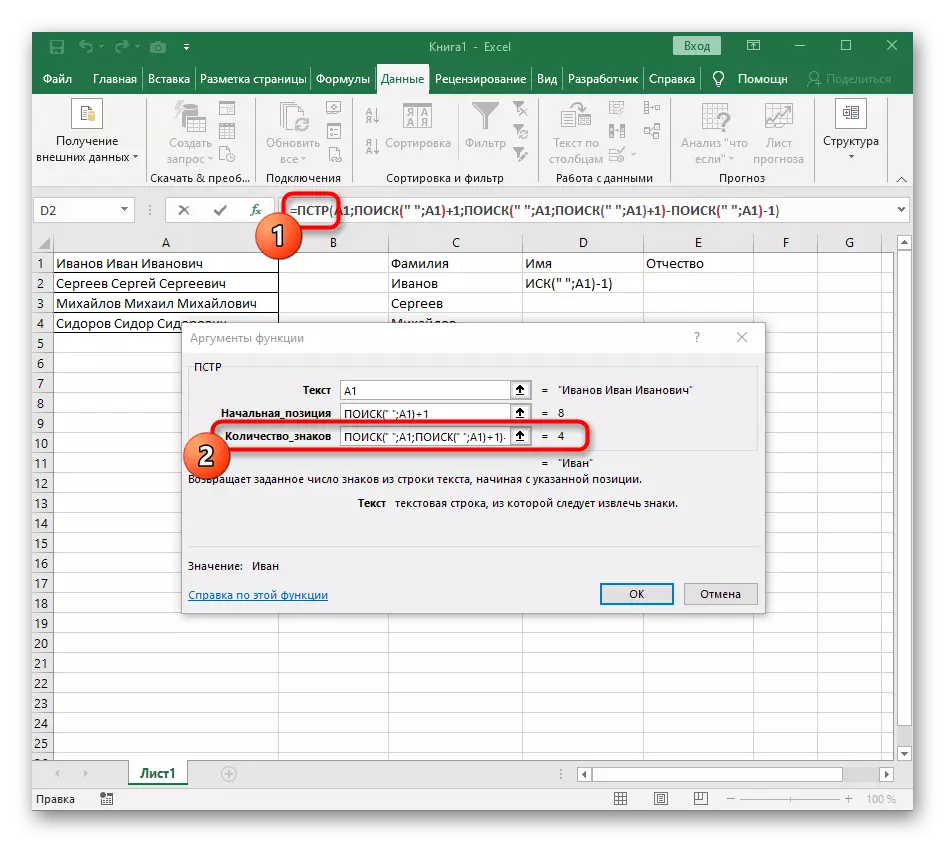
- रूट = पीएसटी वर क्लिक करा आणि कर्सर लाइन "nunce_names" च्या शेवटी ठेवा.
- स्पेसच्या गणना पूर्ण करण्यासाठी अभिव्यक्तीची अभिव्यक्ती (""; ए 1) -1 ची अभिव्यक्ती काढा.
- टेबलवर परत जा, सूत्र वाढवा आणि शब्द योग्यरित्या प्रदर्शित केले असल्याचे सुनिश्चित करा.



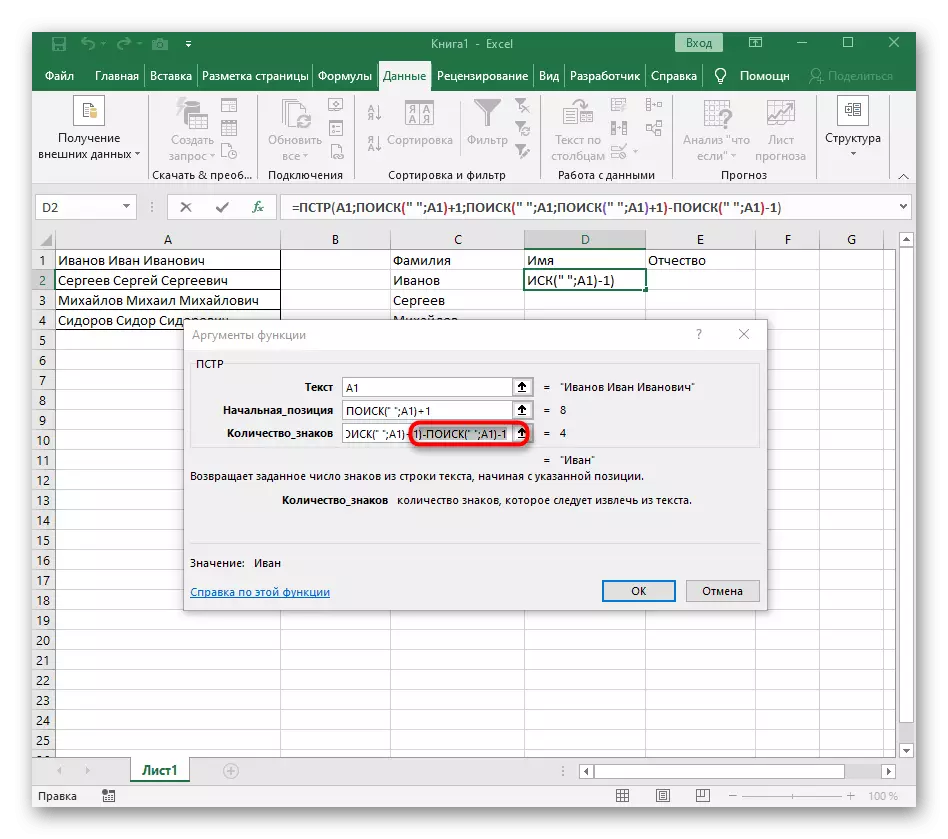
फॉर्म्युला मोठा झाला आणि सर्व वापरकर्त्यांना ते कसे कार्य करते हे समजत नाही. वस्तुस्थिती शोधण्यासाठी मला अनेक कार्ये वापराव्या लागतात जे रिक्त स्थानांचे प्रारंभिक आणि अंतिम स्थिती निर्धारित करतात आणि नंतर एक चिन्ह त्यांच्याकडून काढून टाकले जेणेकरून, हे सर्वात अंतर प्रदर्शित केले गेले. याचा परिणाम म्हणून, फॉर्म्युला हे आहे: = पीआरटी (ए 1; शोध ("ए 1) +1; शोध (" "; ए 1; शोध (" "; ए 1) +1) -पोज (" "; ए 1) - 1). मजकूरासह सेल नंबर बदलून, उदाहरण म्हणून वापरा.
चरण 3: तिसरा शब्द वेगळे करणे
आमच्या सूचनांचे शेवटचे पाऊल म्हणजे तिसऱ्या शब्दाचे विभाजन म्हणजे जे प्रथम घडले तेच दिसते, परंतु सामान्य सूत्र किंचित बदलते.
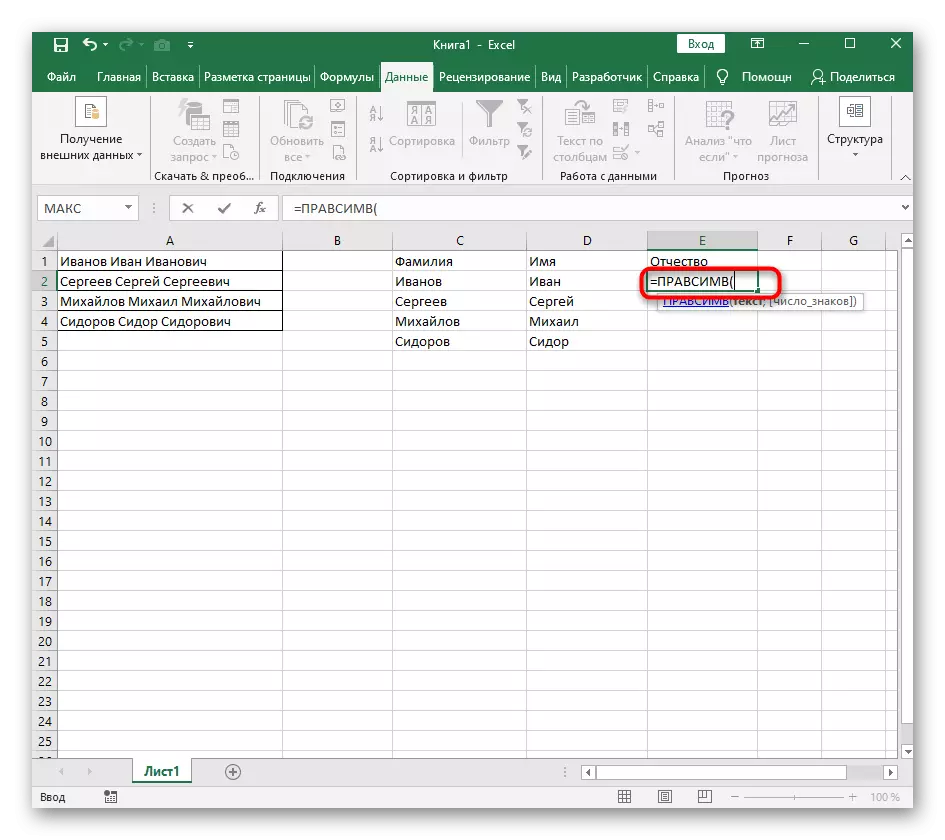
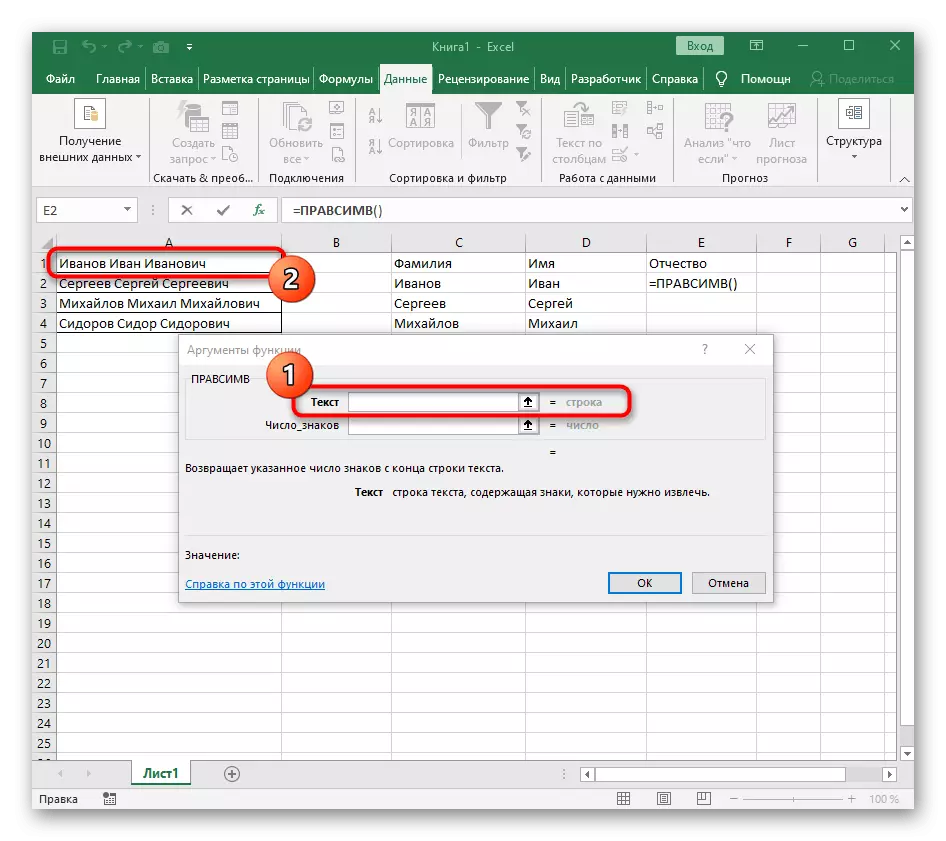
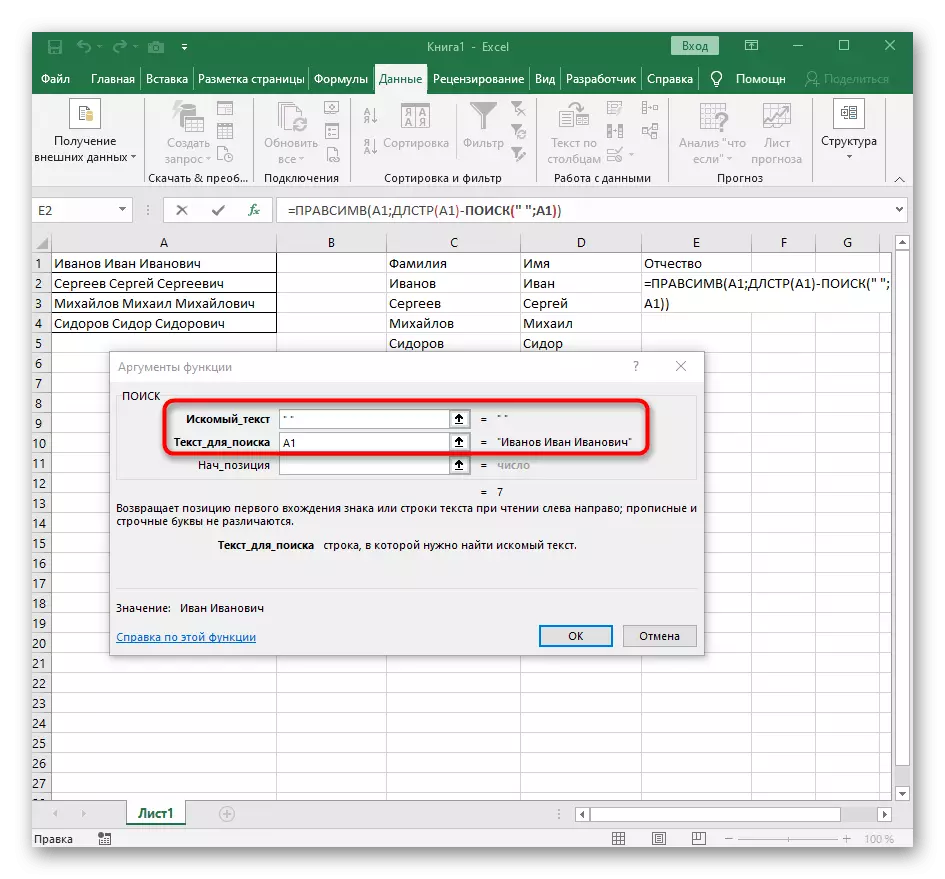
- रिकाम्या सेलमध्ये, भविष्यातील मजकुराच्या स्थानासाठी, = rashesimv लिहा (आणि या कार्याच्या युक्तिवादांवर जा.
- मजकूर म्हणून, विभक्ततेसाठी शिलालेख असलेली एक सेल निर्दिष्ट करा.
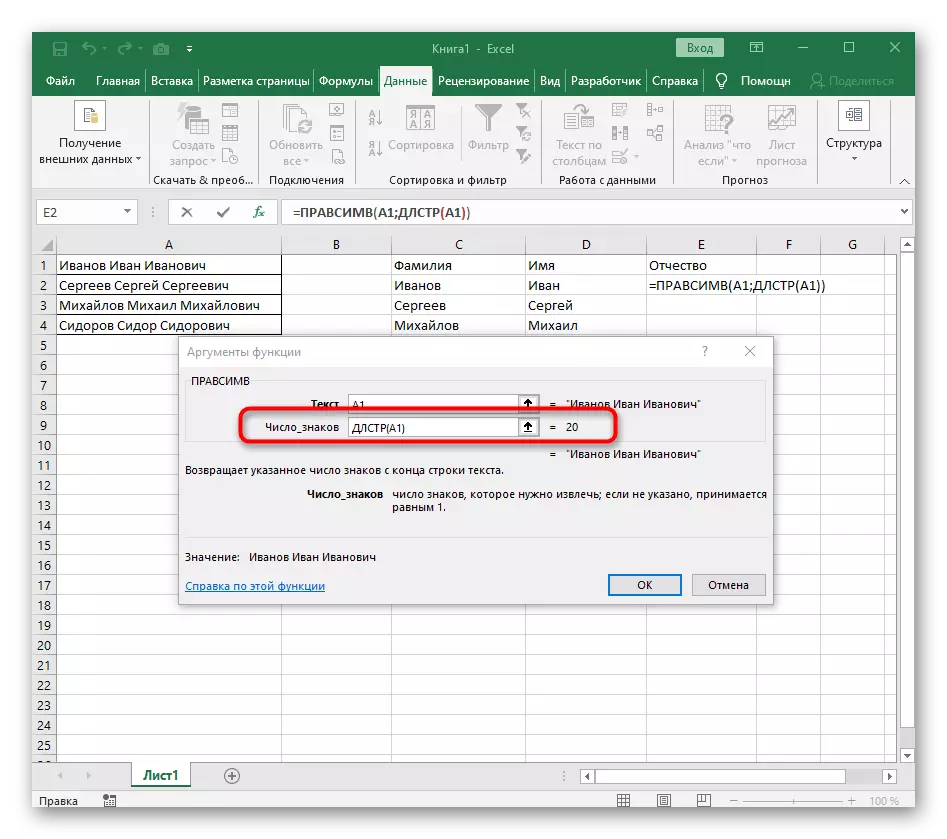
- या वेळी एक शब्द शोधण्यासाठी सहायक कार्य डीएलआरआरटी (ए 1) म्हणतात, जेथे ए 1 मजकूर समान सेल आहे. हे वैशिष्ट्य मजकूरमधील वर्णांची संख्या निर्धारित करते आणि आम्ही केवळ योग्य वाटेल.
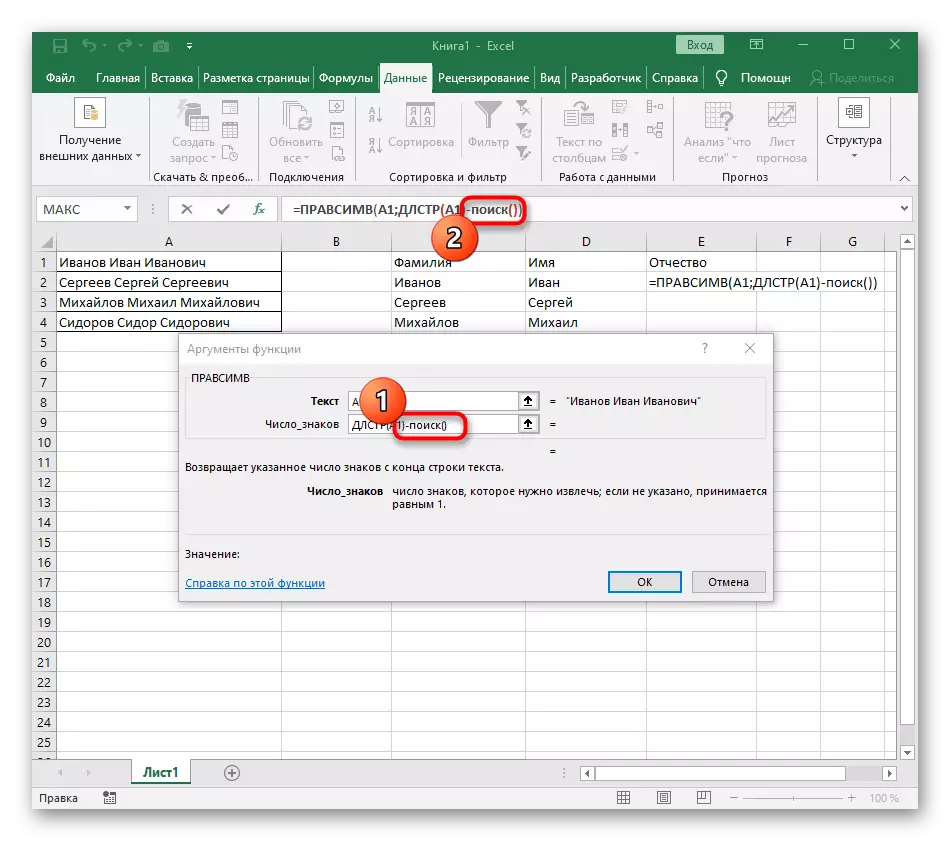
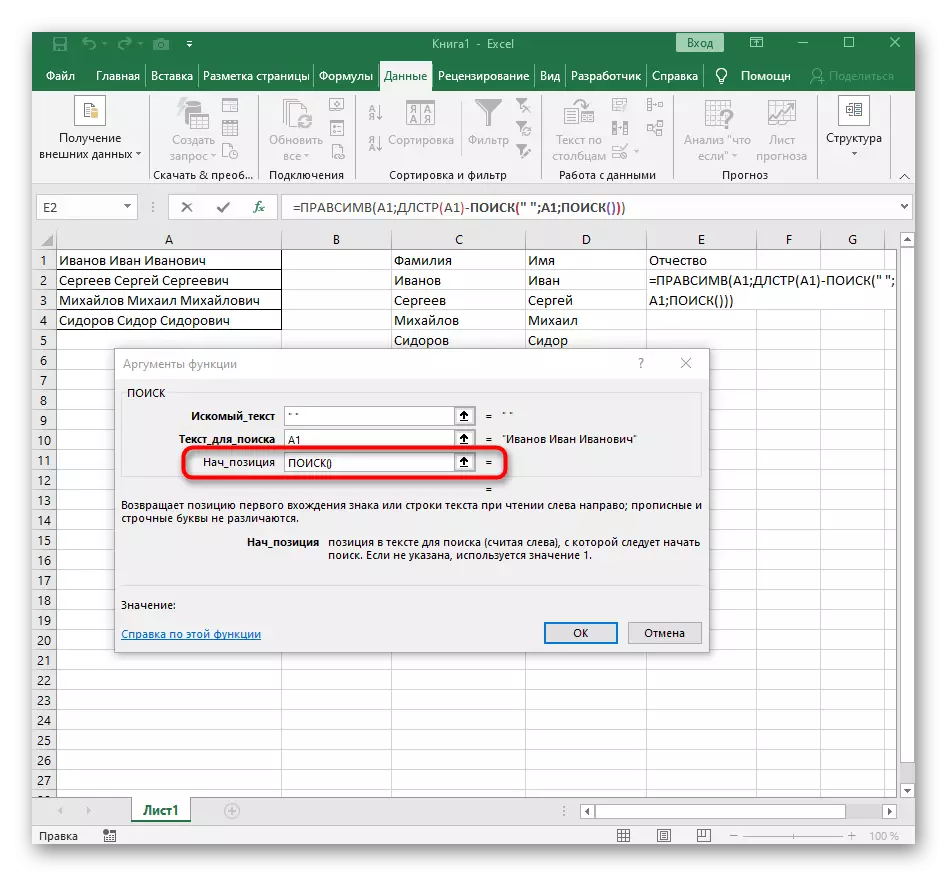
- हे करण्यासाठी, ad-posisk () आणि हा फॉर्म्युला संपादित करण्यासाठी जा.
- स्ट्रिंगमधील प्रथम विभाजक शोधण्यासाठी आधीच परिचित संरचना प्रविष्ट करा.
- प्रारंभिक स्थितीसाठी दुसरा शोध जोडा ().
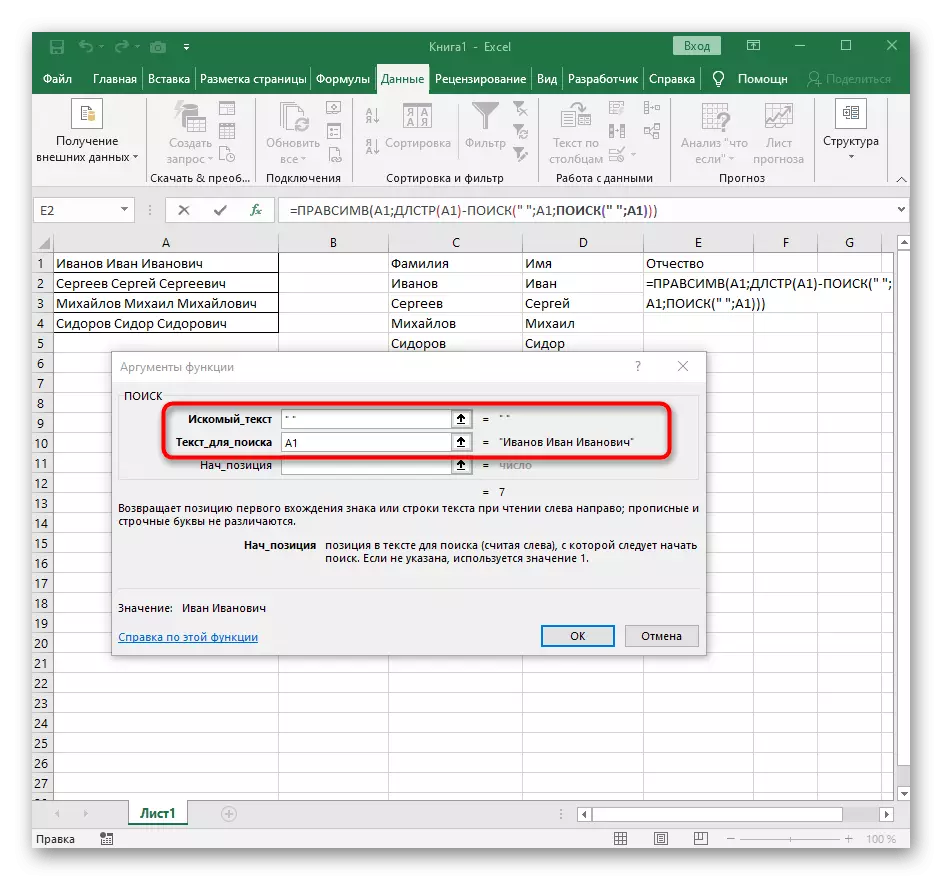
- ते समान संरचना निर्दिष्ट करा.
- मागील शोध सूत्राकडे परत जा.
- त्याच्या प्रारंभिक स्थितीत +1 जोडा.
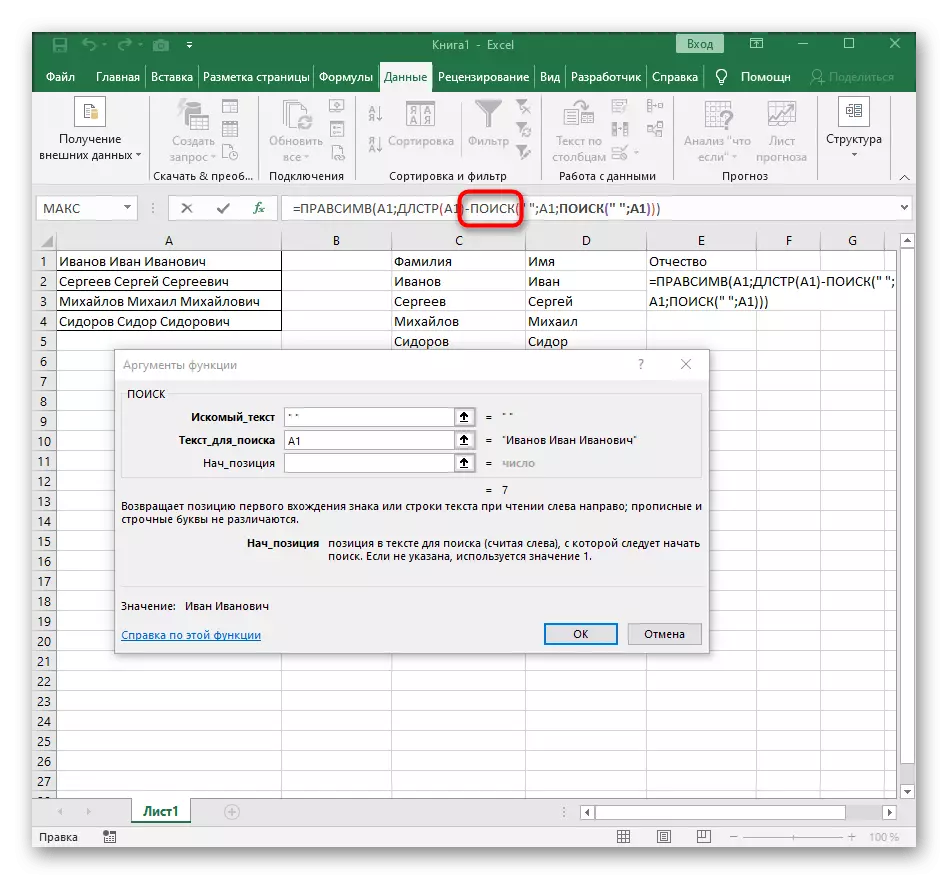
- फॉर्म्युला rascessv च्या रूटवर नेव्हिगेट करा आणि परिणाम योग्यरित्या प्रदर्शित केले असल्याचे सुनिश्चित करा आणि नंतर बदलांची पुष्टी करा. या प्रकरणात संपूर्ण सूत्र = pracemir (ए 1; डीएलआरटी (ए 1) -poisk (""; A1; शोध ("" ए 1) +1).
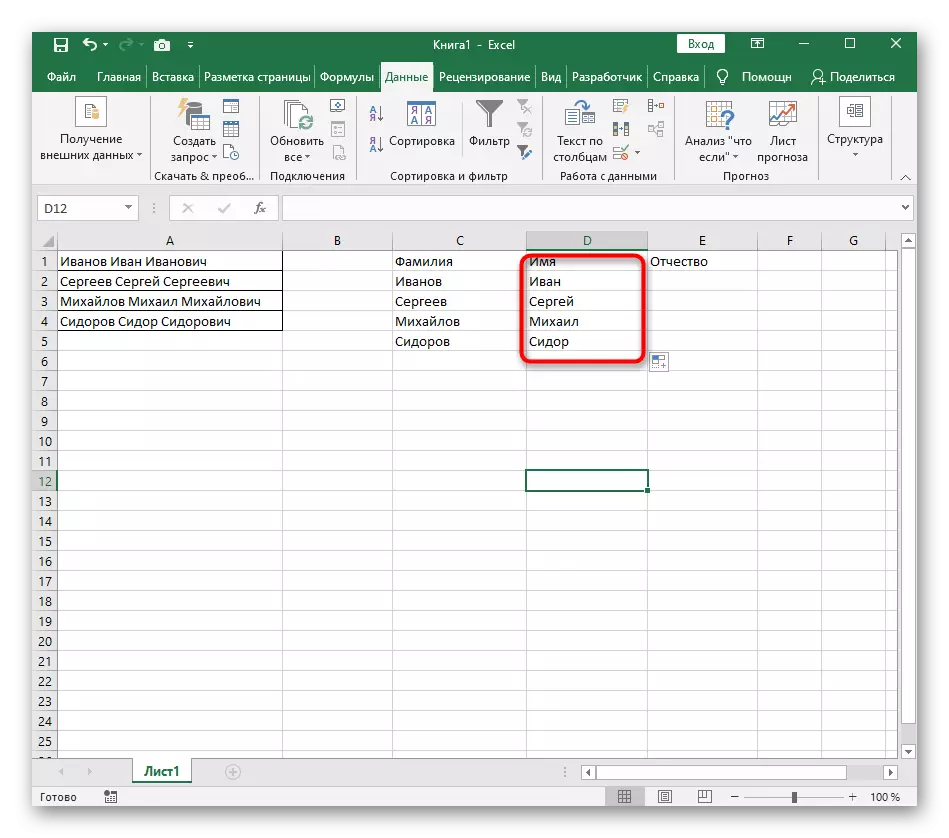
- परिणामी, पुढील स्क्रीनशॉटमध्ये आपण पाहता की सर्व तीन शब्द योग्यरित्या वेगळे केले जातात आणि त्यांच्या स्तंभांमध्ये आहेत. त्यासाठी विविध प्रकारचे सूत्र आणि सहायक कार्ये वापरणे आवश्यक होते, परंतु ते आपल्याला गतिशीलपणे टेबल विस्तृत करण्यास परवानगी देते आणि प्रत्येक वेळी आपल्याला पुन्हा मजकूर सामायिक करणे आवश्यक आहे याची काळजी करू नका. आवश्यक असल्यास, सूत्र सहजपणे हलवून विस्तृत करा जेणेकरून खालील सेल्स आपोआप आपोआप प्रभावित होतील.