방법 1 : 자동 도구 사용
Excel에는 열에서 텍스트를 분할하도록 설계된 자동 도구가 있습니다. 자동으로 작동하지 않으므로 모든 작업을 수동으로 수행하여 처리 된 데이터의 범위를 선택해야합니다. 그러나 설정은 구현에서 가장 간단하고 빠릅니다.
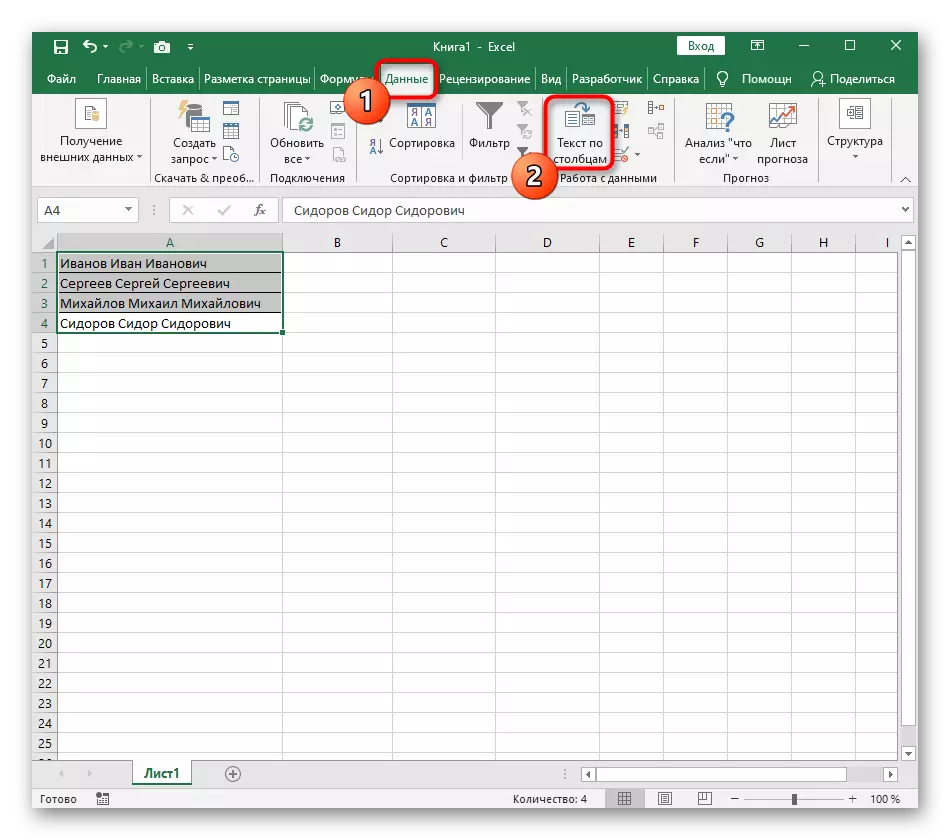
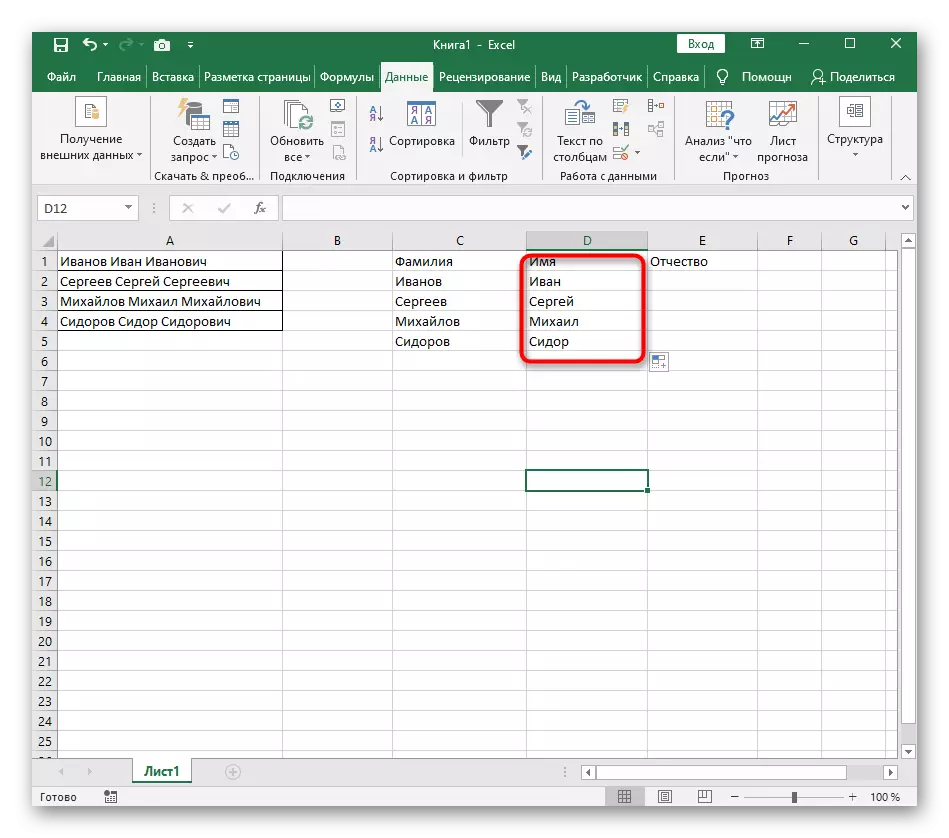
- 왼쪽 마우스 버튼을 사용하여 열을 나눌 텍스트를 모두 선택하십시오.
- 그런 다음 "데이터"탭으로 이동하여 "텍스트 열"버튼을 클릭하십시오.
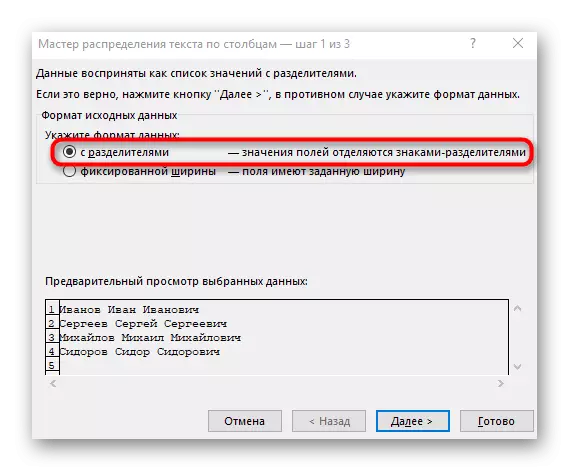
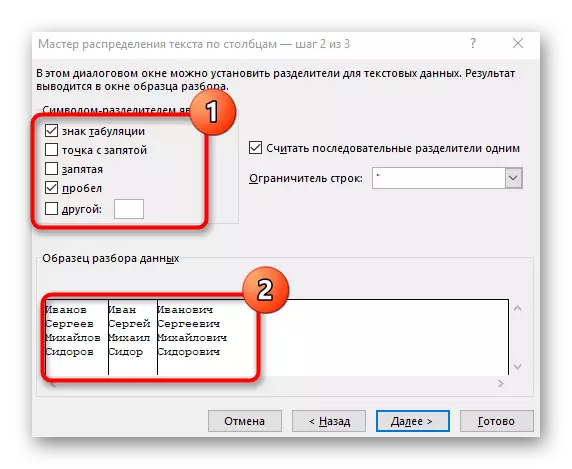
- "열 텍스트 마법사"창이 나타납니다.이 창이 나타납니다. "구분 기호로 데이터 형식"을 선택하십시오. " 세퍼레이터는 가장 자주 공간을 수행하지만 다른 구두점이면 다음 단계에서 지정해야합니다.
- 시퀀스 기호 확인을 선택하거나 수동으로 입력 한 다음 아래 창에서 예비 분리 결과를 읽으십시오.
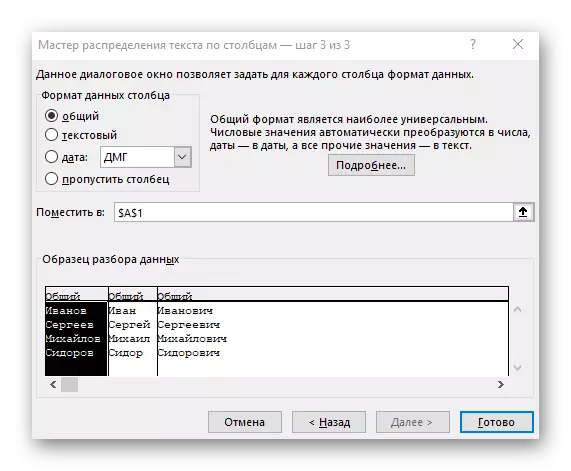
- 마지막 단계에서 새 열 형식과 배치 해야하는 장소를 지정할 수 있습니다. 설정이 완료되면 "마침"을 클릭하여 모든 변경 사항을 적용하십시오.
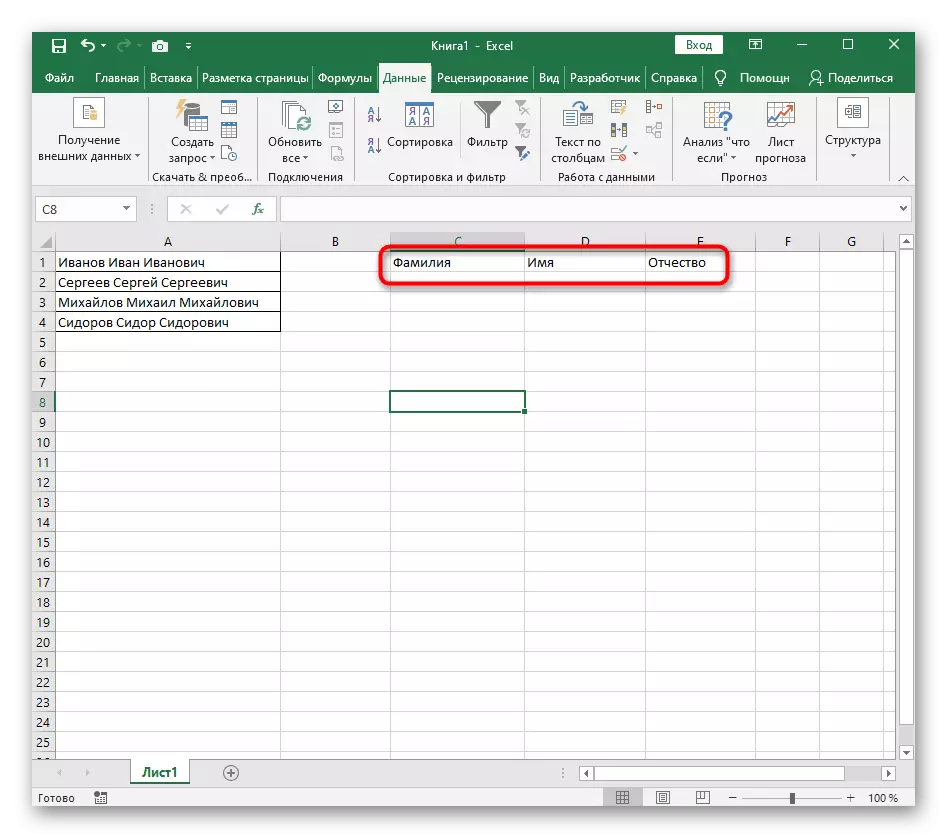
- 테이블로 돌아가서 분리가 성공적으로 전달되었는지 확인하십시오.


이 지시에서 우리는 그러한 도구의 사용이 새로운 열에 대해 각 단어에 대해 표시되는 해당 상황에서 이러한 공구의 사용이 한 번만 수행되어야하는 상황에서 최적으로 최적으로 제공된다고 결론 지을 수 있습니다. 그러나 새로운 데이터가 끊임없이 테이블에 도입되면 이들을 나눌 시간이 너무 편리하지 않으므로 다음과 같은 방식으로 자신을 익히는 것이 좋습니다.
방법 2 : 텍스트 분할 수식 생성
Excel에서는 셀에서 단어의 위치를 계산하고 틈을 찾아서 각각 별도의 열로 나눌 수있는 상대적으로 복잡한 수식을 독립적으로 만들 수 있습니다. 예를 들어, 우리는 공백으로 구분 된 세 단어로 구성된 세포를 가져갈 것입니다. 그들 각각을 위해, 그것은 자신의 공식을 취할 것이므로 그 방법을 3 단계로 나눕니다.1 단계 : 첫 번째 단어의 분리
첫 번째 단어의 수식은 하나의 틈에서만 올바른 위치를 결정하기 위해서만 튕겨져 있어야하기 때문에 가장 간단합니다. 각 생성 단계를 고려해야하므로 완전한 그림이 특정 계산이 필요한 이유 이도록합니다.
- 편의를 위해 분리 된 텍스트를 추가 할 서명이있는 세 개의 새로운 열을 만듭니다. 이 순간을 똑같이하거나 건너 뛸 수 있습니다.
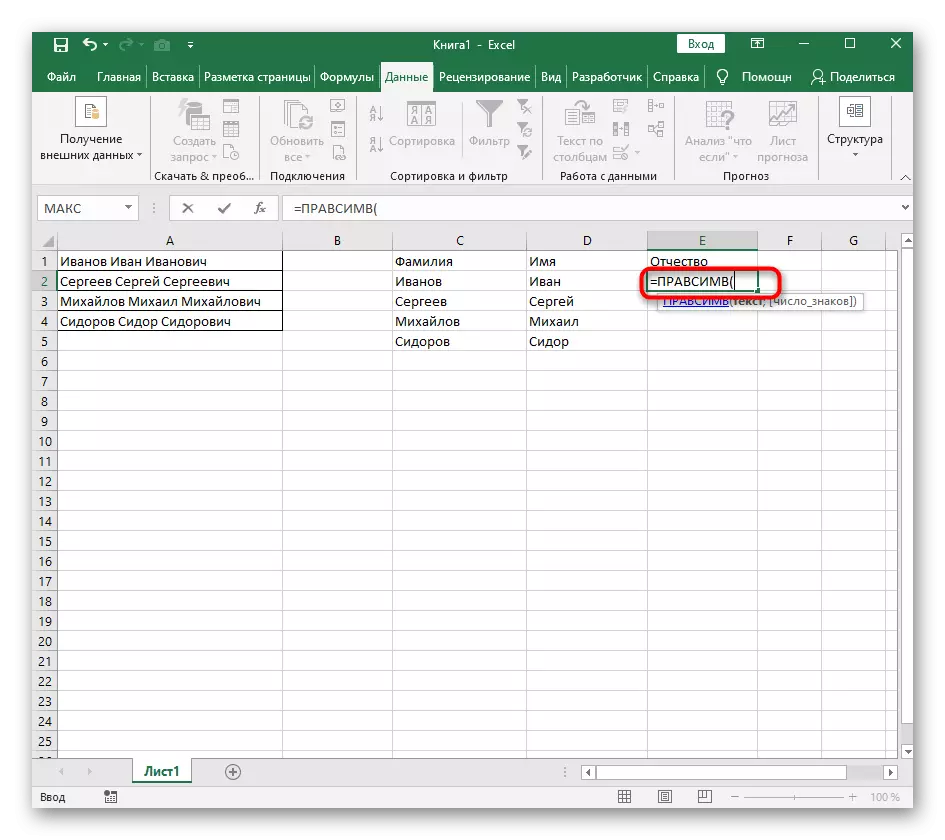
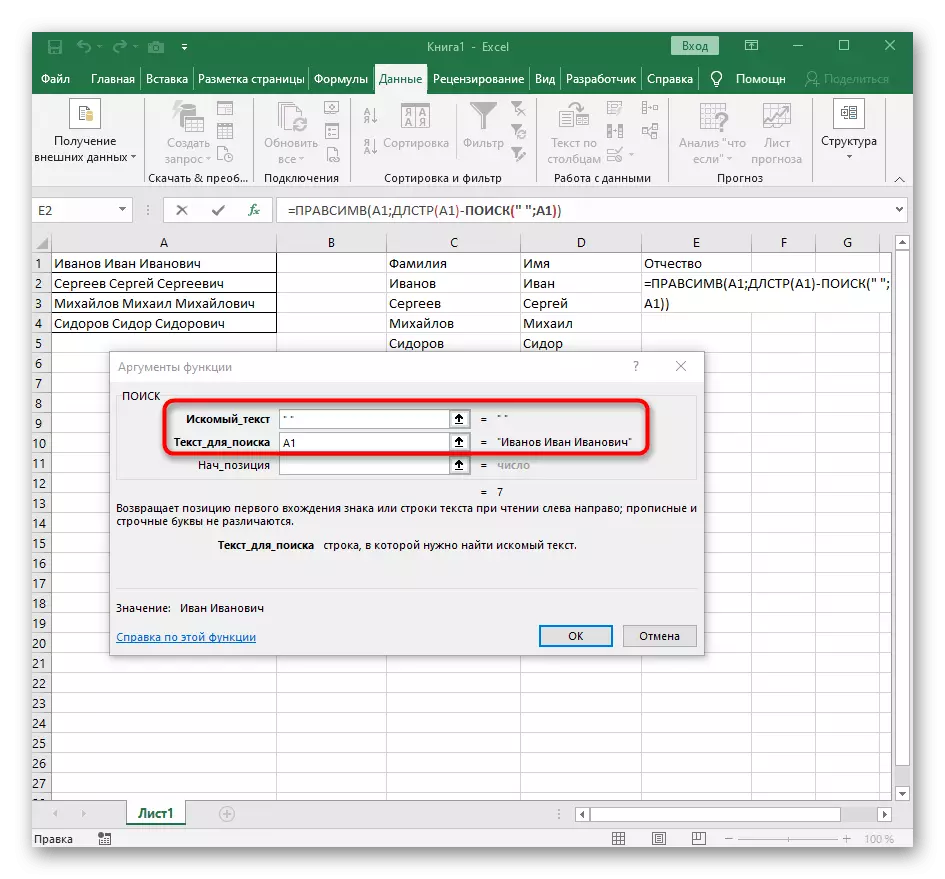
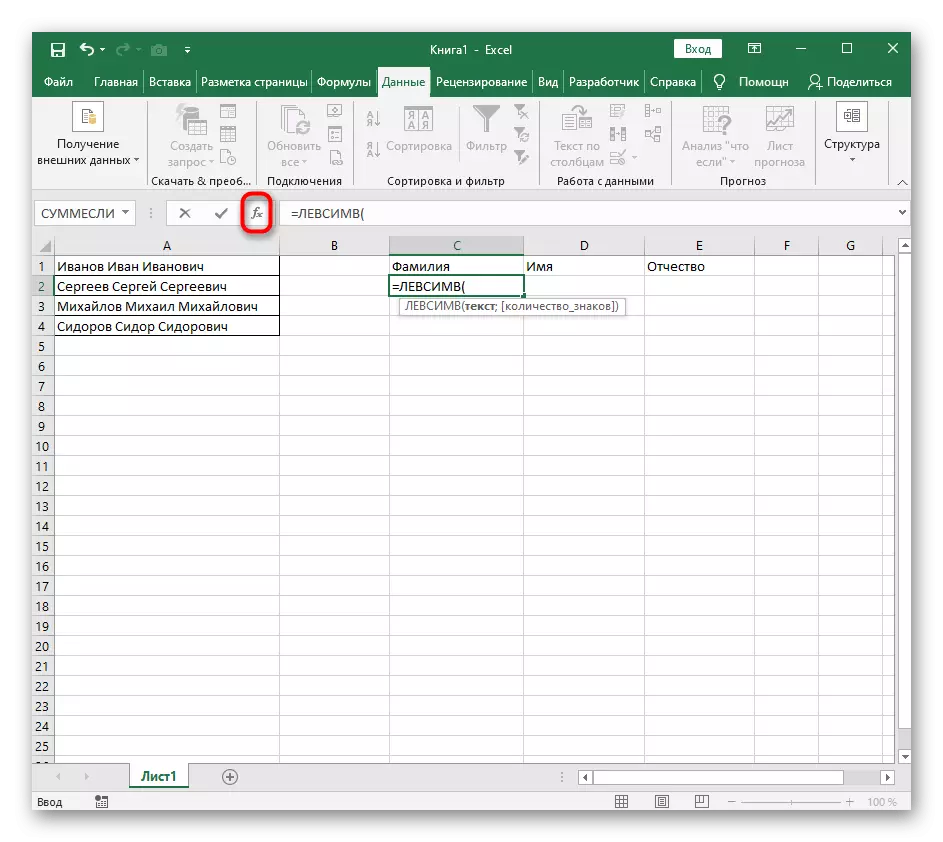
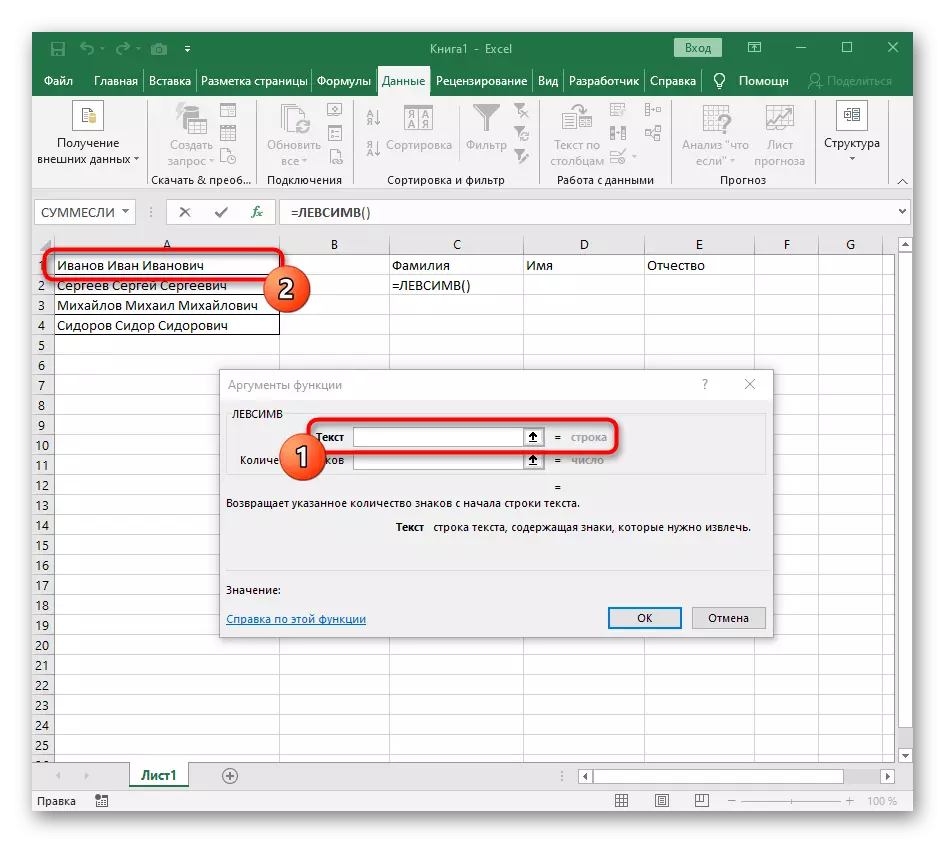
- 첫 번째 단어를 배치 할 셀을 선택하고 수식 = lessimv를 적어 두십시오 (.
- 그런 다음 "옵션 인수"버튼을 누르면 수식의 그래픽 편집 창으로 이동합니다.
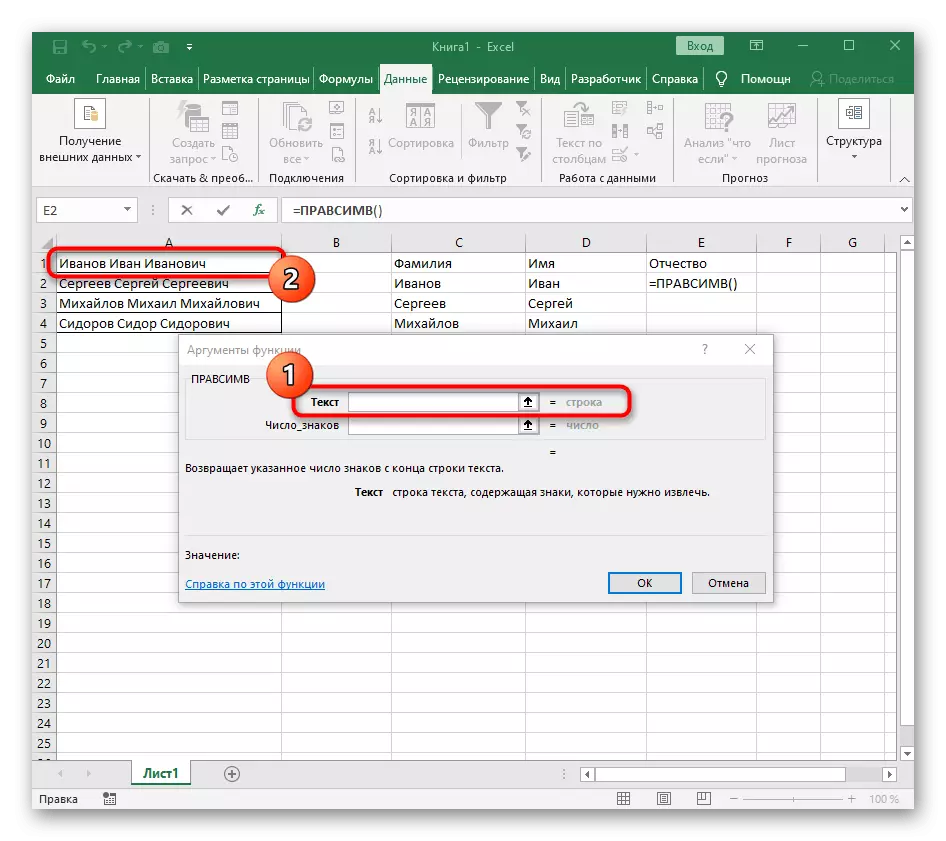
- 인수의 텍스트로 테이블의 왼쪽 마우스 버튼으로 클릭하여 비문으로 셀을 지정하십시오.
- 공간 또는 다른 구분 기호에 대한 징후 수는 계산해야하지만 수동으로 우리는이 작업을 수행하지 않을 것입니다. 그러나 우리는 다른 수식 ()을 사용할 것입니다.
- 이러한 형식으로 녹음하자마자 셀의 셀의 텍스트에 표시되며 굵게 표시됩니다. 이 기능의 인수로 빠르게 전환하려면 클릭하십시오.
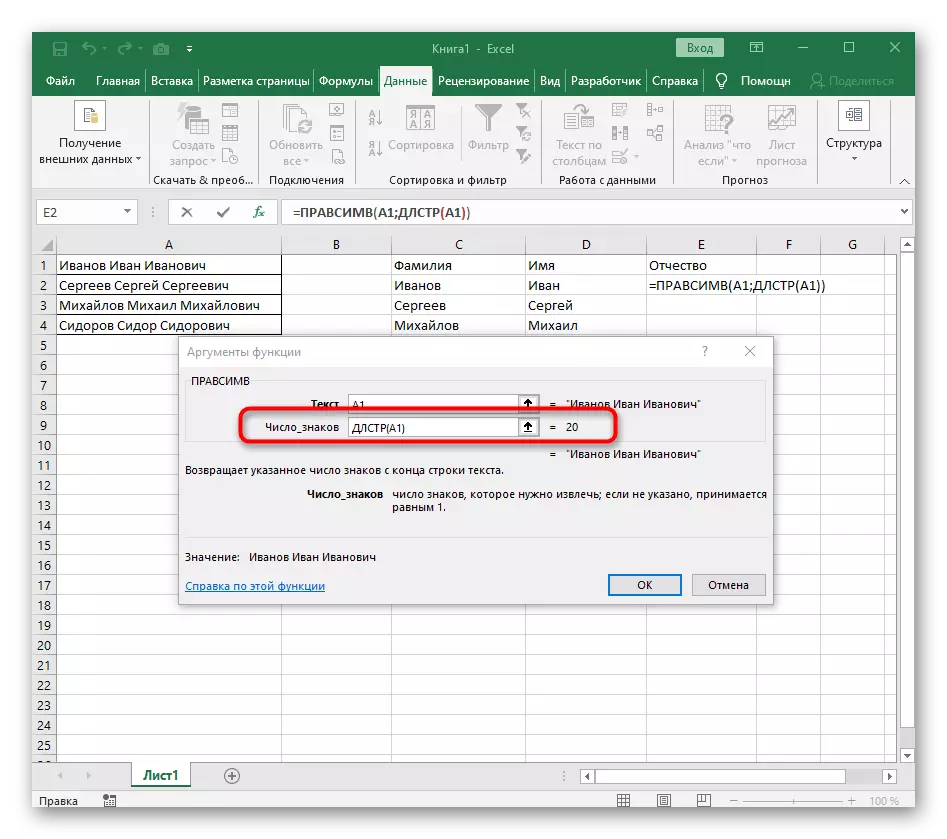
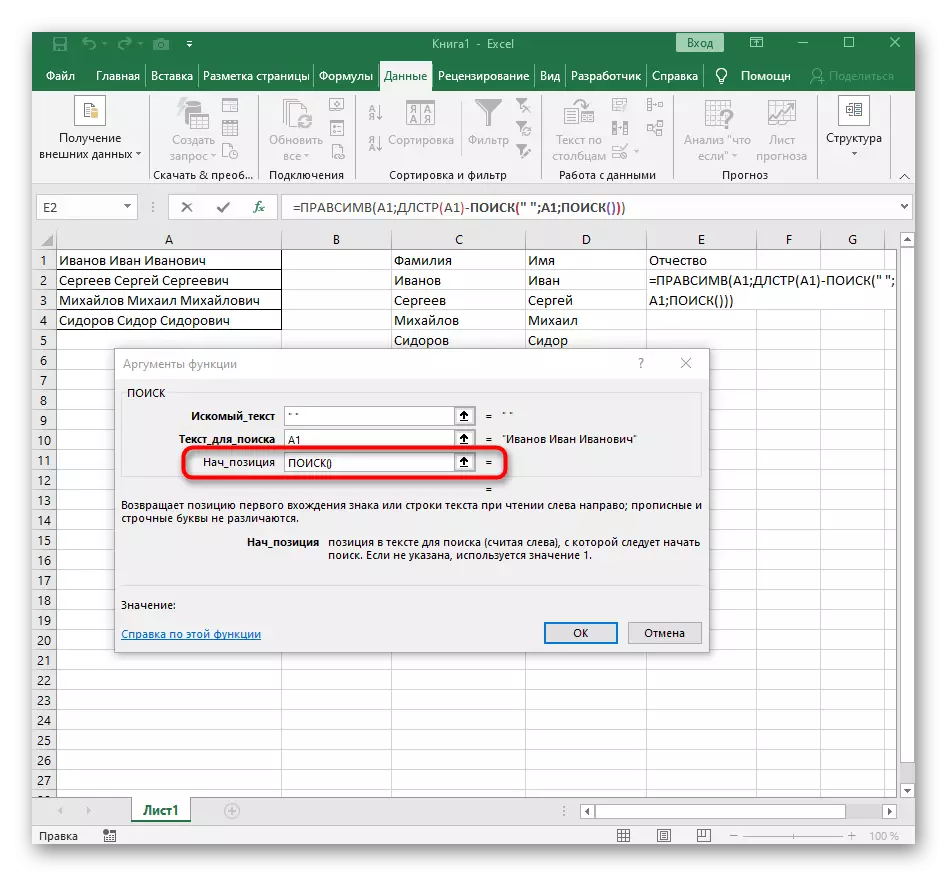
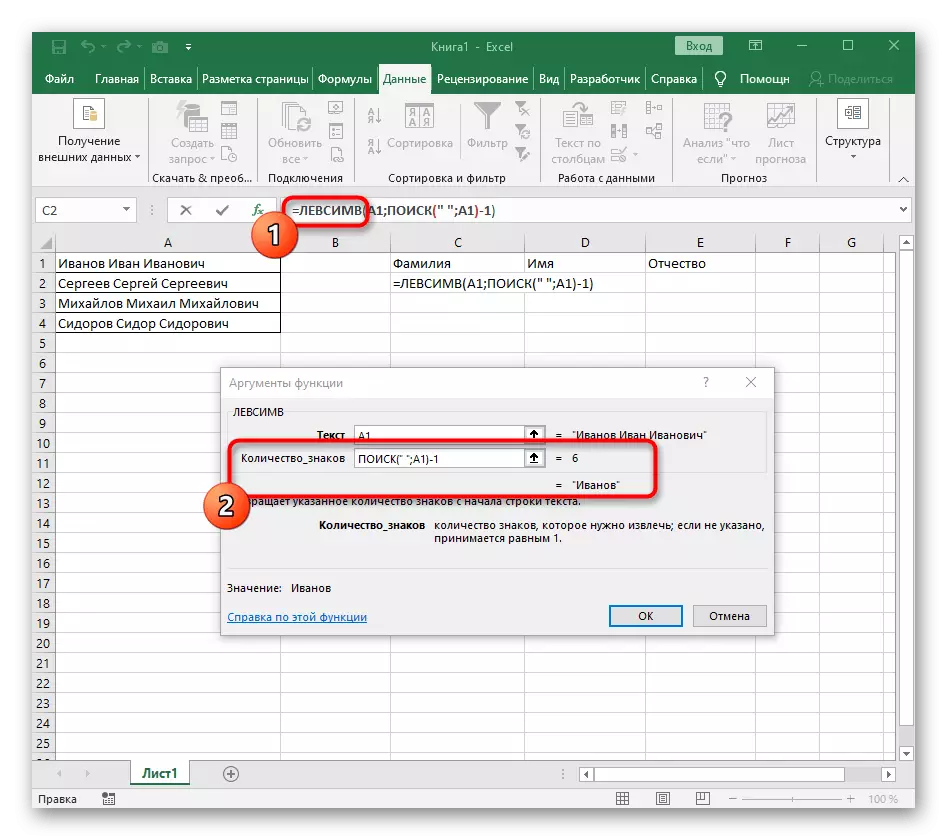
- "뼈대"필드에서는 단순히 단어가 끝나는 위치를 이해하는 데 도움이되므로 공간이나 구분 기호를 사용합니다. "text_-search"에서 처리중인 동일한 셀을 지정합니다.
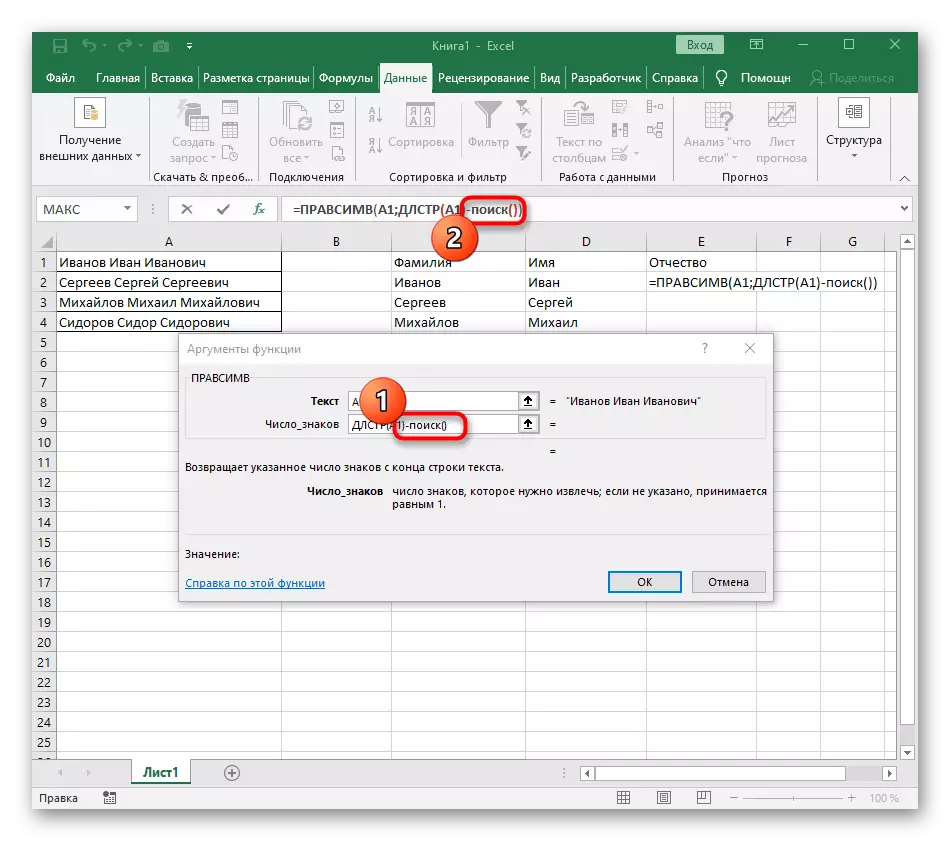
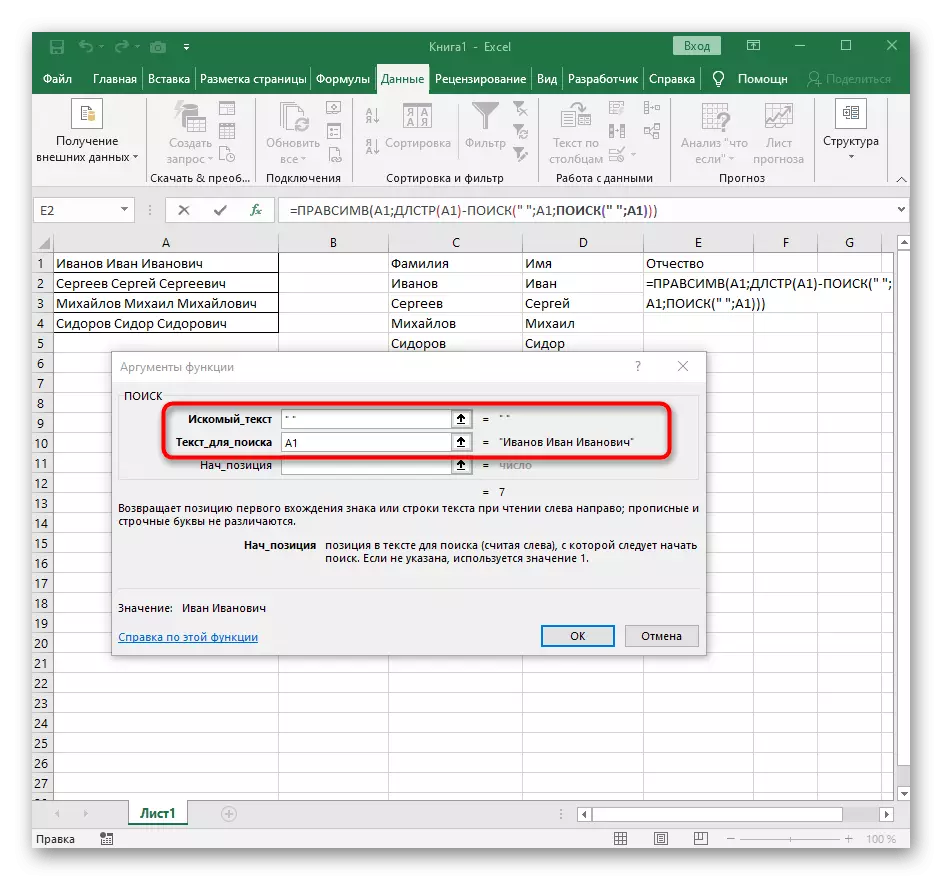
- 첫 번째 함수를 클릭하여 해당 함수로 돌아가서 두 번째 인수 -1의 끝에 추가하십시오. -1. 이는 검색 수식이 원하는 공간이 아닌 것을 고려하기 위해서는 필요합니다. 다음 스크린 샷에서 볼 수 있듯이 공백없이 결과가 표시되므로 수식 컴파일이 올바르게 만들어 졌음을 의미합니다.
- 함수 편집기를 닫고 단어가 새 셀에 올바르게 표시되는지 확인하십시오.
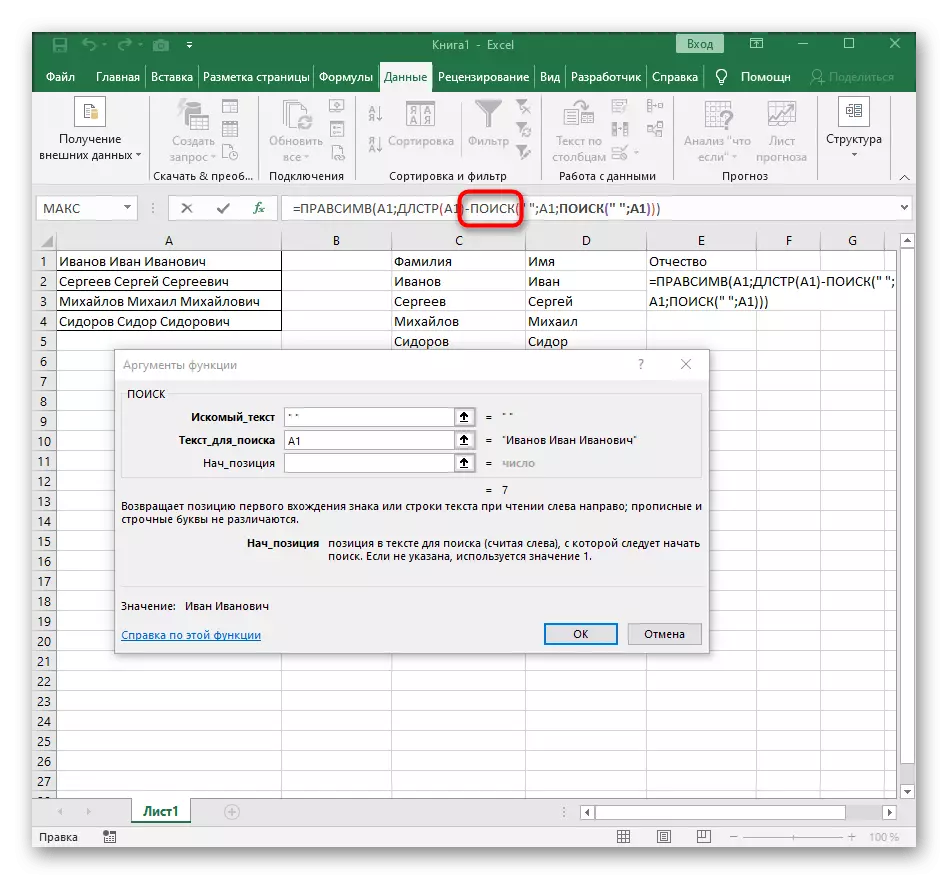
- 오른쪽 하단 모서리에 셀을 잡고 필요한 수의 행 수로 드래그하여 스트레칭하십시오. 따라서 다른 표현의 값이 대체되어 있어야하며 분할되어야하며 공식의 이행은 자동으로됩니다.




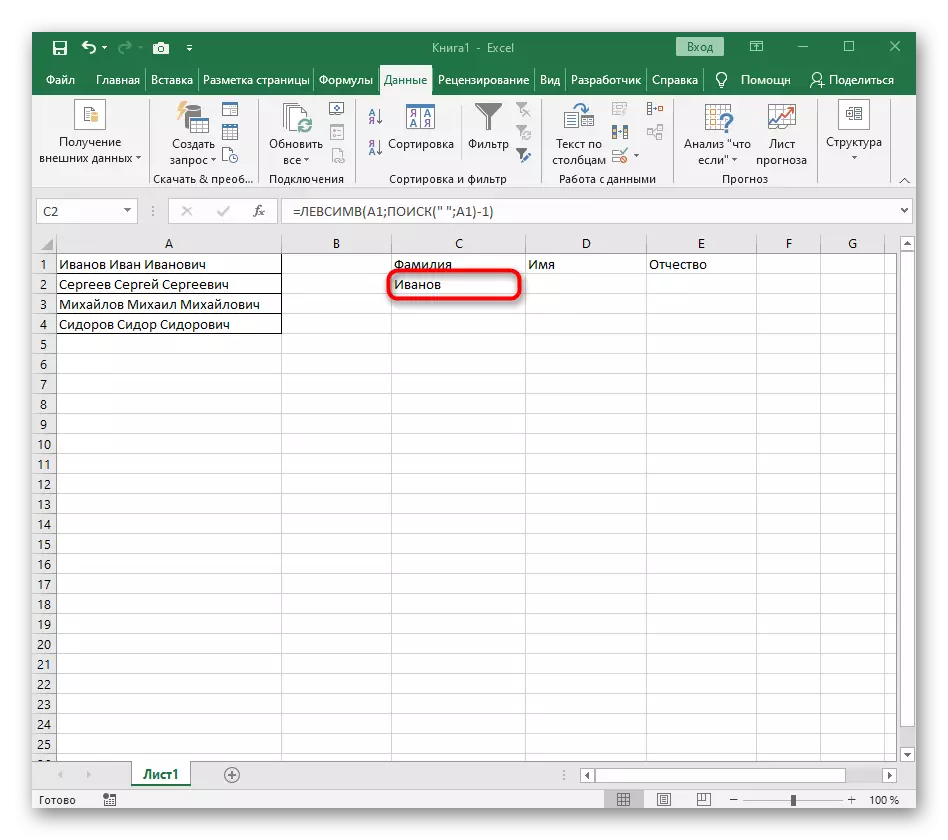

완전히 생성 된 수식에는 = Levsimv (A1; 검색 ( ""A1) -1)을 가지며 조건 및 구분 기호가 적합한 경우 위의 지침에 따라 그것을 만들거나 삽입 할 수 있습니다. 가공 된 셀을 교체하는 것을 잊지 마십시오.
2 단계 : 두 번째 단어의 분리
가장 어려운 것은 우리의 경우에 우리의 경우의 이름은 두 번째 단어를 나누는 것입니다. 이는 양측의 공간으로 둘러싸여 있기 때문에 위치의 올바른 계산을위한 대규모 공식을 만들어 둘 다 고려해야합니다.
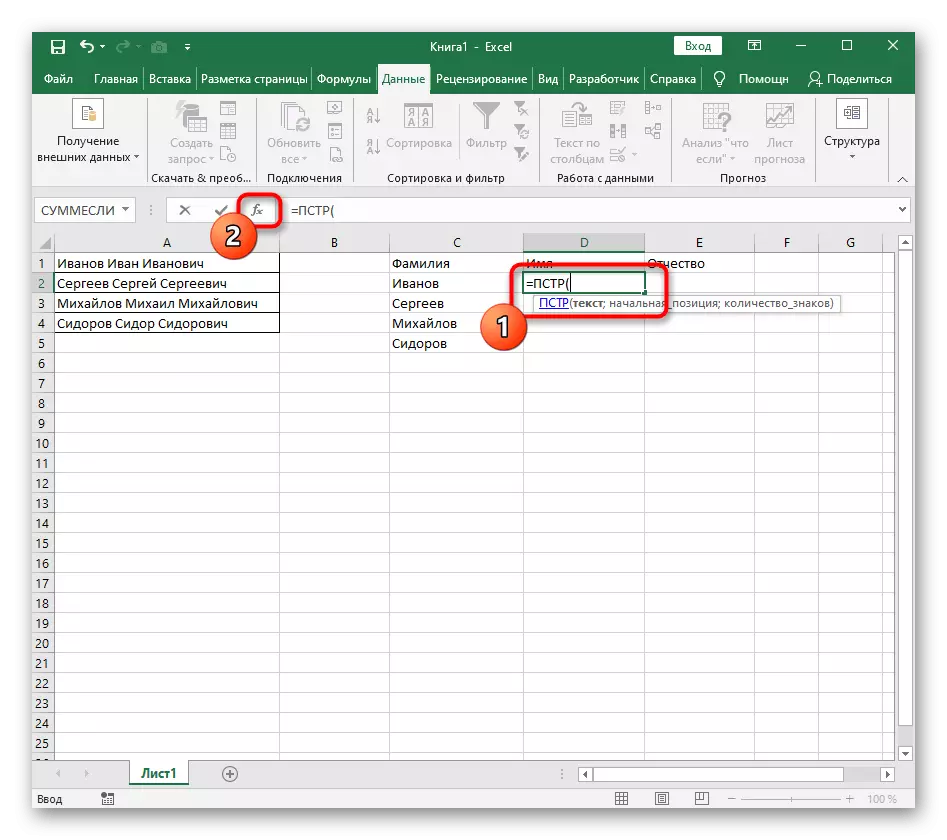
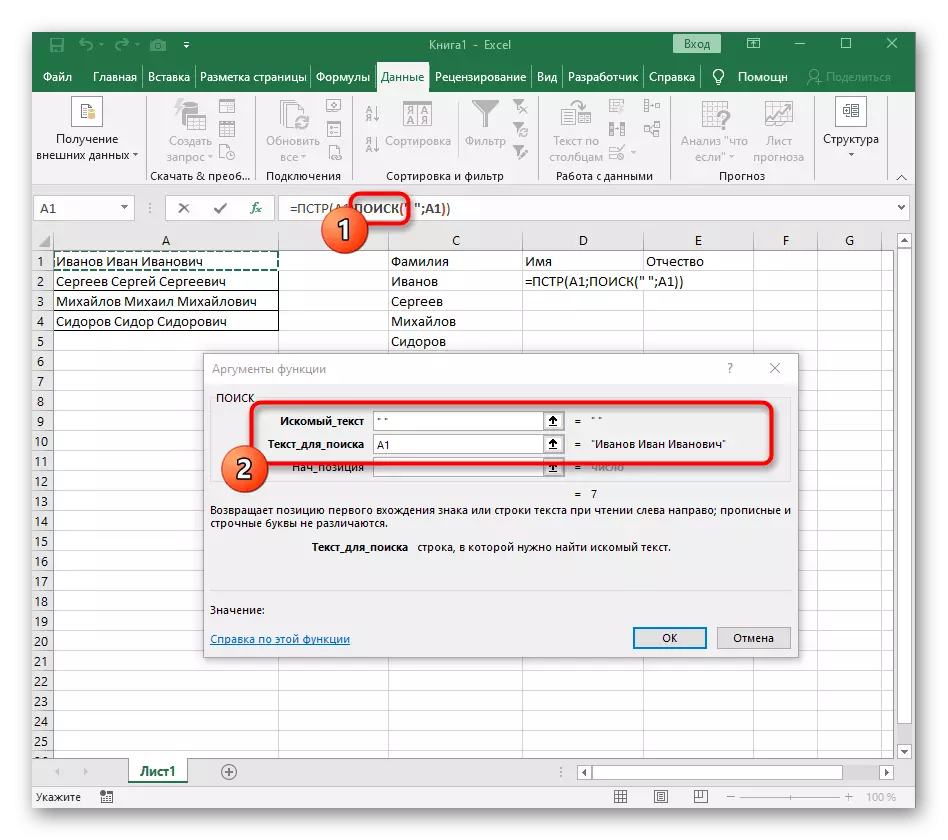
- 이 경우 메인 수식은 = PST (-이 양식에 씁니다) 다음 인수 설정 창으로 이동합니다.
- 이 공식은 분리에 대한 비문이있는 셀에서 선택한 텍스트에서 원하는 문자열을 검색합니다.
- 선의 초기 위치는 이미 익숙한 보조 수식 검색 ()을 사용하여 결정해야합니다.
- 그 향해 만들고 움직이는 것은 이전 단계에 표시된 것과 같은 방식으로 채 웁니다. 원하는 텍스트로 구분 기호를 사용하고 검색 할 텍스트로 셀을 지정하십시오.
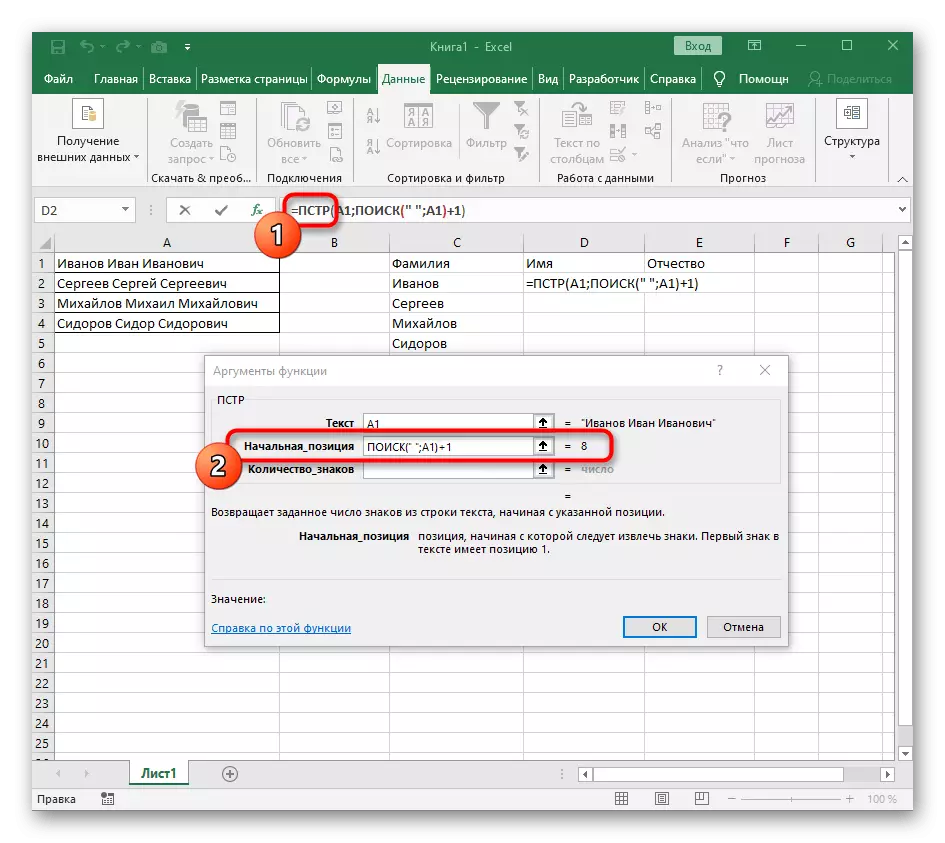
- 마지막에 "검색"기능 +1에 추가하여 발견 된 공간 후 다음 문자로부터 계정을 시작하는 이전 수식으로 돌아갑니다.
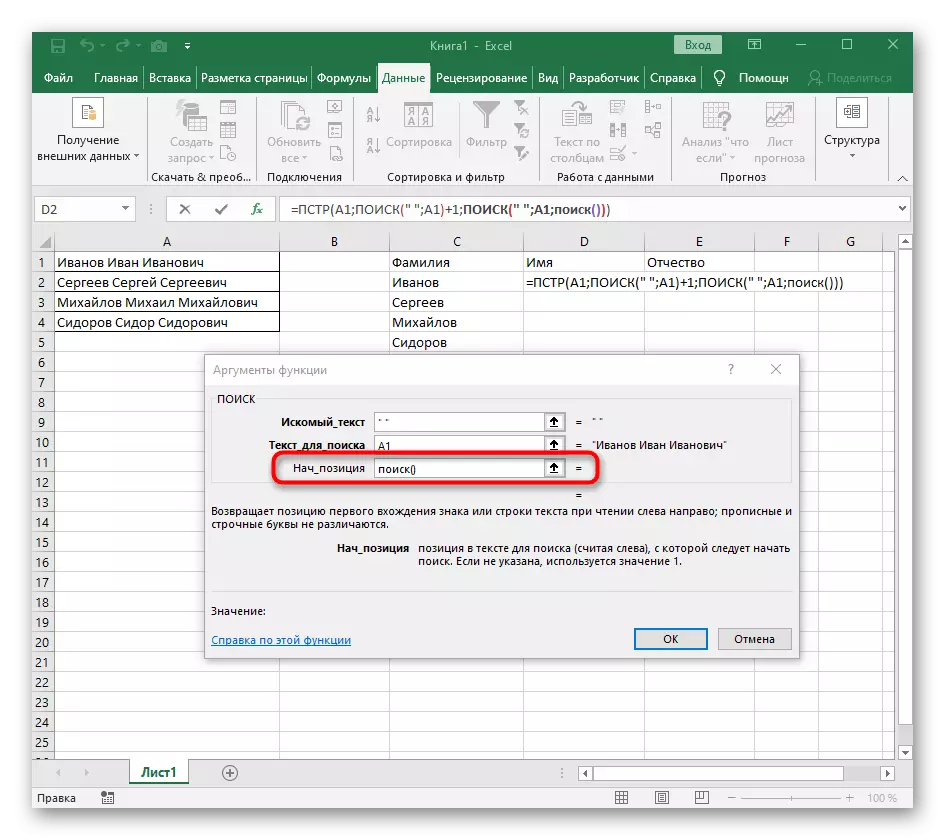
- 이제 수식은 이미 첫 번째 문자 이름에서 라인을 검색하기 시작할 수 있지만 여전히 위치를 완성 할 위치를 알지 못해 "actument_names"필드에서 검색 수식 ()을 씁니다.
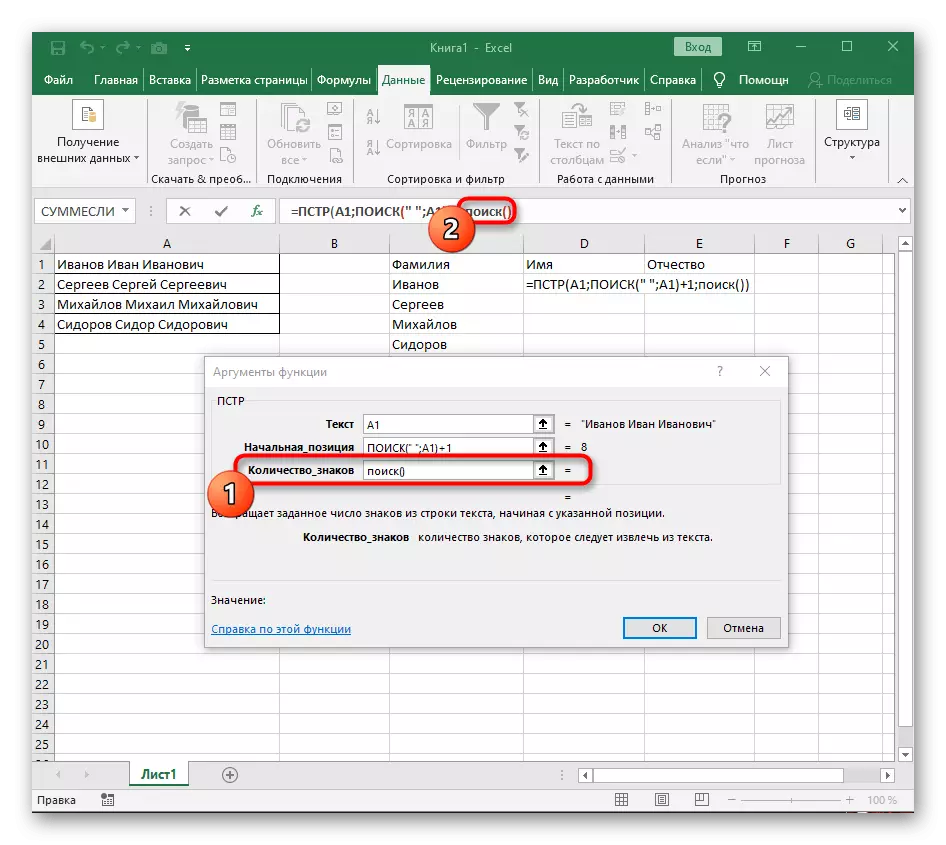
- 인수로 가서 이미 익숙한 형태로 채 웁니다.
- 이전에는이 기능의 초기 위치를 고려하지 않았지만 이제는 검색 ()을 입력해야합니다.이 수식은 첫 번째 갭을 찾지 않아야하지만 두 번째로 인해 검색이 필요합니다.
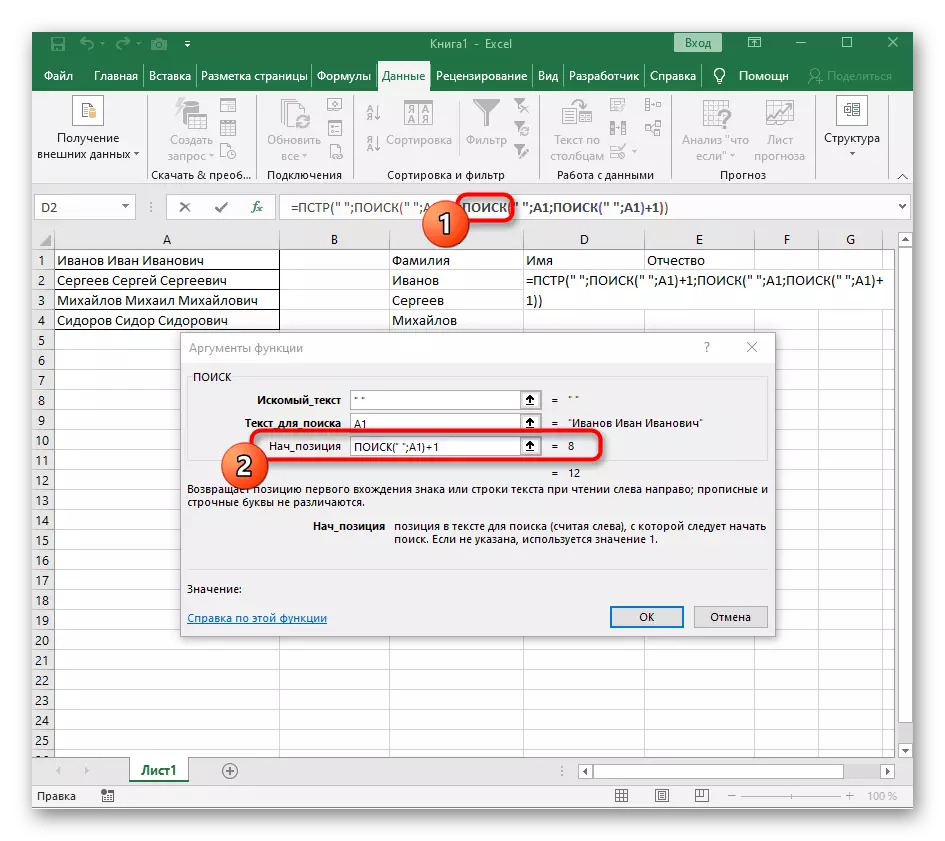
- 생성 된 함수로 이동하여 같은 방식으로 채 웁니다.
- 첫 번째 "검색"으로 돌아가서 줄에 "nach_position"+1에 추가하십시오. 줄을 검색 할 공백이 없지만 다음 문자가 필요하지 않기 때문입니다.
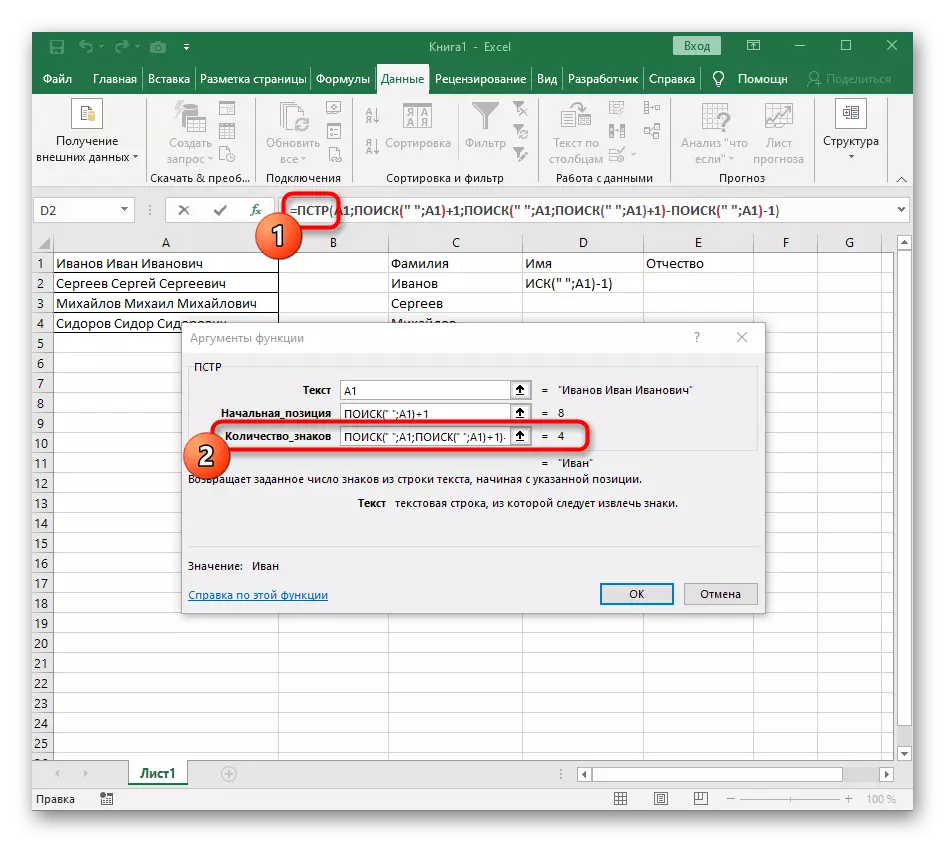
- root = pst를 클릭하고 "number_names"라인의 끝에 커서를 놓습니다.
- 공간의 계산을 완료하기 위해 표현식 ( ""; a1) -1의 표현식을 추출하십시오.
- 테이블로 돌아가서 수식을 늘리고 단어가 올바르게 표시되는지 확인하십시오.


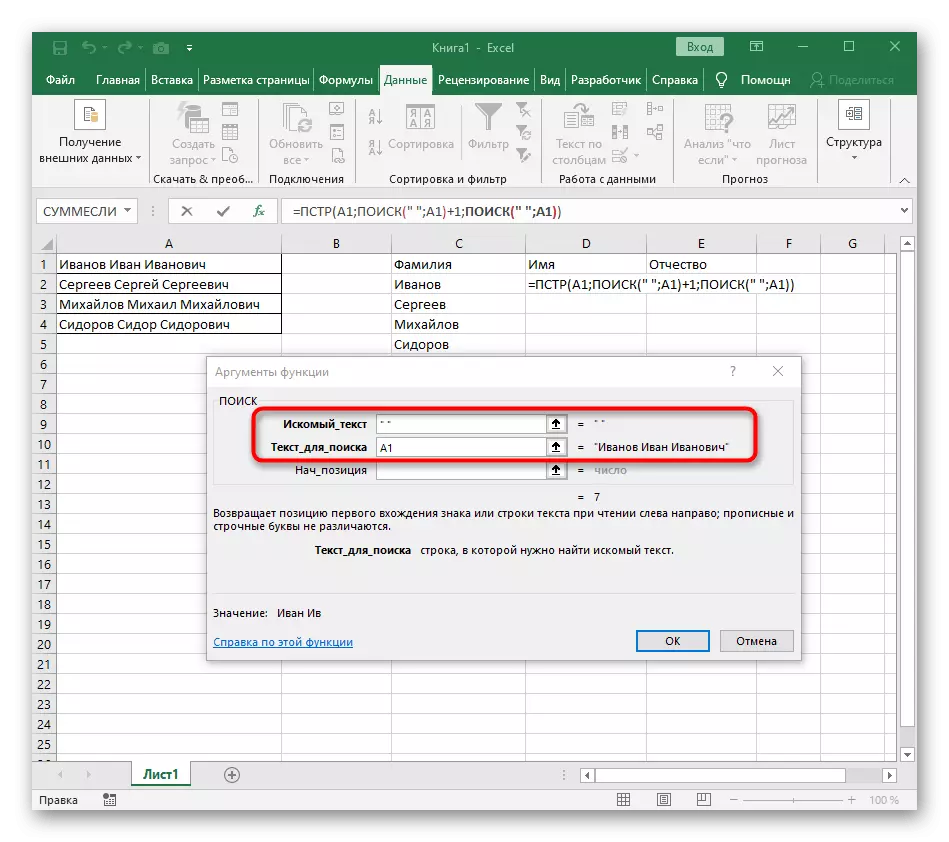

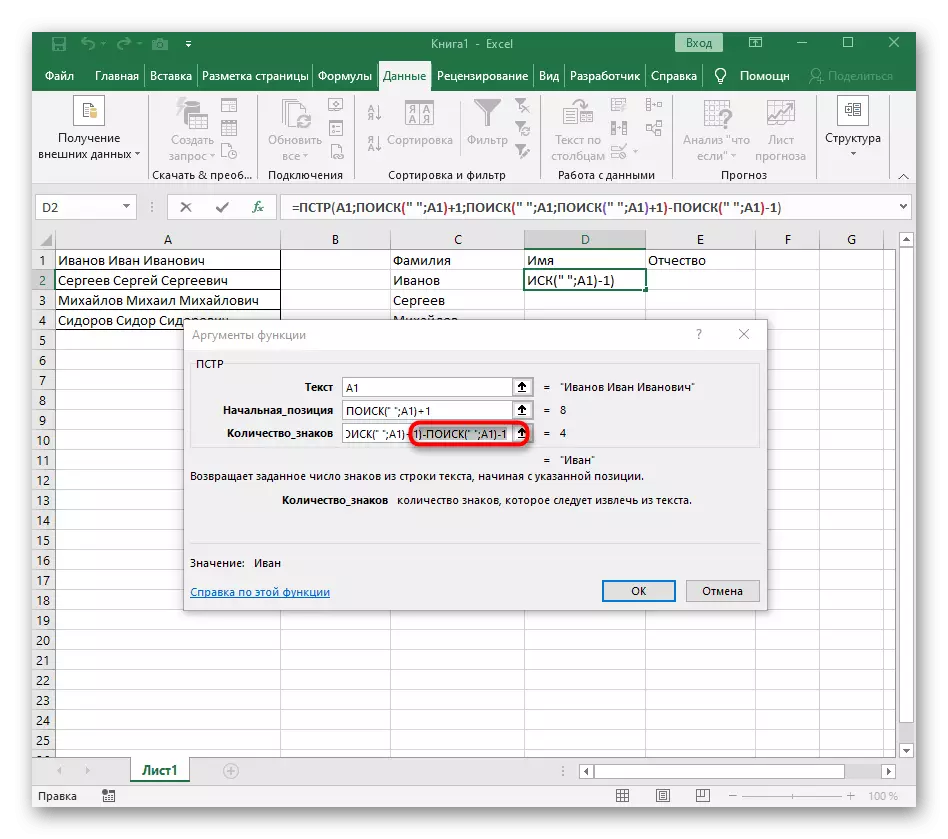
공식은 큰 밝혀졌다, 그리고 모든 사용자가 작동 정확히 이해합니다. 사실은 내가 공간의 초기 및 최종 위치를 확인한 다음 하나 개의 심볼이 결과로, 이들 대부분의 격차가 표시 한만큼 그들로부터 빼앗아 여러 가지 기능을 사용했다 라인을 검색 할 수 있다는 것입니다. 검색 ( ""; A1) +1, 검색 ( ""; A1, 검색 ( ""; A1) +1) -Poisk ( ""= PSTr (A1 A1) - : 따라서, 화학식이 인 1). 텍스트와 함께 휴대폰 번호를 대체 예제로 사용합니다.
3 단계 : 세 번째 단어의 분리
예문의 마지막 단계는 상기 제 일어난 것과 같은 방법에 대해 보이는 제 단어의 분할을 의미하지만, 화학식 약간 변경한다.
- 빈 셀에, 미래 텍스트의 위치, 쓰기 Rashesimv을 = (이 함수의 인수로 이동합니다.
- 텍스트로, 분리를위한 비문 셀을 지정합니다.
- 단어를 찾는 시간이 보조 기능 DLSTR A1 텍스트와 같은 세포 인 (A1)이라고한다. 이 기능은 텍스트의 문자 수를 결정하고, 우리는 적절한 할당 유지됩니다.
- 이렇게하려면 -Poisk ()를 추가하고 편집이 공식을 이동합니다.
- 문자열의 첫 번째 구분을 검색 이미 익숙한 구조를 입력합니다.
- 시작 위치에 대한 다른 검색을 추가 ().
- 그것과 동일한 구조를 지정한다.
- 이전 검색 식으로 돌아갑니다.
- 초기 위치에 +1을 추가합니다.
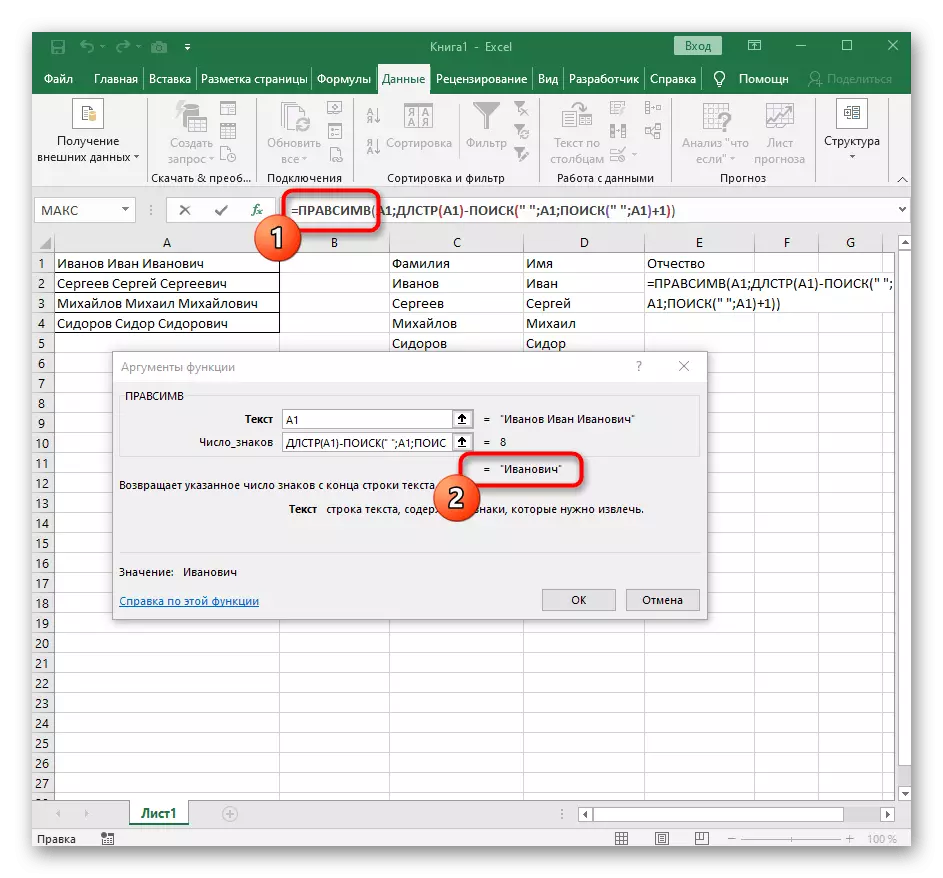
- 공식 Rascessv의 루트로 이동 한 확실한 결과가 제대로 표시되어 있는지 확인하고 변경 사항을 확인합니다. = Pracemir 등이 경우에 완전한 모습 화학식 (; DLSTR (A1) -Poisk ( "A1", A1, 검색 ( ""; A1) +1)).
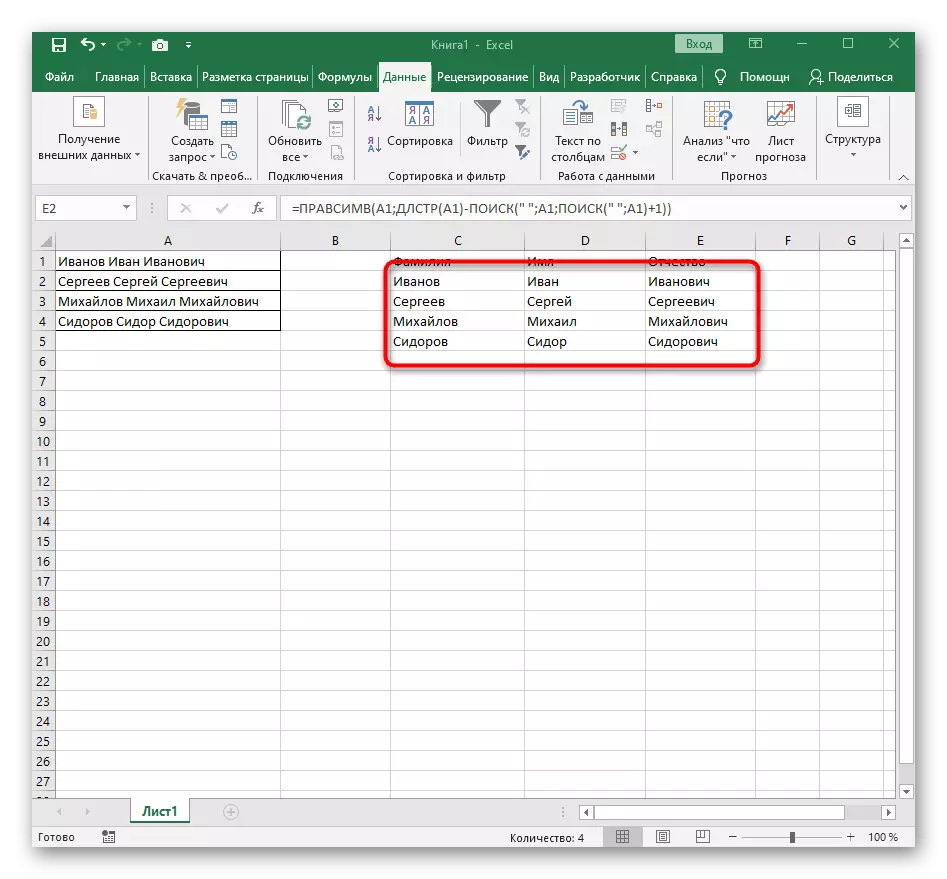
- 결과적으로 다음 스크린 샷에서는 세 단어 모두가 올바르게 분리되어 열에있는 것입니다. 이를 위해 다양한 수식 및 보조 기능을 사용해야했지만 테이블을 동적으로 확장 할 수 있으며 텍스트를 다시 공유 할 때마다 걱정할 수 없습니다. 필요한 경우 다음 셀이 자동으로 영향을 받아야하므로 수식을 이동하여 수식을 확장하십시오.