विधि 1: एक स्वचालित उपकरण का उपयोग करना
एक्सेल में कॉलम में टेक्स्ट को विभाजित करने के लिए डिज़ाइन किया गया एक स्वचालित टूल है। यह स्वचालित रूप से काम नहीं करता है, इसलिए संसाधित डेटा की सीमा का चयन करने के लिए सभी कार्यों को मैन्युअल रूप से किया जाना चाहिए। हालांकि, कार्यान्वयन में सेटिंग सबसे सरल और तेज़ है।
- बाएं माउस बटन के साथ, उन सभी कोशिकाओं का चयन करें जिनके टेक्स्ट आप कॉलम पर विभाजित करना चाहते हैं।
- इसके बाद, टैब "डेटा" पर जाएं और "कॉलम टू कॉलम" बटन पर क्लिक करें।
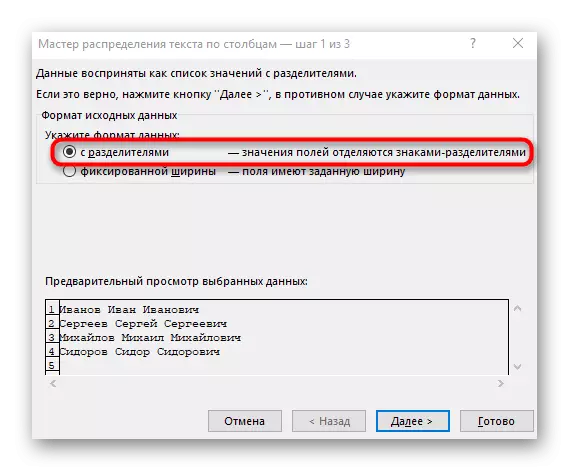
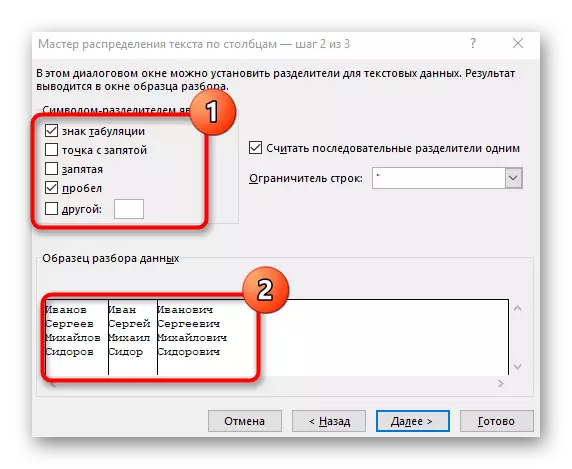
- "कॉलम टेक्स्ट विज़ार्ड" विंडो दिखाई देती है, जिसमें आप "विभाजक के साथ" डेटा प्रारूप का चयन करना चाहते हैं। विभाजक अक्सर अंतरिक्ष करता है, लेकिन यदि यह एक और विराम चिह्न चिह्न है, तो आपको इसे अगले चरण में निर्दिष्ट करने की आवश्यकता होगी।
- अनुक्रम प्रतीक जांचें या मैन्युअल रूप से इसे दर्ज करें, और फिर नीचे की खिड़की में प्रारंभिक पृथक्करण परिणाम पढ़ें।
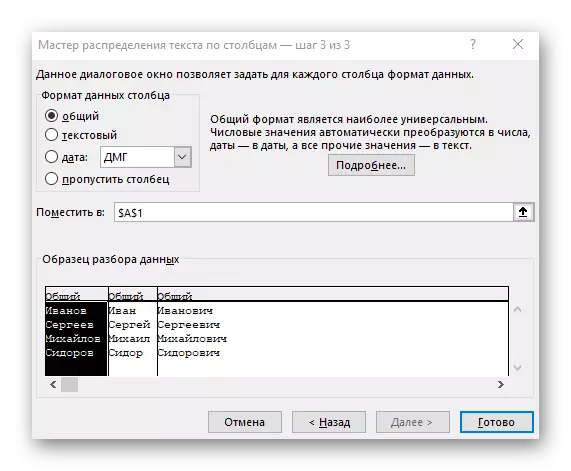
- अंतिम चरण में, आप एक नया कॉलम प्रारूप और एक स्थान निर्दिष्ट कर सकते हैं जहां उन्हें रखा जाना चाहिए। एक बार सेटअप पूरा हो जाने के बाद, सभी परिवर्तनों को लागू करने के लिए "समाप्त करें" पर क्लिक करें।
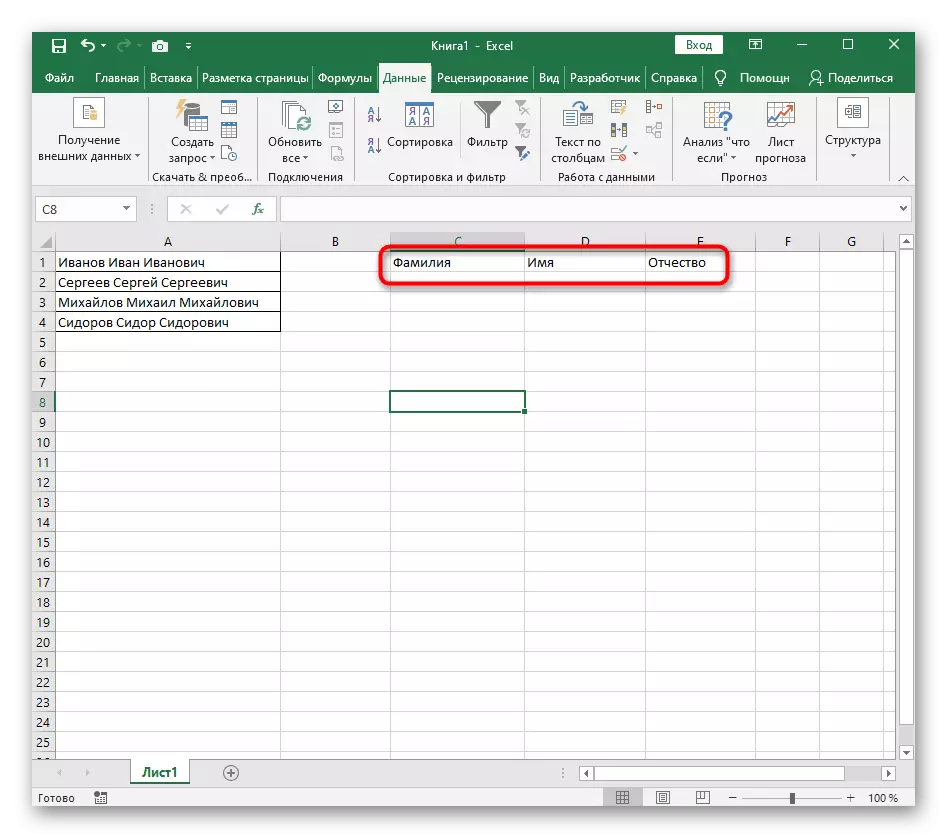
- तालिका में लौटें और सुनिश्चित करें कि अलगाव सफलतापूर्वक पारित हो गया है।


इस निर्देश से, हम निष्कर्ष निकाल सकते हैं कि ऐसे उपकरण का उपयोग उन परिस्थितियों में बेहतर है जहां अलगाव केवल एक बार किया जाना चाहिए, प्रत्येक शब्द को एक नया कॉलम के लिए दर्शा रहा है। हालांकि, अगर नए डेटा को टेबल में लगातार पेश किया जाता है, तो उन्हें विभाजित करने के लिए हर समय यह काफी सुविधाजनक नहीं होगा, इसलिए ऐसे मामलों में हम निम्नलिखित तरीके से खुद को परिचित करने का सुझाव देते हैं।
विधि 2: एक पाठ विभाजन सूत्र बनाना
एक्सेल में, आप स्वतंत्र रूप से एक अपेक्षाकृत जटिल सूत्र बना सकते हैं जो आपको सेल में शब्दों की स्थिति की गणना करने, अंतराल ढूंढने और प्रत्येक को अलग-अलग कॉलम में विभाजित करने की अनुमति देगा। उदाहरण के तौर पर, हम एक सेल ले लेंगे जिसमें रिक्त स्थान से अलग तीन शब्द शामिल हैं। उनमें से प्रत्येक के लिए, यह अपना स्वयं का सूत्र लेगा, इसलिए हम विधि को तीन चरणों में विभाजित करते हैं।चरण 1: पहले शब्द का पृथक्करण
पहले शब्द के लिए सूत्र सबसे सरल है, क्योंकि इसे सही स्थिति निर्धारित करने के लिए केवल एक अंतर से पीछे हट जाना होगा। अपने सृजन के प्रत्येक चरण पर विचार करें, ताकि एक पूर्ण तस्वीर का गठन किया गया हो कि कुछ गणना की आवश्यकता है।
- सुविधा के लिए, हस्ताक्षर के साथ तीन नए कॉलम बनाएं जहां हम अलग किए गए टेक्स्ट को जोड़ देंगे। आप इस पल को वही कर सकते हैं या छोड़ सकते हैं।
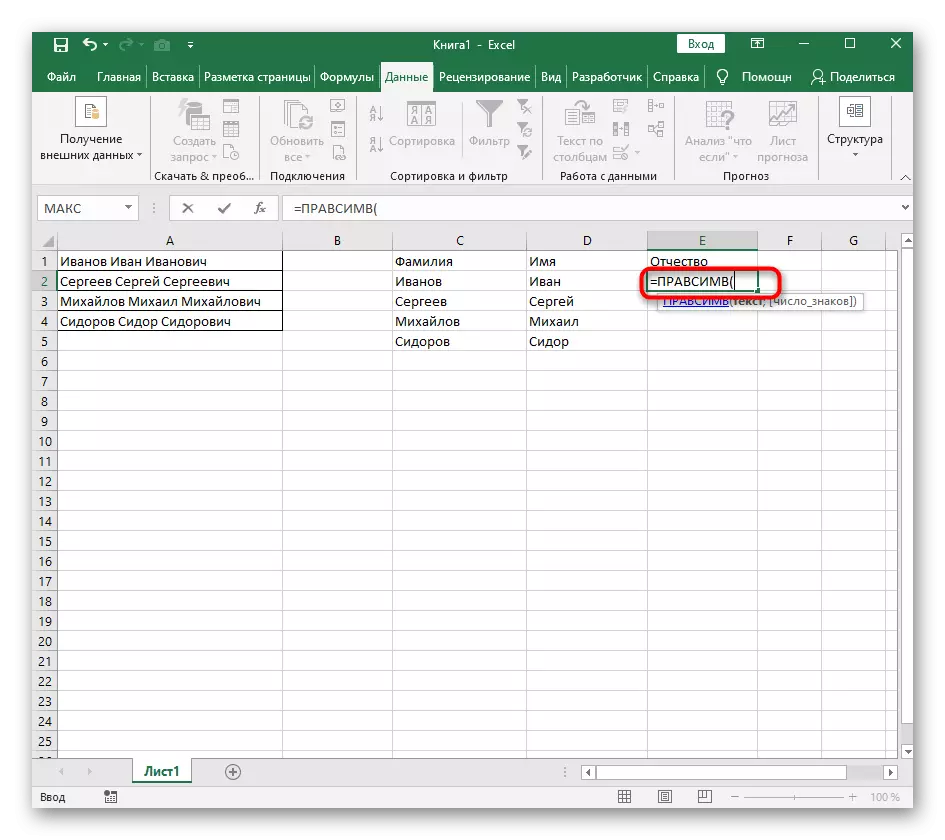
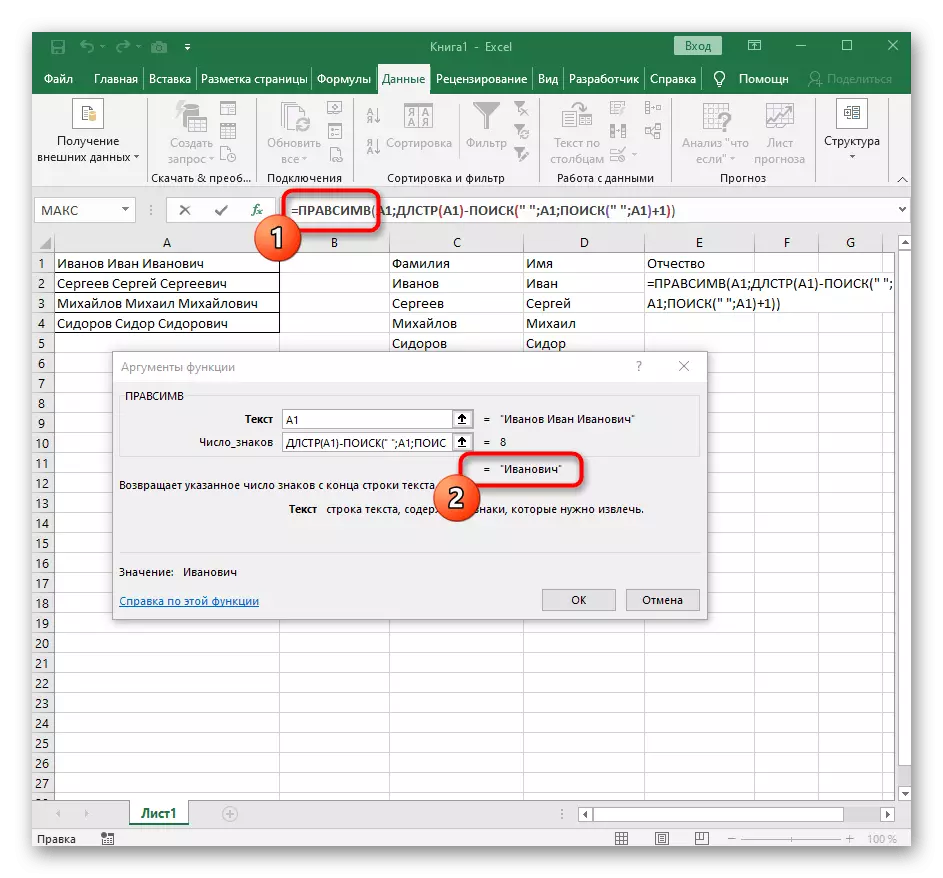
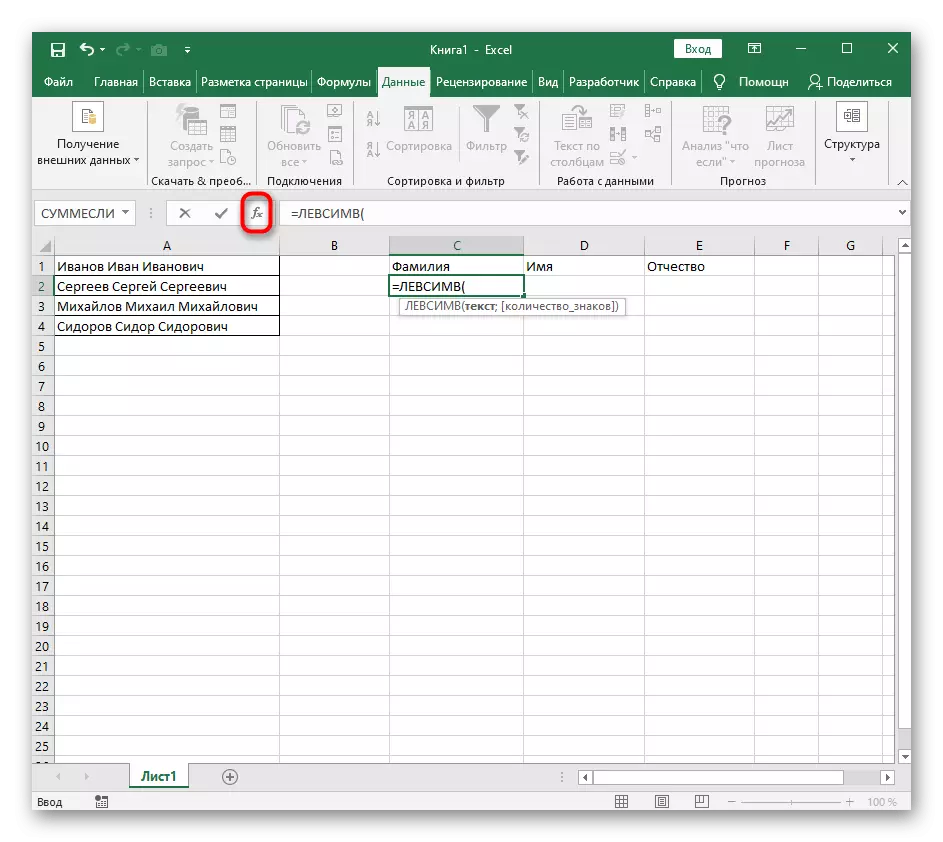
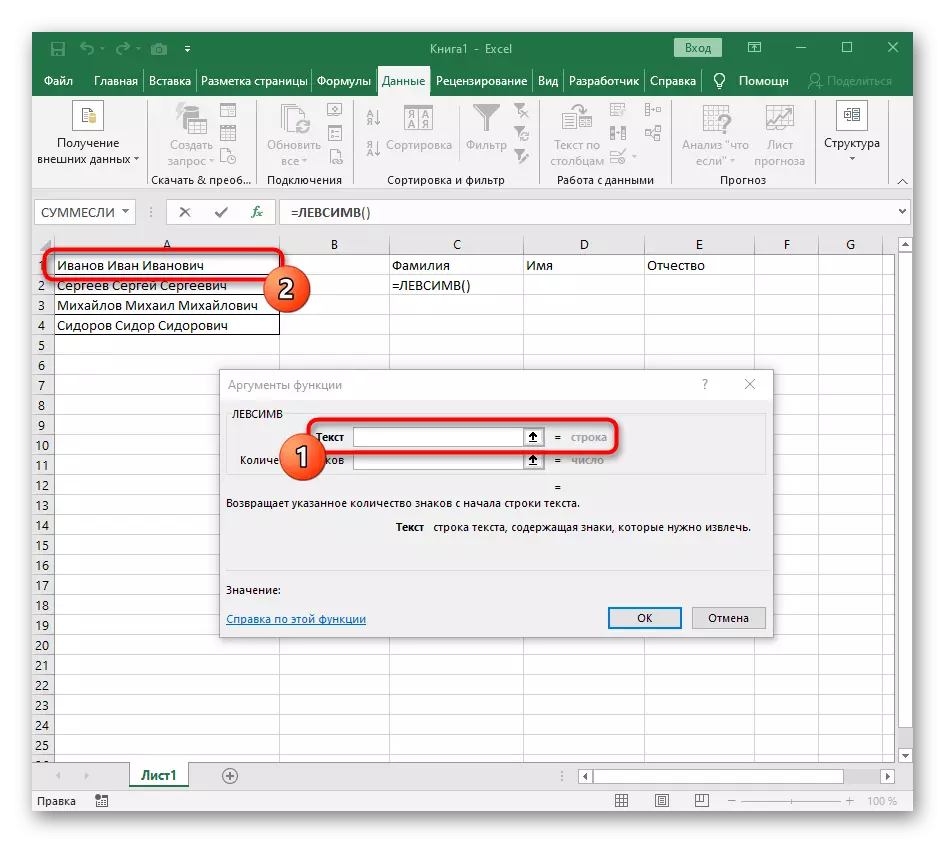
- उस सेल का चयन करें जहां आप पहले शब्द को स्थिति में रखना चाहते हैं, और सूत्र = Lessimv (।
- इसके बाद, "विकल्प तर्क" बटन दबाएं, इस प्रकार फॉर्मूला की ग्राफिक संपादन विंडो में जा रहे हैं।
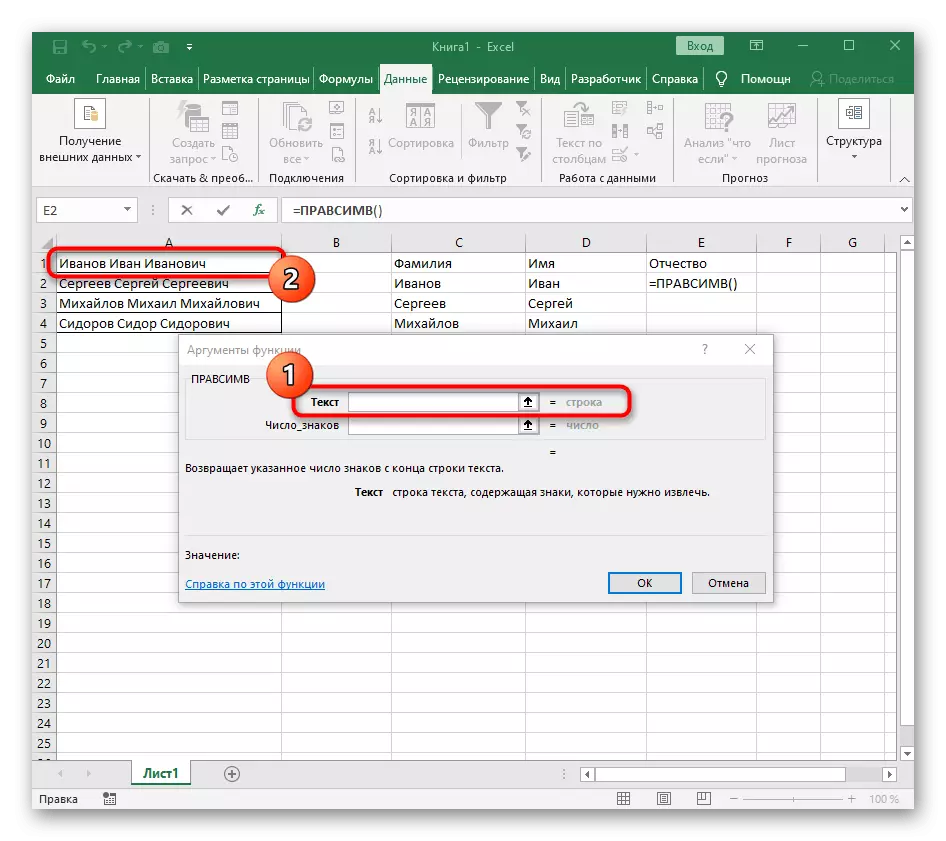
- तर्क के पाठ के रूप में, तालिका पर बाएं माउस बटन के साथ उस पर क्लिक करके शिलालेख के साथ सेल निर्दिष्ट करें।
- किसी स्थान या किसी अन्य विभाजक के संकेतों की संख्या की गणना की जाएगी, लेकिन मैन्युअल रूप से हम ऐसा नहीं करेंगे, लेकिन हम एक और सूत्र - खोज () का उपयोग करेंगे।
- जैसे ही आप इसे ऐसे प्रारूप में रिकॉर्ड करते हैं, यह शीर्ष पर सेल के पाठ में दिखाई देगा और बोल्ड में हाइलाइट किया जाएगा। इस फ़ंक्शन के तर्कों में त्वरित रूप से संक्रमण के लिए उस पर क्लिक करें।
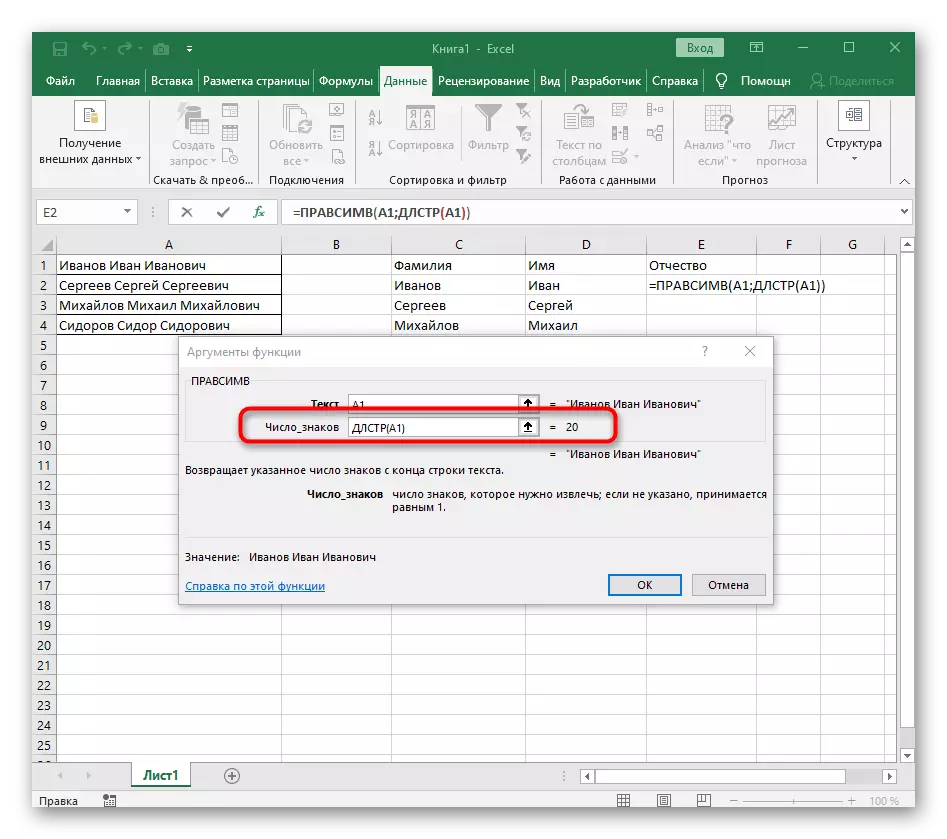
- "कंकाल" फ़ील्ड में बस जगह या विभाजक का उपयोग किया जाता है क्योंकि यह आपको समझने में मदद करेगा कि शब्द कहां समाप्त होता है। "TEXT_-खोज" में एक ही सेल को संसाधित किया जा रहा है।
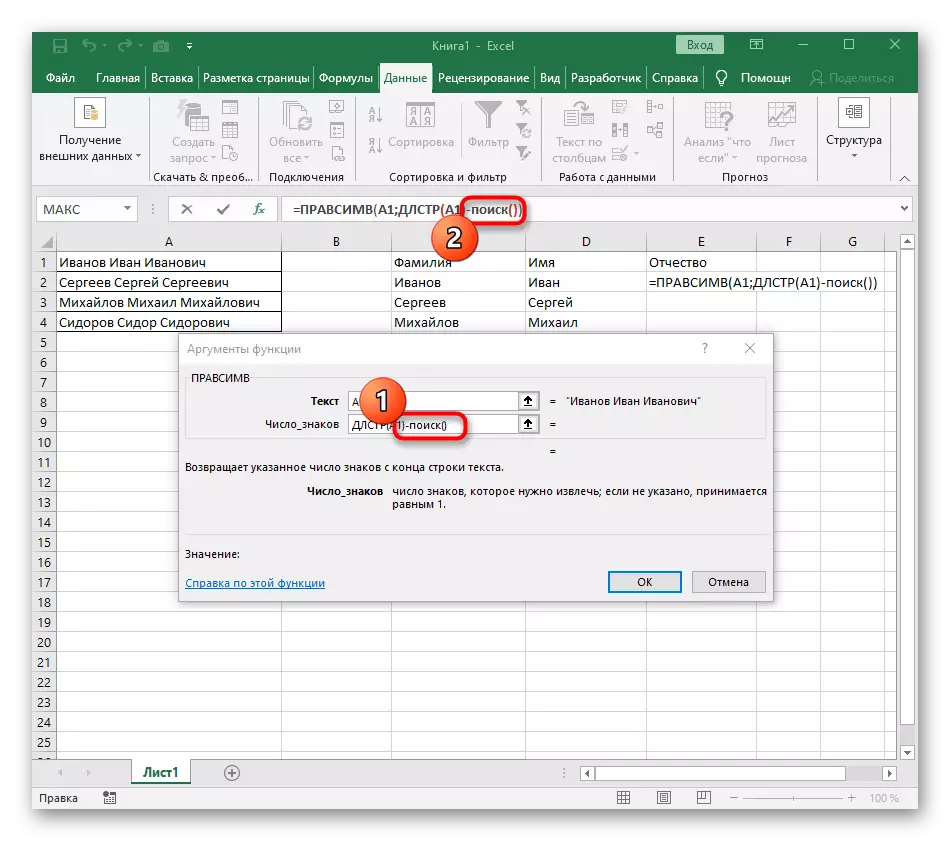
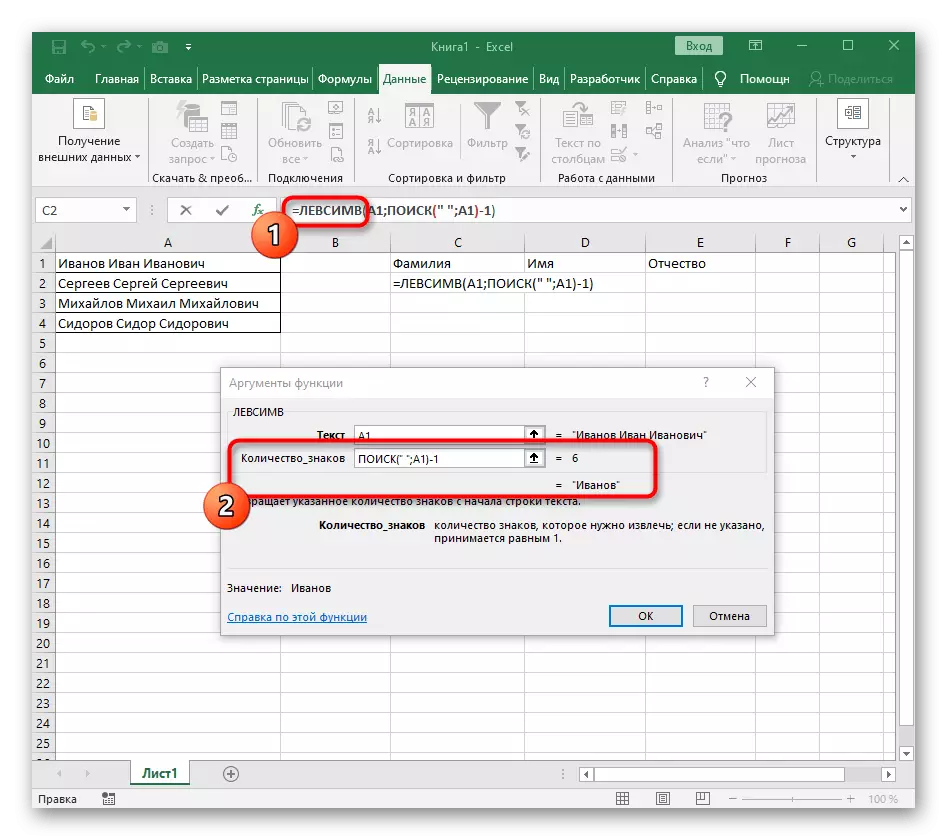
- इसे वापस करने के लिए पहले फ़ंक्शन पर क्लिक करें, और दूसरे तर्क -1 के अंत में जोड़ें। खोज सूत्र के लिए वांछित स्थान नहीं, बल्कि प्रतीक के लिए यह आवश्यक है। जैसा कि निम्नलिखित स्क्रीनशॉट में देखा जा सकता है, परिणाम किसी भी रिक्त स्थान के बिना प्रदर्शित होता है, जिसका अर्थ है कि सूत्र संकलन सही ढंग से किया जाता है।
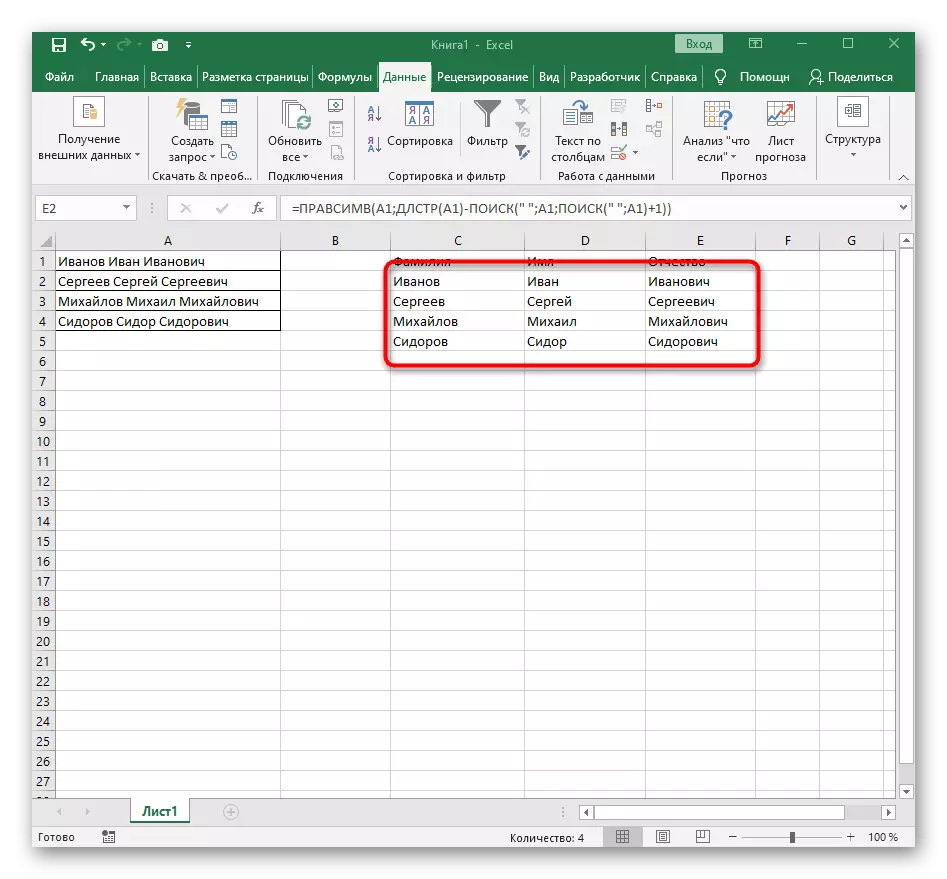
- फ़ंक्शन संपादक को बंद करें और सुनिश्चित करें कि नया सेल में शब्द सही ढंग से प्रदर्शित होता है।
- सेल को निचले दाएं कोने में रखें और इसे खींचने के लिए आवश्यक संख्या में पंक्तियों को खींचें। तो अन्य अभिव्यक्तियों के मूल्यों को प्रतिस्थापित किया गया है, जिसे विभाजित किया जाना चाहिए, और सूत्र की पूर्ति स्वचालित रूप से होती है।




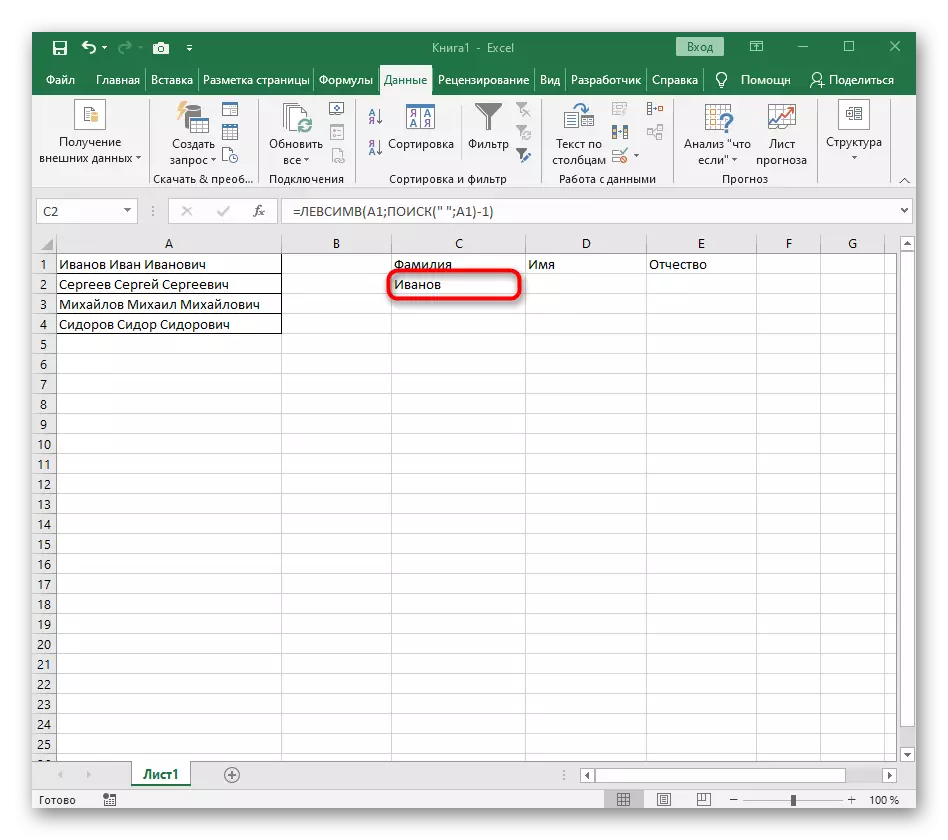

पूरी तरह से बनाई गई सूत्र में फॉर्म = लेवसिम (ए 1; खोज (""; ए 1) -1) है, आप इसे उपरोक्त निर्देशों के अनुसार बना सकते हैं या यदि शर्तें और विभाजक उपयुक्त हैं तो इसे सम्मिलित करें। संसाधित सेल को बदलने के लिए मत भूलना।
चरण 2: दूसरे शब्द का पृथक्करण
सबसे कठिन बात यह है कि दूसरे शब्द को विभाजित करना, जो हमारे मामले में नाम है। यह इस तथ्य के कारण है कि यह दोनों तरफ से रिक्त स्थान से घिरा हुआ है, इसलिए आपको दोनों को ध्यान में रखना होगा, स्थिति की सही गणना के लिए एक विशाल सूत्र बनाना।
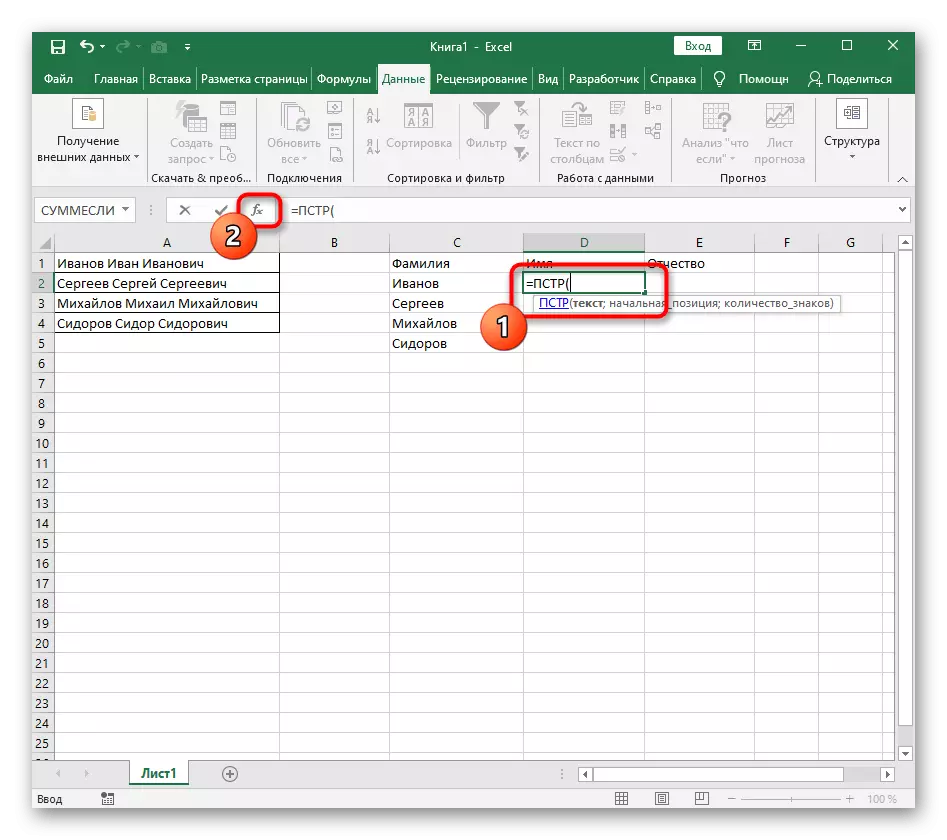
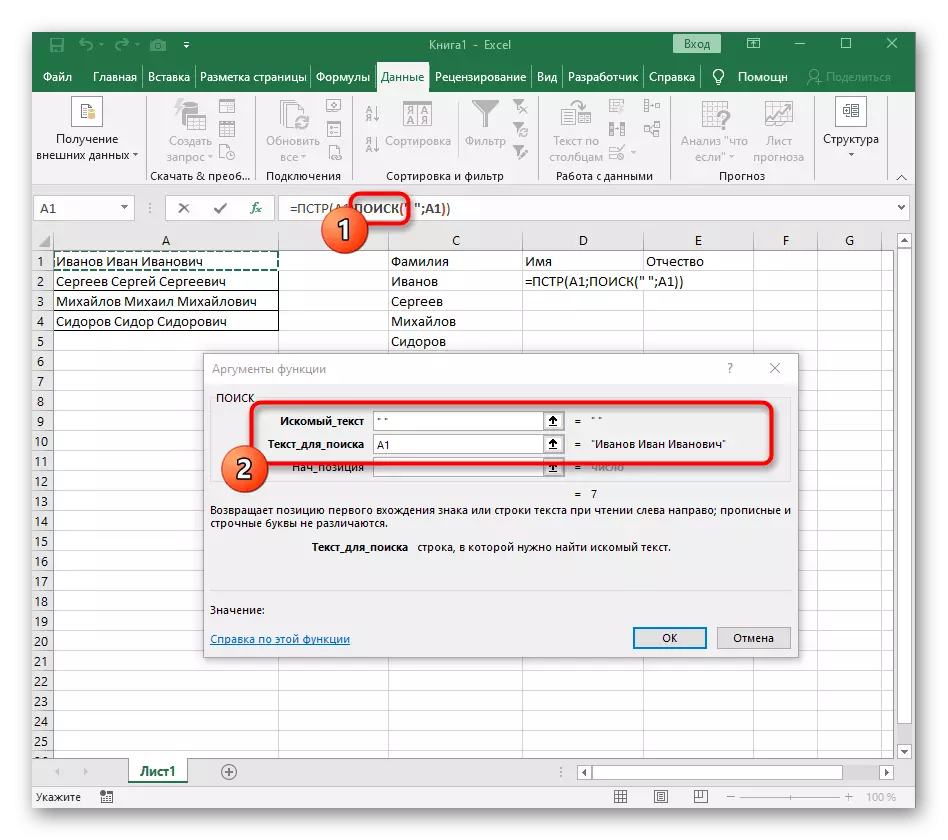
- इस मामले में, मुख्य सूत्र = पीएसटी होगा (- इसे इस फॉर्म में लिखें, और फिर तर्क सेटिंग्स विंडो पर जाएं।
- यह सूत्र पाठ में वांछित स्ट्रिंग की खोज करेगा, जिसे सेल द्वारा अलगाव के लिए शिलालेख के साथ चुना जाता है।
- लाइन की प्रारंभिक स्थिति को पहले से परिचित सहायक सूत्र खोज () का उपयोग करके निर्धारित किया जाना चाहिए।
- इसे बनाना और आगे बढ़ना, उसी तरह से भरें जैसे इसे पिछले चरण में दिखाया गया था। एक वांछित पाठ के रूप में, विभाजक का उपयोग करें, और सेल को खोज के लिए टेक्स्ट के रूप में निर्दिष्ट करें।
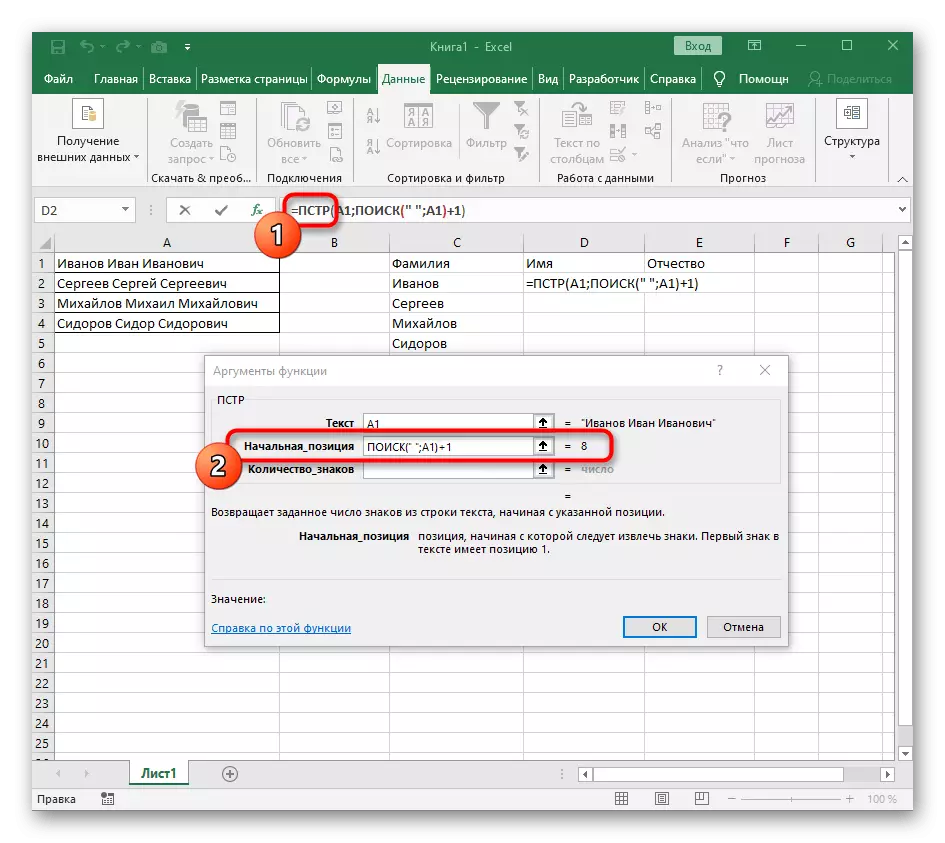
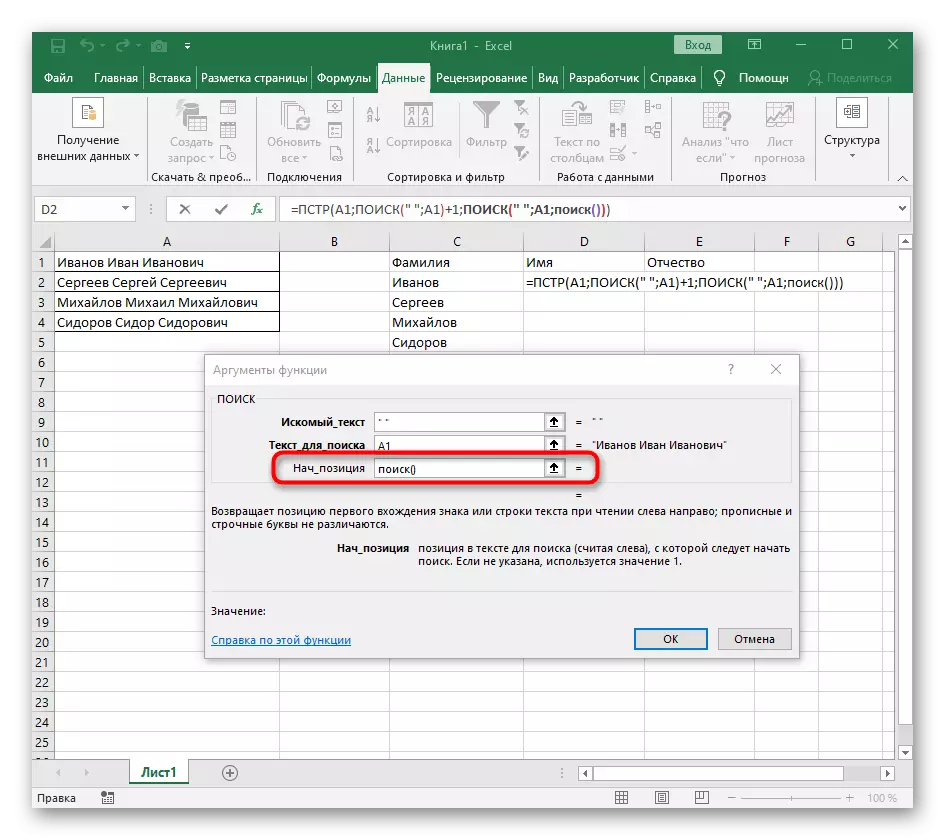
- पिछले सूत्र पर लौटें, जहां अंतरिक्ष के बाद अगले चरित्र से खाता शुरू करने के अंत में "खोज" फ़ंक्शन +1 में जोड़ें।
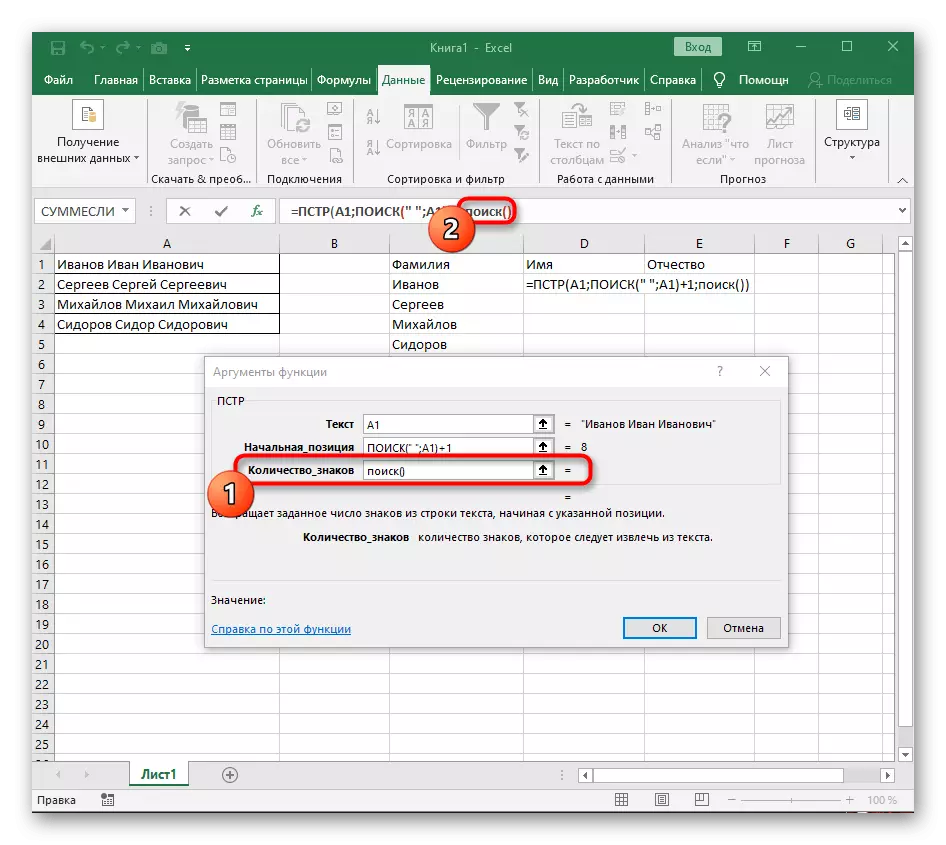
- अब सूत्र पहले पहले से ही पहले वर्ण नाम से लाइन खोजना शुरू कर सकता है, लेकिन यह अभी भी नहीं जानता कि इसे कहां खत्म करना है, इसलिए, फ़ील्ड "मात्रा_नाम" में फिर से, खोज फॉर्मूला () लिखें।
- अपने तर्कों पर जाएं और उन्हें पहले से ही परिचित रूप में भरें।
- पहले, हमने इस फ़ंक्शन की प्रारंभिक स्थिति पर विचार नहीं किया था, लेकिन अब खोज दर्ज करना आवश्यक है (), क्योंकि इस सूत्र को पहला अंतर नहीं मिलना चाहिए, लेकिन दूसरा।
- बनाए गए फ़ंक्शन पर जाएं और इसे उसी तरह से भरें।
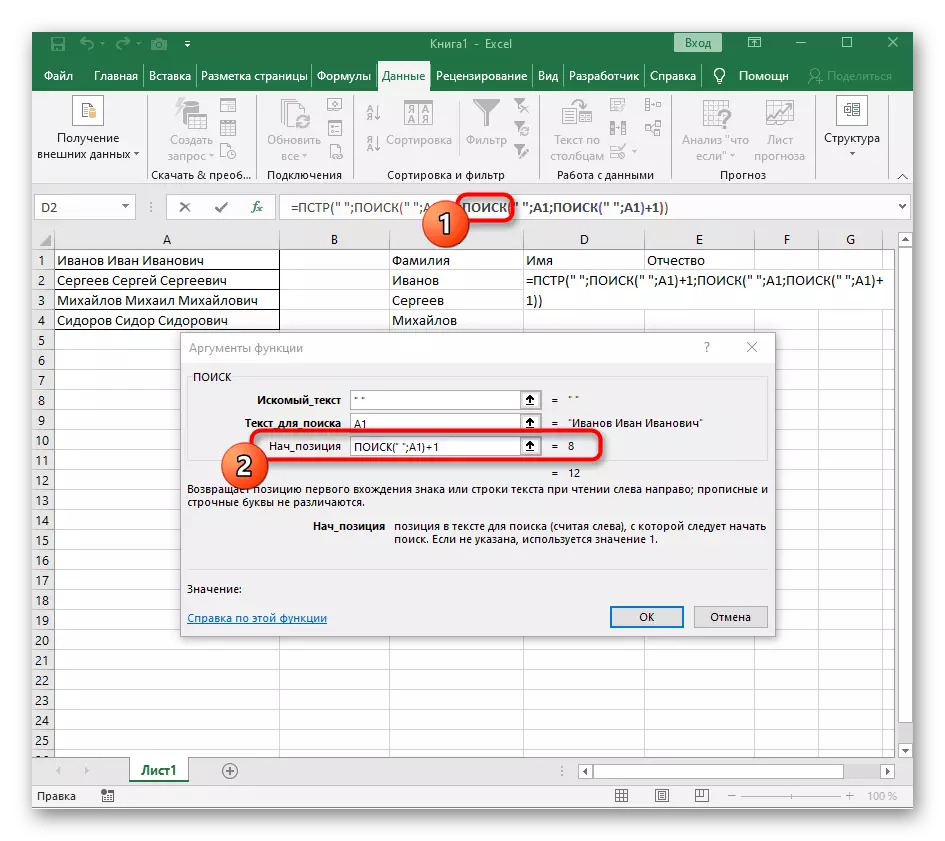
- पहली "खोज" पर लौटें और अंत में "nach_position" +1 में जोड़ें, क्योंकि इसे लाइन खोजने के लिए एक स्थान की आवश्यकता नहीं है, लेकिन अगला चरित्र।
- रूट = पीएसटी पर क्लिक करें और "NUMBER_NAMES" लाइन के अंत में कर्सर डालें।
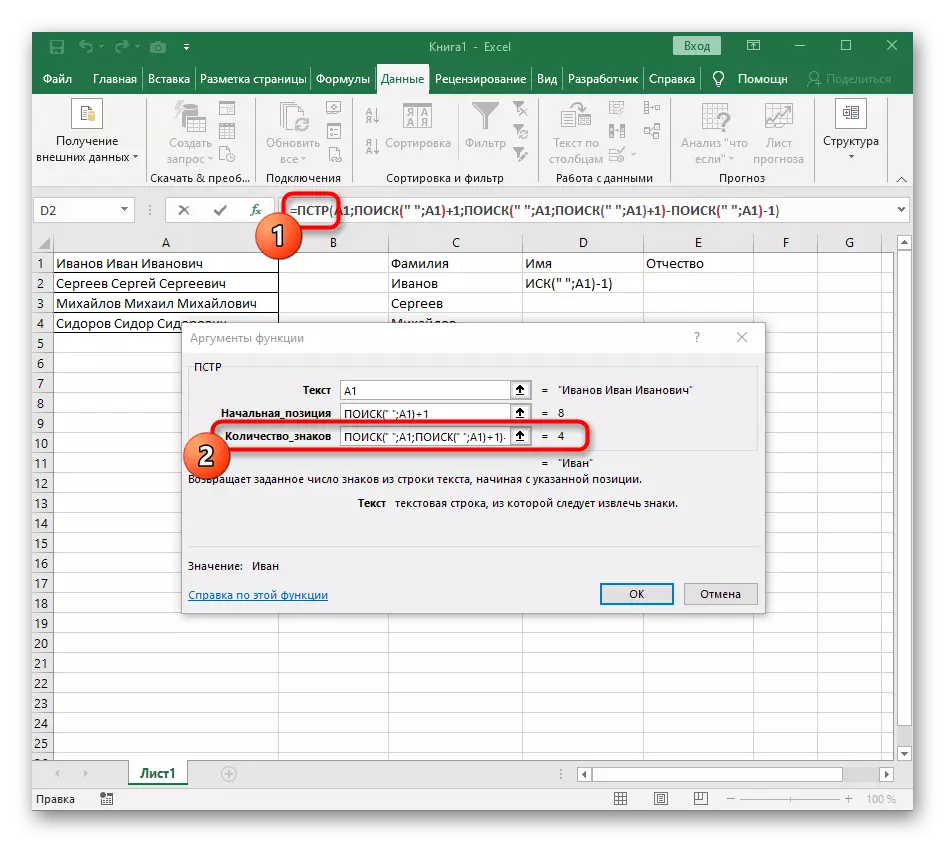
- रिक्त स्थान की गणना को पूरा करने के लिए अभिव्यक्ति की अभिव्यक्ति को निकालें (""; ए 1) -1।
- तालिका में लौटें, सूत्र खींचें और सुनिश्चित करें कि शब्द सही ढंग से प्रदर्शित होते हैं।


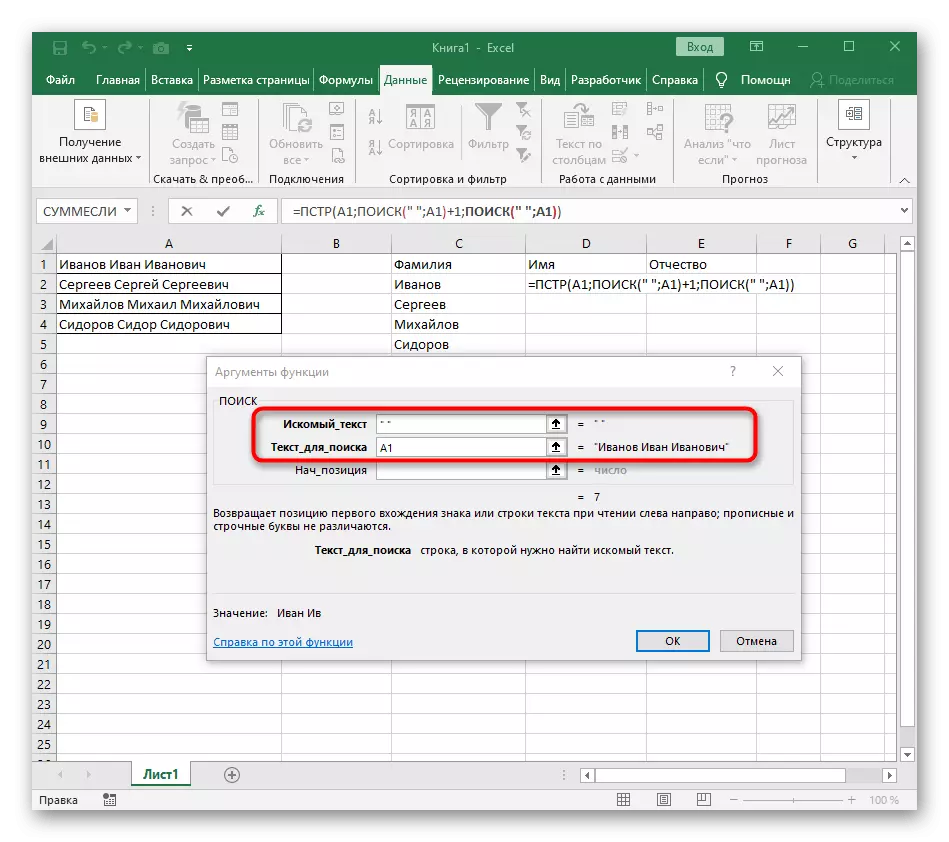

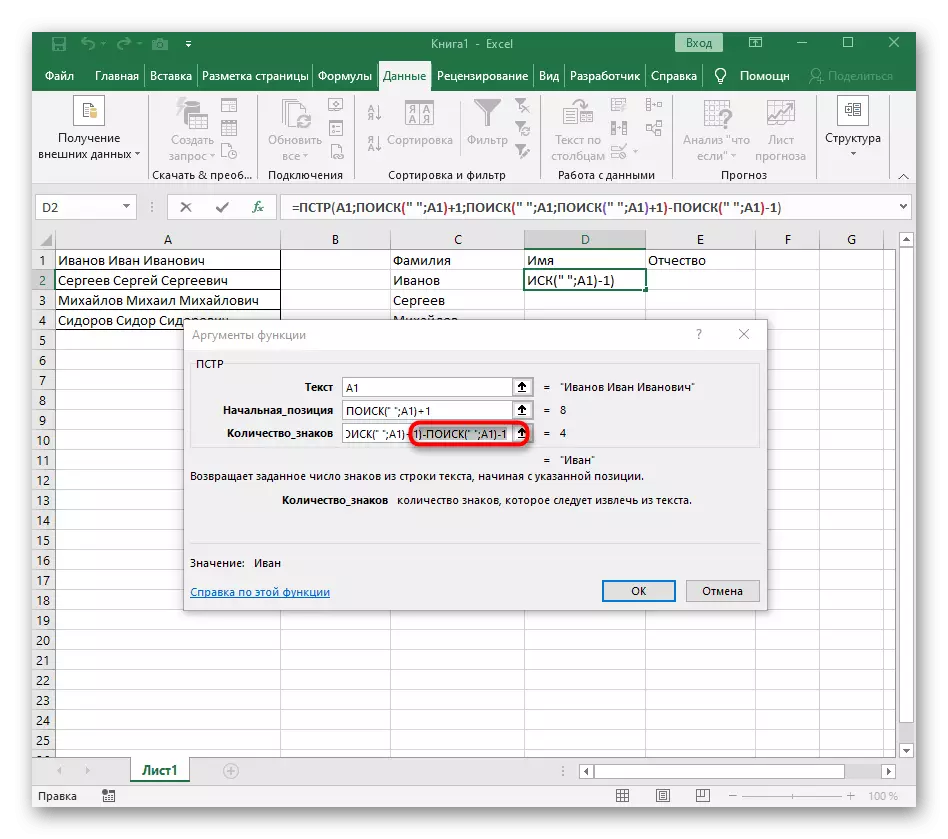
सूत्र बड़ा हो गया, और सभी उपयोगकर्ता समझते हैं कि यह कैसे काम करता है। तथ्य यह है कि उस लाइन की खोज करने के लिए मुझे कई कार्यों का उपयोग करना था जो रिक्त स्थान की प्रारंभिक और अंतिम स्थिति निर्धारित करते हैं, और फिर एक प्रतीक उनसे दूर ले गया ताकि परिणामस्वरूप, इन सबसे अंतराल प्रदर्शित किए गए थे। नतीजतन, सूत्र यह है: = PSTR (A1; खोज (""; A1) +1; खोज (""; A1; खोज (""; A1) +1) -poisk ("; A1) - 1)। इसे एक उदाहरण के रूप में उपयोग करें, पाठ के साथ सेल नंबर को प्रतिस्थापित करें।
चरण 3: तीसरे शब्द का पृथक्करण
हमारे निर्देश का अंतिम चरण तीसरे शब्द के विभाजन का तात्पर्य है, जो उसी तरह दिखता है जैसा कि पहले के साथ हुआ था, लेकिन सामान्य सूत्र थोड़ा बदल जाता है।
- एक खाली सेल में, भविष्य के पाठ के स्थान के लिए, लिखें = rashesimv (और इस फ़ंक्शन के तर्कों पर जाएं।
- एक पाठ के रूप में, अलगाव के लिए एक शिलालेख के साथ एक सेल निर्दिष्ट करें।
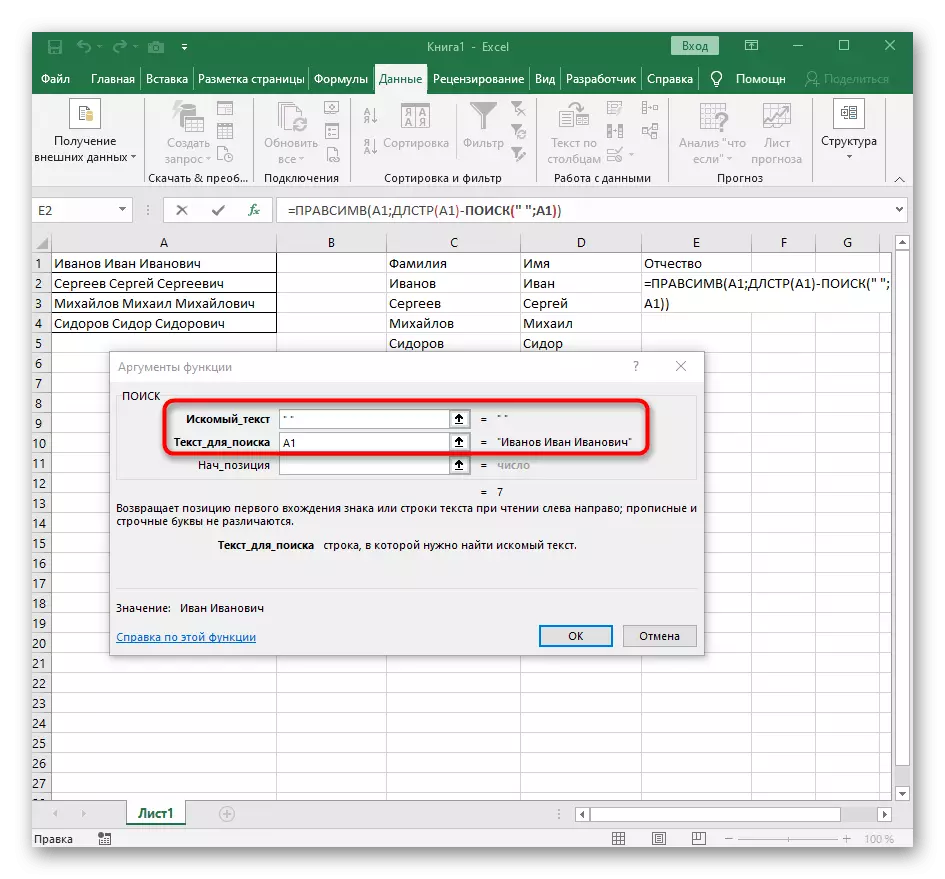
- इस बार एक शब्द खोजने के लिए सहायक फ़ंक्शन को DLSTR (A1) कहा जाता है, जहां A1 टेक्स्ट के साथ एक ही सेल है। यह सुविधा पाठ में वर्णों की संख्या निर्धारित करती है, और हम केवल उपयुक्त आवंटित रहेंगे।
- ऐसा करने के लिए, जोड़ें -Poisk () और इस सूत्र को संपादित करने के लिए जाओ।
- स्ट्रिंग में पहले विभाजक की खोज करने के लिए पहले से परिचित संरचना दर्ज करें।
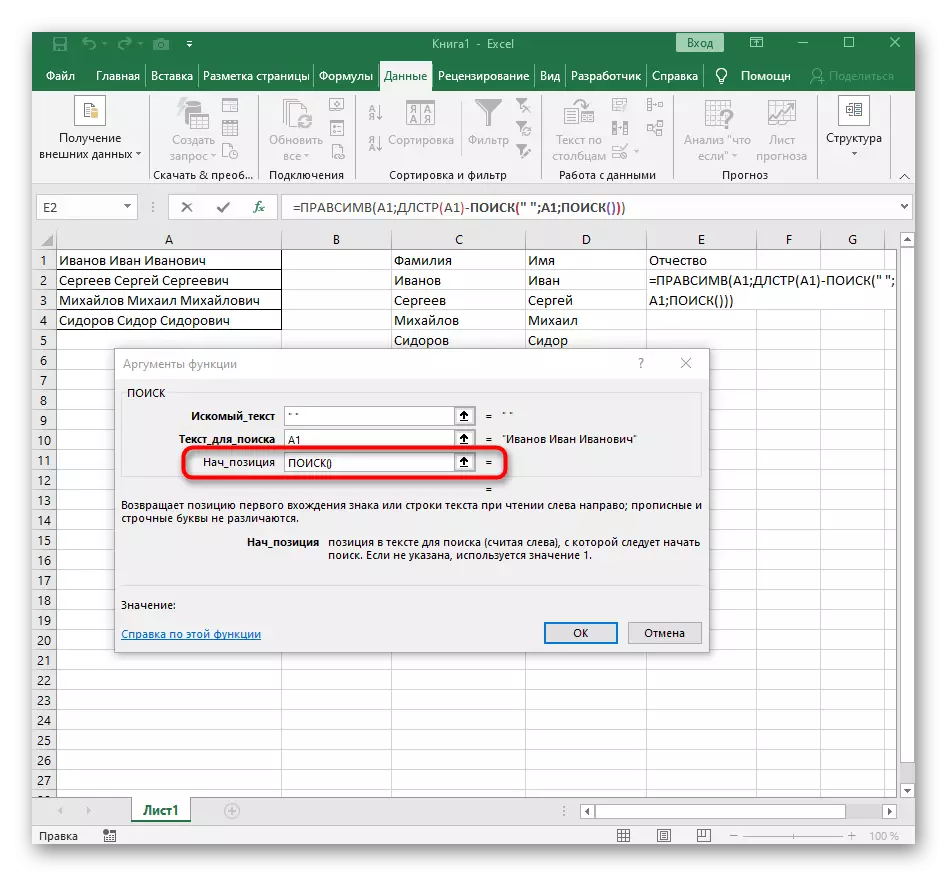
- प्रारंभिक स्थिति () के लिए एक और खोज जोड़ें।
- इसे एक ही संरचना निर्दिष्ट करें।
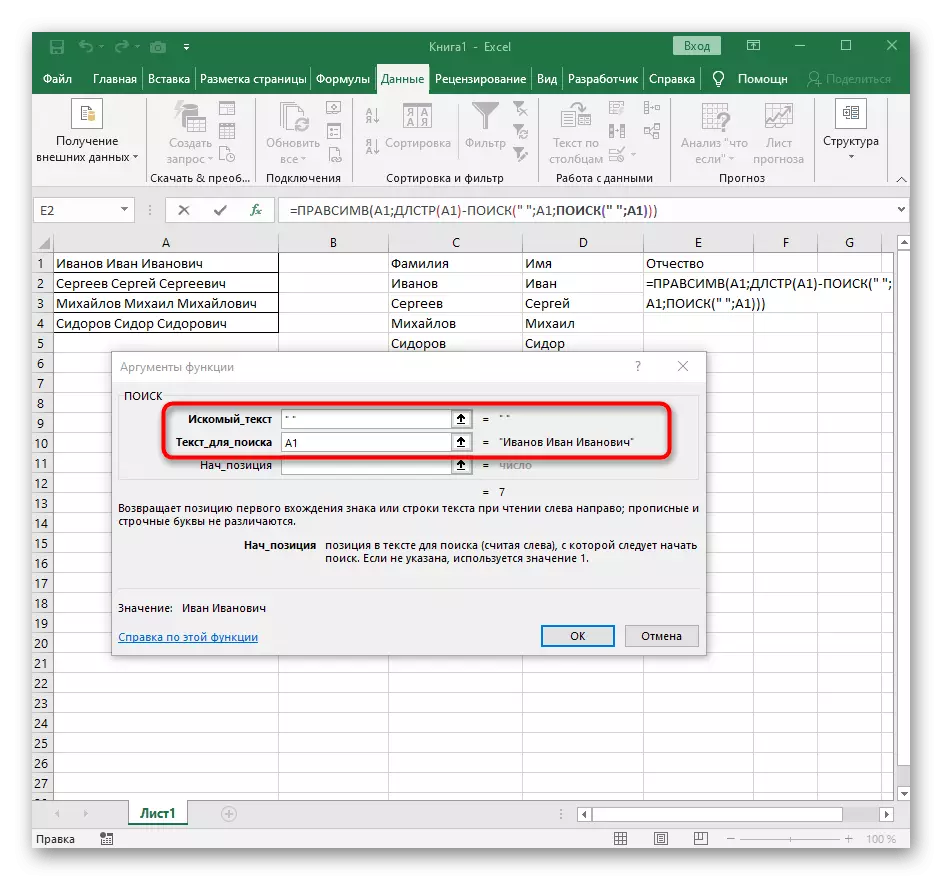
- पिछले खोज फॉर्मूला पर लौटें।
- अपनी प्रारंभिक स्थिति में +1 जोड़ें।
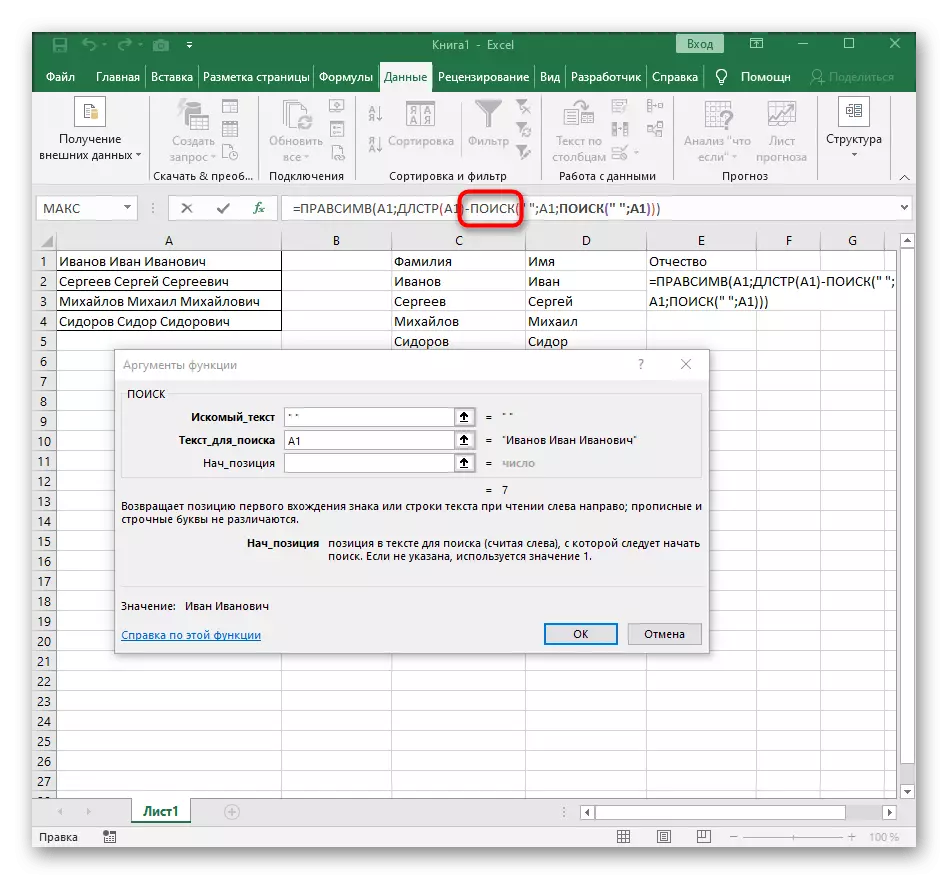
- फॉर्मूला Rascessv की जड़ पर नेविगेट करें और सुनिश्चित करें कि परिणाम सही ढंग से प्रदर्शित होता है, और फिर परिवर्तनों की पुष्टि करता है। इस मामले में पूर्ण सूत्र ऐसा लगता है = pracemir (a1; dlstr (a1) -poisk (""; a1; खोज (""; A1) +1))।
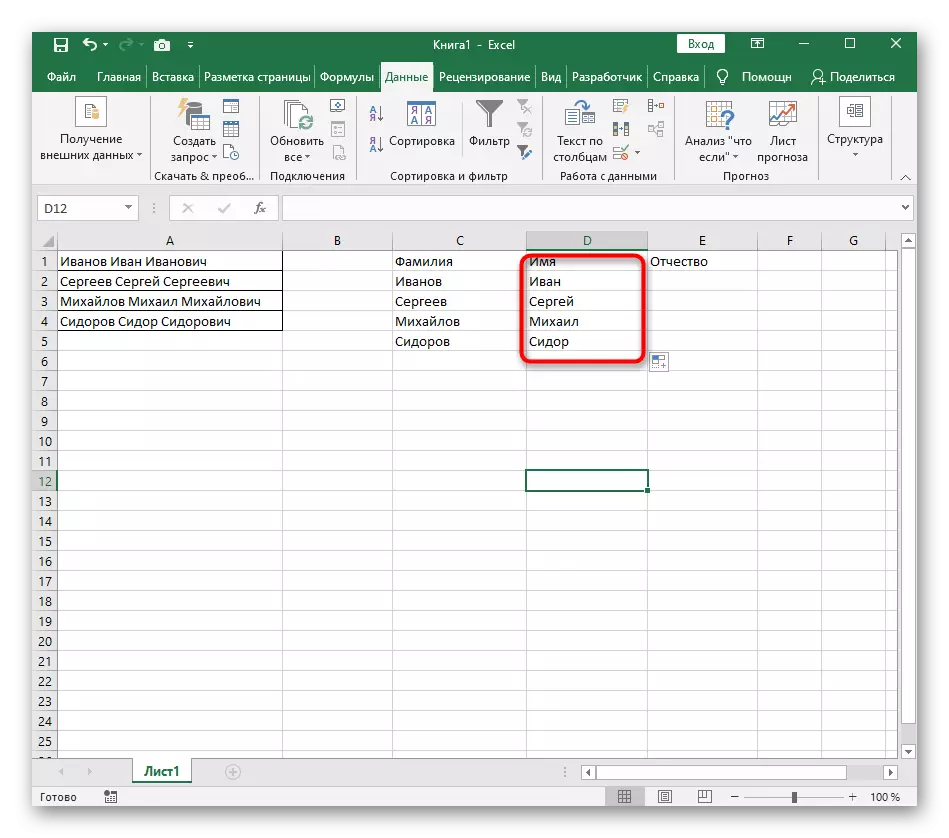
- नतीजतन, अगले स्क्रीनशॉट में आप देखते हैं कि सभी तीन शब्दों को सही ढंग से अलग किया गया है और उनके कॉलम में हैं। इसके लिए, विभिन्न प्रकार के सूत्रों और सहायक कार्यों का उपयोग करना आवश्यक था, लेकिन यह आपको गतिशील रूप से तालिका का विस्तार करने की अनुमति देता है और चिंता नहीं करता कि हर बार आपको टेक्स्ट को फिर से साझा करना होगा। यदि आवश्यक हो, तो इसे नीचे ले जाकर सूत्र का विस्तार करें ताकि निम्न कक्ष स्वचालित रूप से प्रभावित हो जाएं।