Metoda 1: Použití automatického nástroje
Excel má automatický nástroj určený k rozdělení textu ve sloupcích. Nepracuje automaticky automaticky, takže všechny akce budou muset být provedeny ručně, výběr rozsahu zpracovaných dat. Nastavení je však nejjednodušší a rychleji.
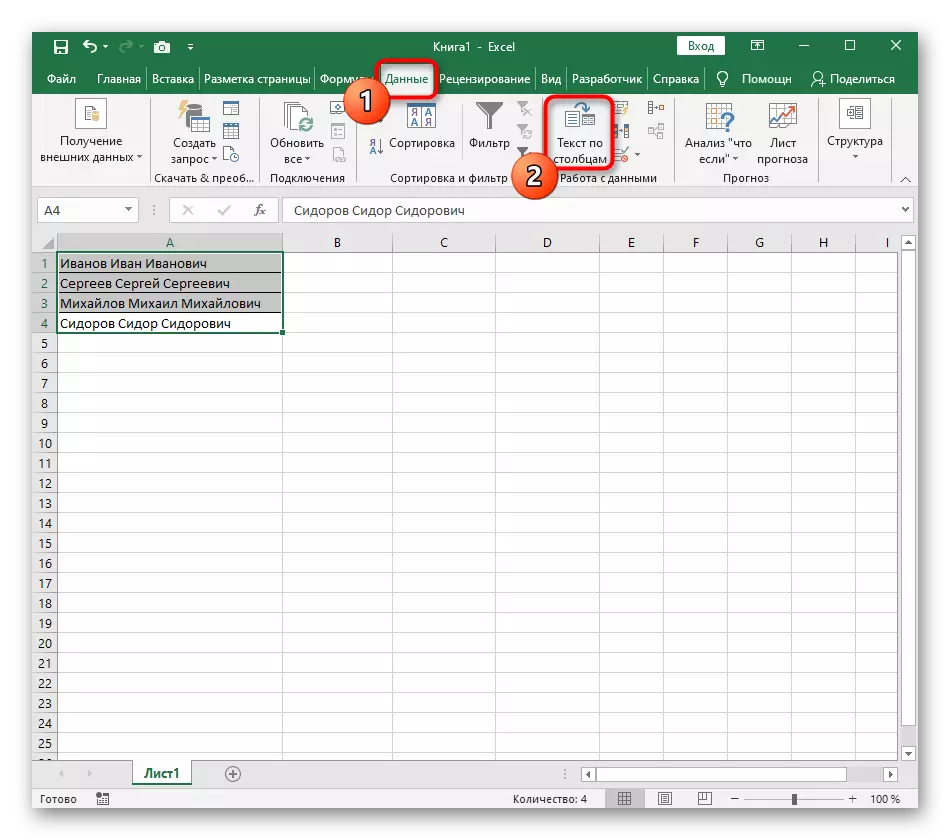
- Pomocí levého tlačítka myši vyberte všechny buňky, jejichž text chcete rozdělit na sloupcích.
- Poté přejděte na záložku "Data" a klepněte na tlačítko "Text To Column".
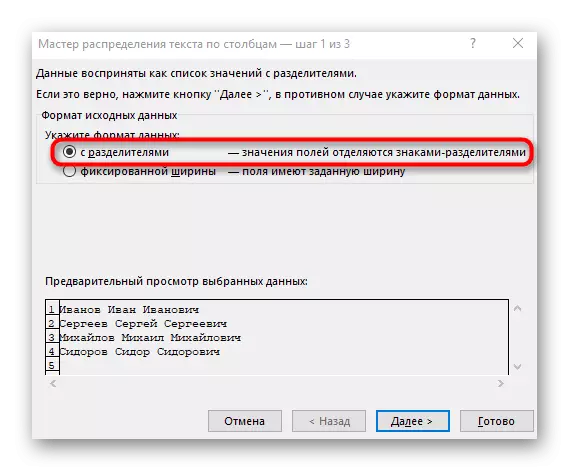
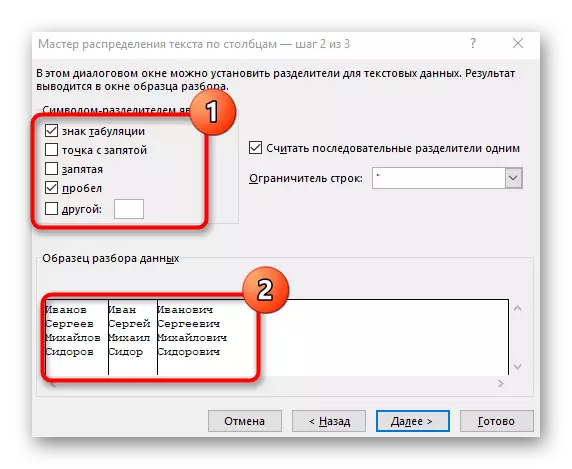
- Zobrazí se okno "Průvodce textovým sloupcem", ve kterém chcete vybrat formát dat "se separátory". Separátor nejčastěji provádí prostor, ale pokud se jedná o další interpunkční znaménko, budete muset určit v dalším kroku.
- Zaškrtněte políčko Sekvenční symbol Zkontrolujte nebo ručně zadejte jej a přečtěte si předběžné oddělení v okně níže.
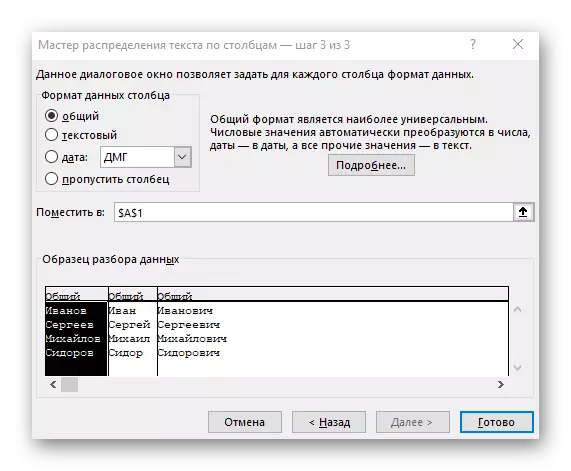
- V posledním kroku můžete zadat nový formát sloupce a místo, kde musí být umístěny. Jakmile je nastavení dokončeno, klepněte na tlačítko "Dokončit" pro použití všech změn.
- Vraťte se do tabulky a ujistěte se, že separace úspěšně projde.


Z této instrukce můžeme dospět k závěru, že použití takového nástroje je optimálně v těchto situacích, kdy separace musí být provedena pouze jednou, označující pro každé slovo nový sloupec. Nicméně, pokud jsou nová data neustále zavedena do stolu, po celou dobu je rozdělit bude takhle není docela pohodlný, takže v takových případech doporučujeme seznámit se s následujícím způsobem.
Metoda 2: Vytvoření vzorce Split Split
V aplikaci Excel můžete nezávisle vytvořit relativně složitý vzorec, který vám umožní vypočítat pozice slov v buňce, najít mezery a rozdělit každý do samostatných sloupů. Jako příklad budeme mít buňku sestávající ze tří slov oddělených mezerami. Pro každého z nich bude mít svůj vlastní vzorec, proto rozdělujeme metodu do tří fází.Krok 1: Oddělení prvního slova
Vzorec pro první slovo je nejjednodušší, protože bude muset být odpuzen pouze z jedné mezery pro určení správné polohy. Zvažte každý krok jeho vytvoření, takže kompletní obraz je, proč jsou zapotřebí určité výpočty.
- Pro pohodlí vytvořte tři nové sloupce s podpisy, kde přidáme oddělený text. Tento okamžik můžete udělat totéž nebo přeskočit.
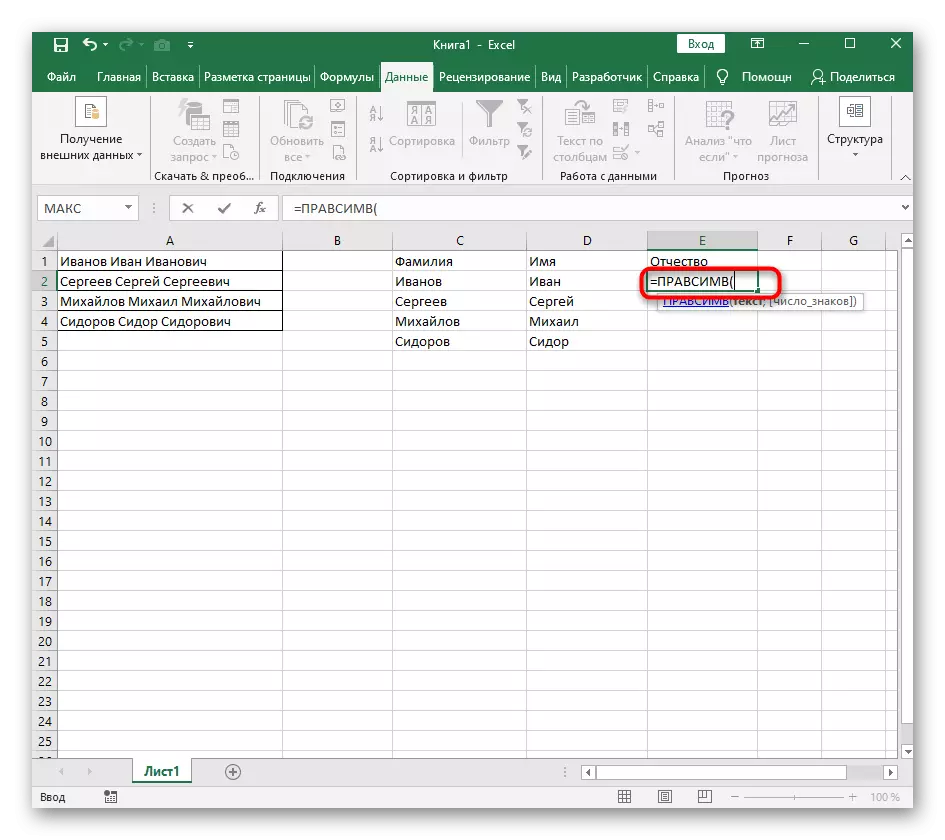
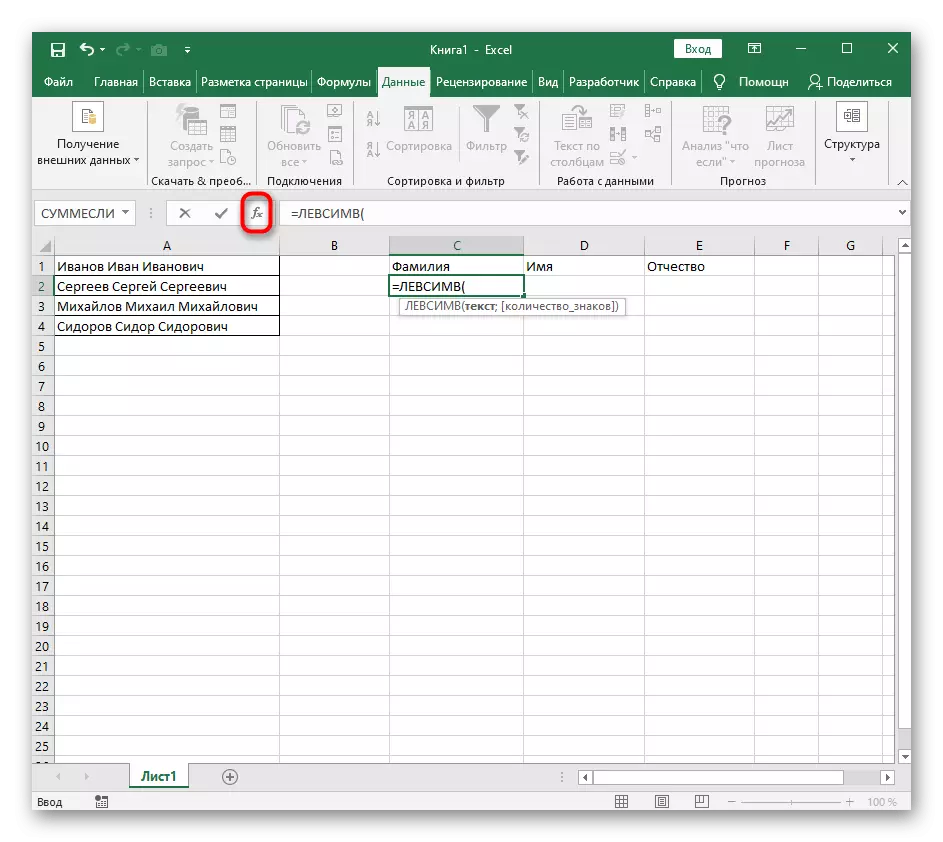
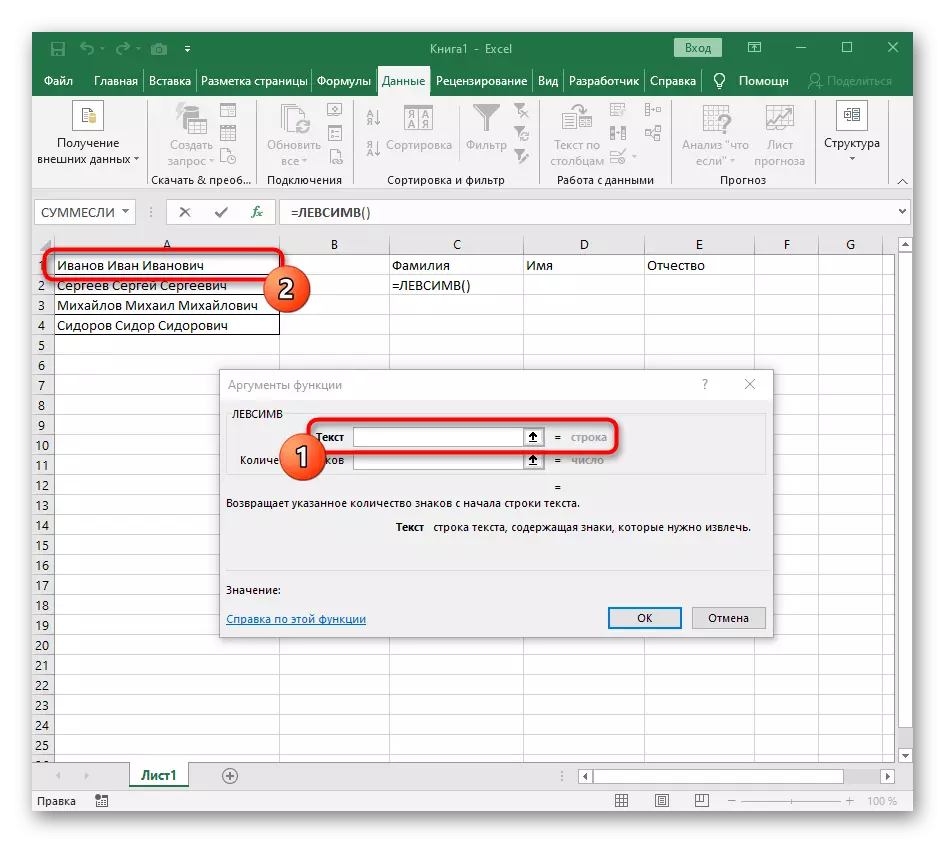
- Vyberte buňku, kde chcete umístit první slovo a zapište si vzorec = LessImv (.
- Poté stiskněte tlačítko "Argumenty volby", čímž se přesune do okna pro úpravy grafiky vzorce.
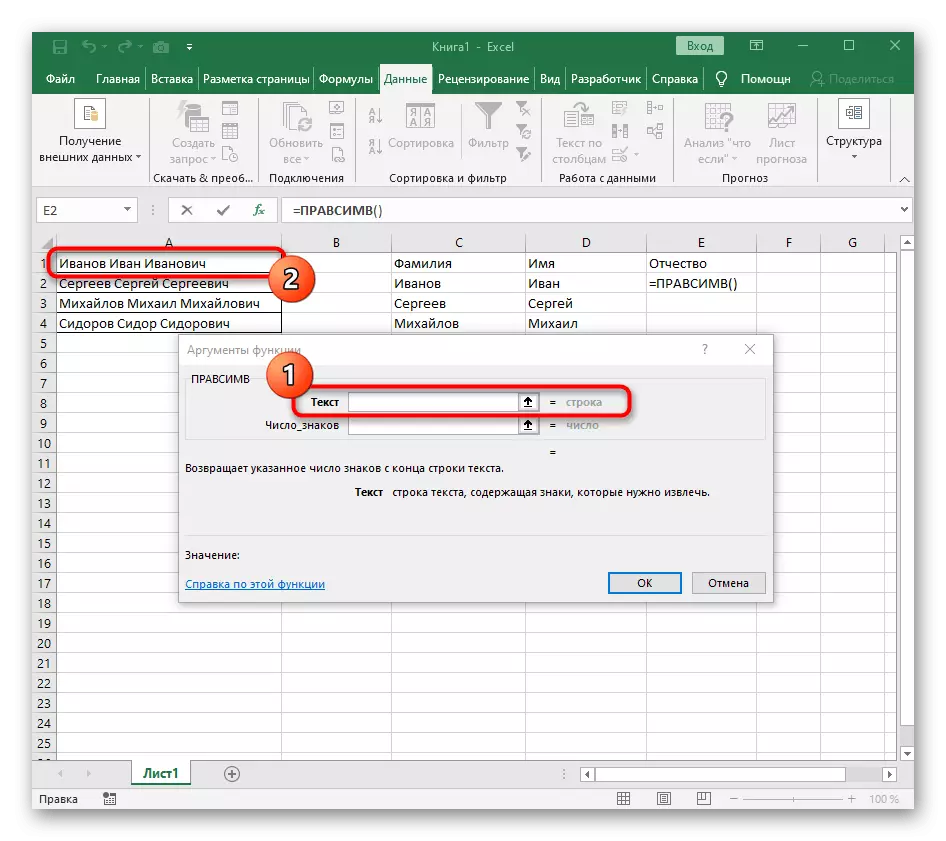
- Jako text argumentu zadejte buňku pomocí nápisu kliknutím na něj levým tlačítkem myši na tabulce.
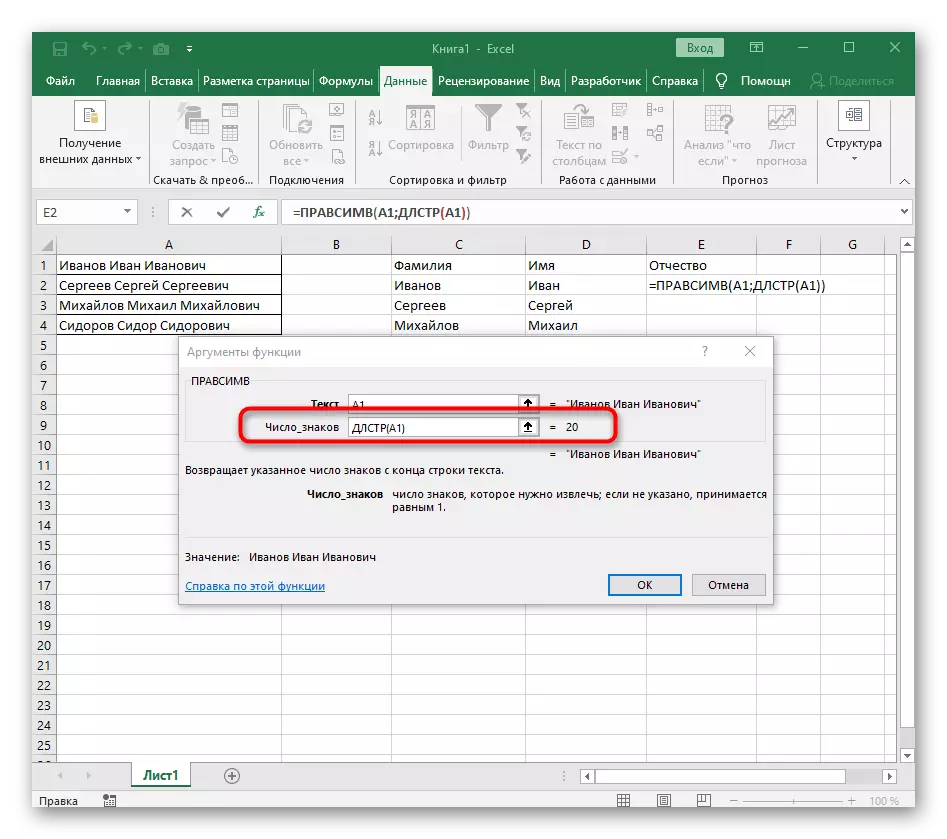
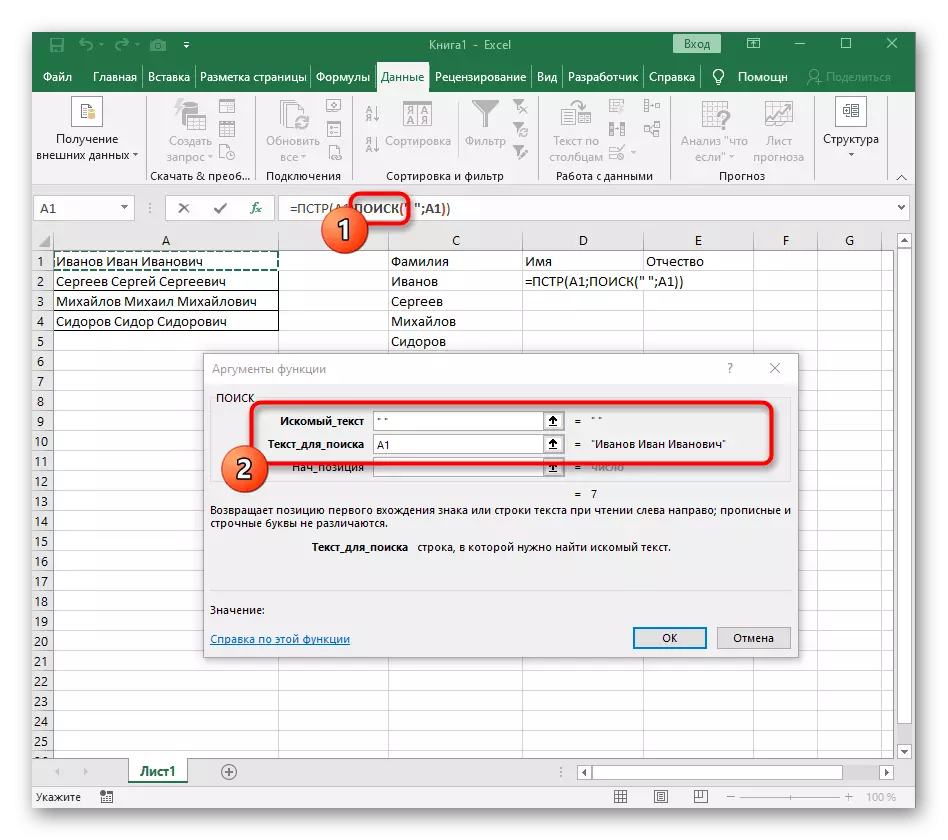
- Počet značek do prostoru nebo jiného separátoru bude muset vypočítat, ale ručně nebudeme dělat, ale použijeme další vzorec - hledání ().
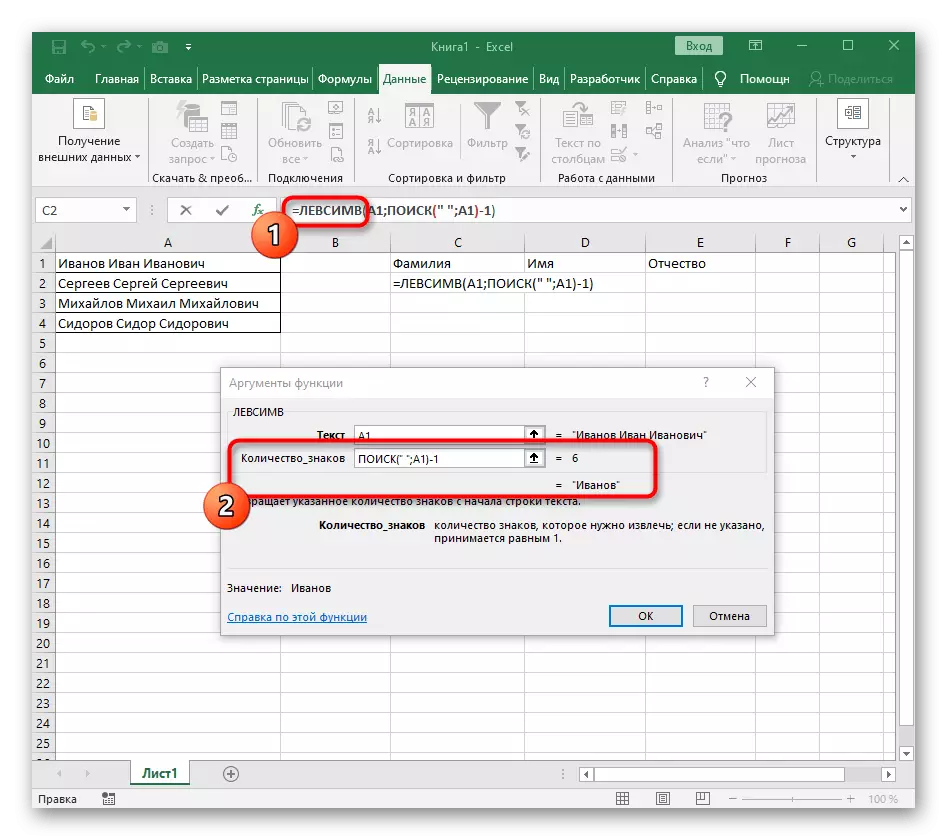
- Jakmile jej zaznamenáte v takovém formátu, zobrazí se v textu buňky nahoře a bude zvýrazněn tučně. Kliknutím na něj rychle přechod k argumentům této funkce.
- V poli "Skeletra" jednoduše vložte prostor nebo separátor, protože vám pomůže pochopit, kde slovo končí. V "Text_-Search" zadejte stejnou buňku zpracovávanou.
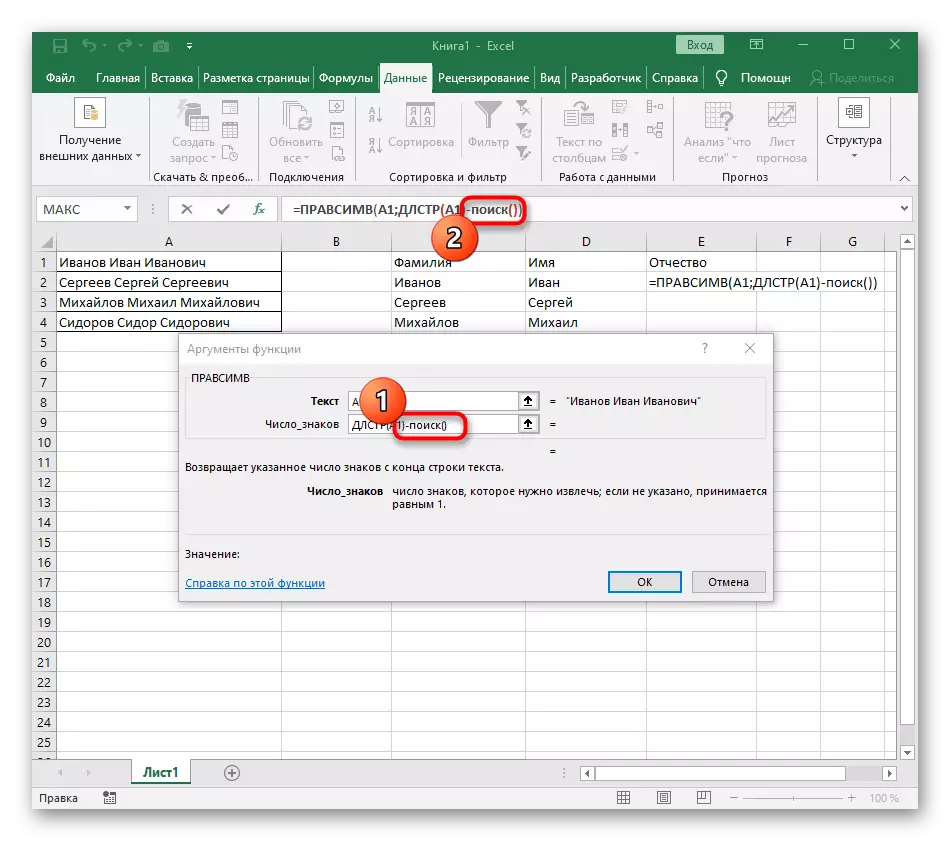
- Kliknutím na první funkci se vrátíte a přidejte na konci druhého argumentu -1. To je nezbytné, aby hledaný vzorec zohlednil ne požadovaný prostor, ale symbol k němu. Jak je vidět na následujícím screenshot, výsledek se zobrazí bez mezer, což znamená, že kompilace vzorce je správně provedena.
- Zavřete editor funkcí a ujistěte se, že slovo je správně zobrazeno v nové buňce.
- Držte buňku v pravém dolním rohu a přetáhněte se na požadovaný počet řádků, abyste jej natáhli. Takže hodnoty dalších výrazů jsou substituovány, které musí být rozděleny a naplnění vzorce je automaticky.




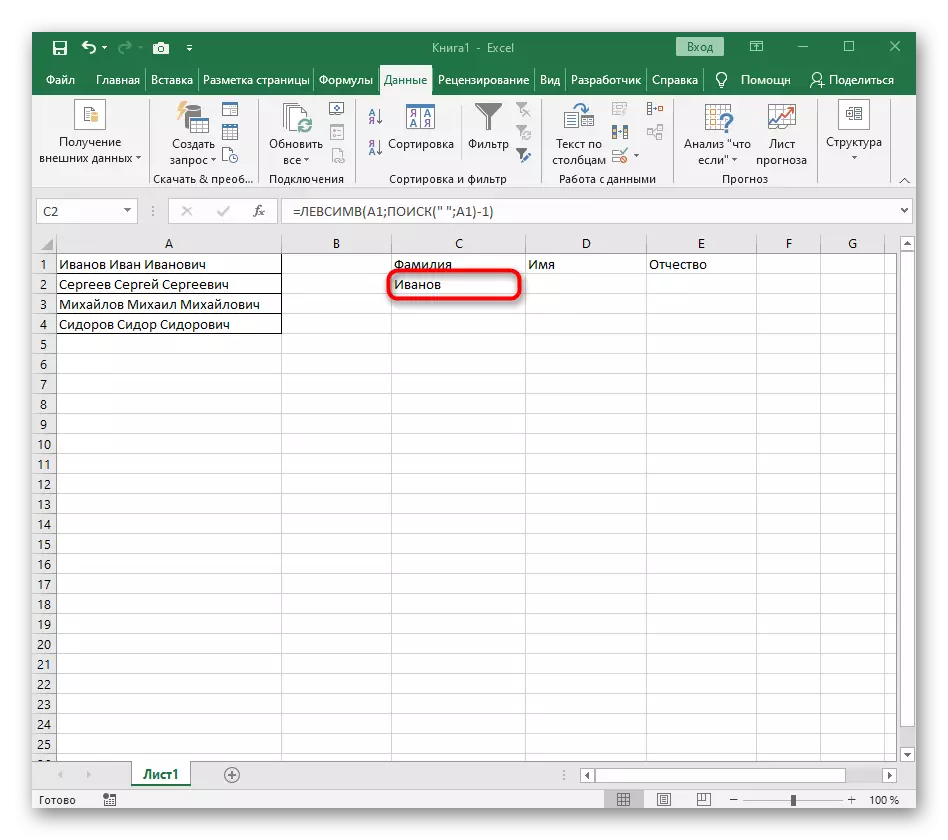

Plně vytvořený vzorec má formulář = levsimv (A1; vyhledávání (""; A1) -1), můžete jej vytvořit podle výše uvedených pokynů nebo vložit, pokud jsou vhodné podmínky a separátor. Nezapomeňte vyměnit zpracovanou buňku.
Krok 2: Separace druhého slova
Nejtěžší je rozdělit druhé slovo, které v našem případě je název. Důvodem je skutečnost, že je obklopen mezerami z obou stran, takže budete muset vzít v úvahu oba, vytváření masivního vzorce pro správný výpočet polohy.
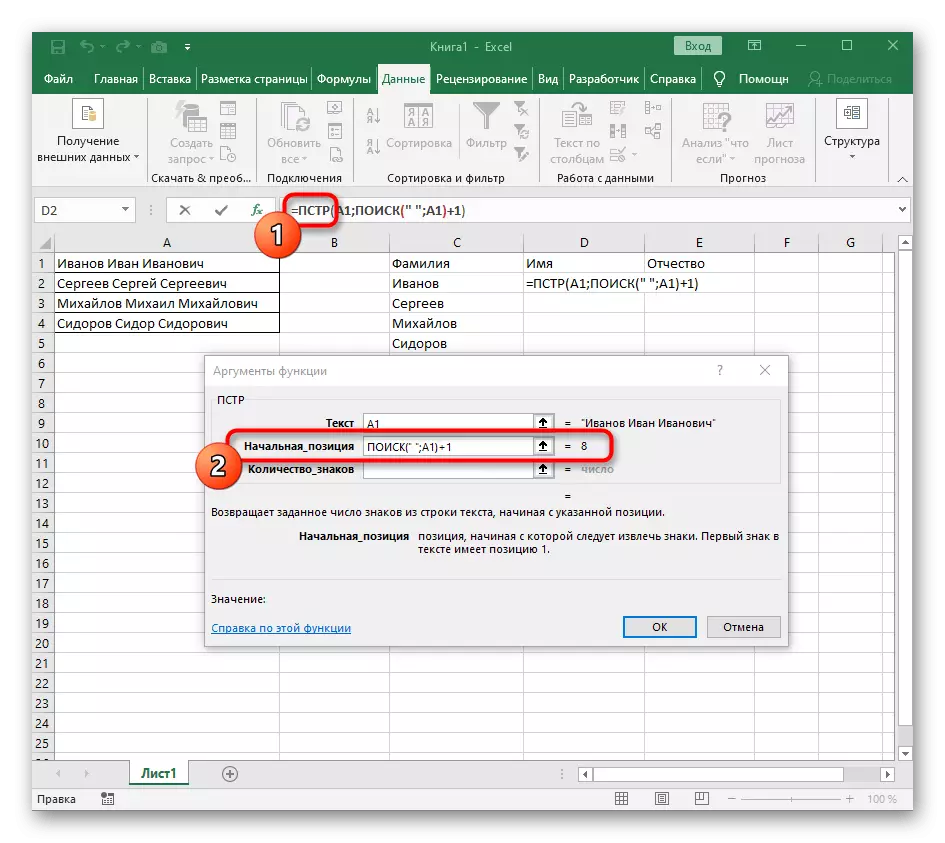
- V tomto případě bude hlavní vzorec = PST (- napsat jej do tohoto formuláře a pak přejděte do okna nastavení argumentu.
- Tento vzorec bude hledat požadovaný řetězec v textu, který je vybrán buňkou s nápisem pro separaci.
- Počáteční poloha řádku bude muset být stanovena pomocí již známého pomocného vzorce vyhledávání ().
- Vytvoření a pohyb k němu vyplnit stejným způsobem, jak bylo uvedeno v předchozím kroku. Jako požadovaný text použijte oddělovač a zadejte buňku jako text pro vyhledávání.
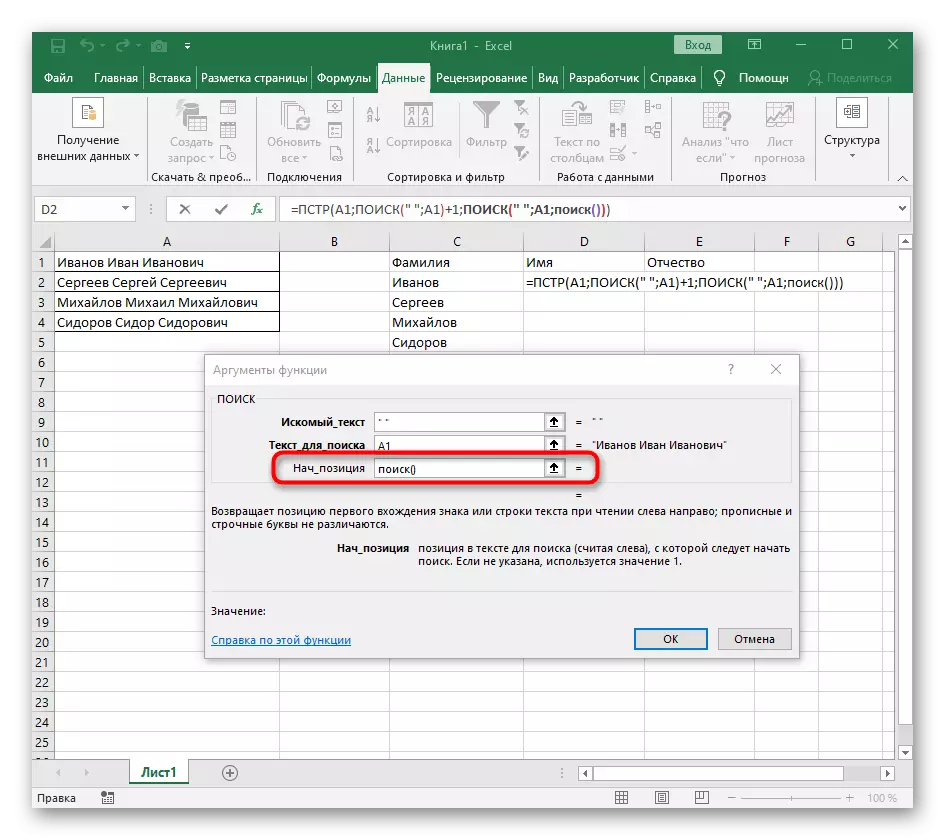
- Návrat na předchozí vzorec, kde přidat funkci "Vyhledávání" +1 na konci spustit účet od dalšího znaku po nalezeném prostoru.
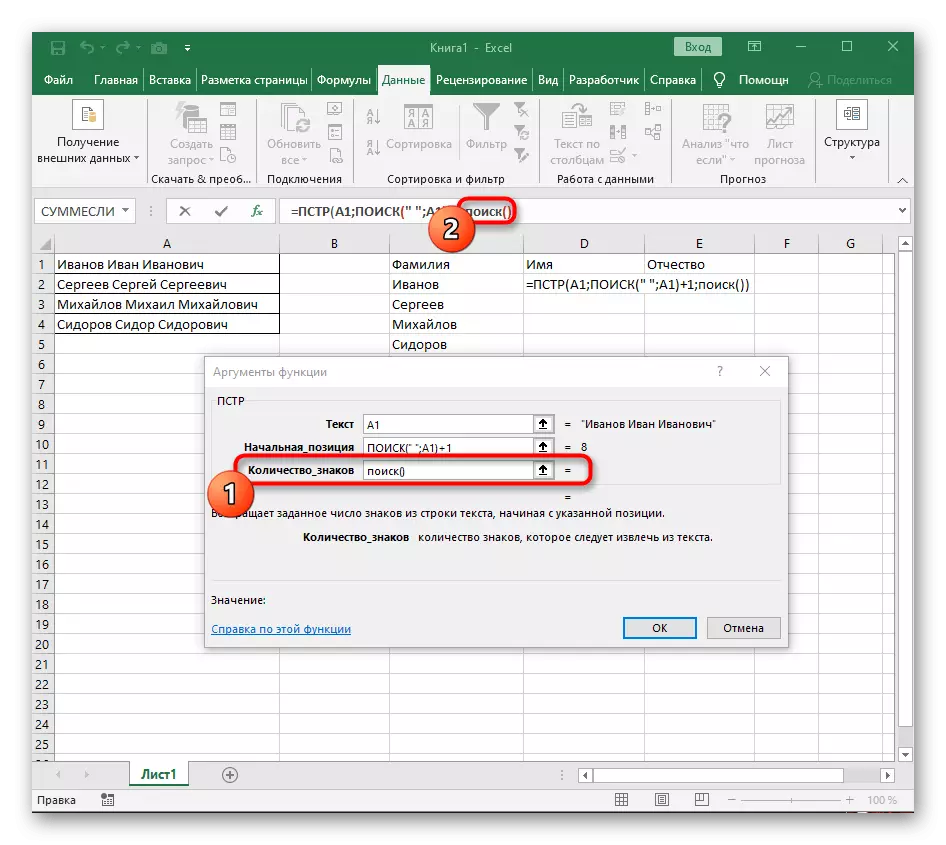
- Nyní vzorec může již spustit vyhledávání řádku z prvního názvu znaku, ale stále neví, kde jej dokončit, tedy v poli "Množství_names" znovu napsat vyhledávací vzorec ().
- Jděte do svých argumentů a vyplňte je v již známé podobě.
- Dříve jsme nepovažovali počáteční pozici této funkce, ale nyní je nutné zadat vyhledávání (), protože tento vzorec by neměl najít první mezeru, ale druhý.
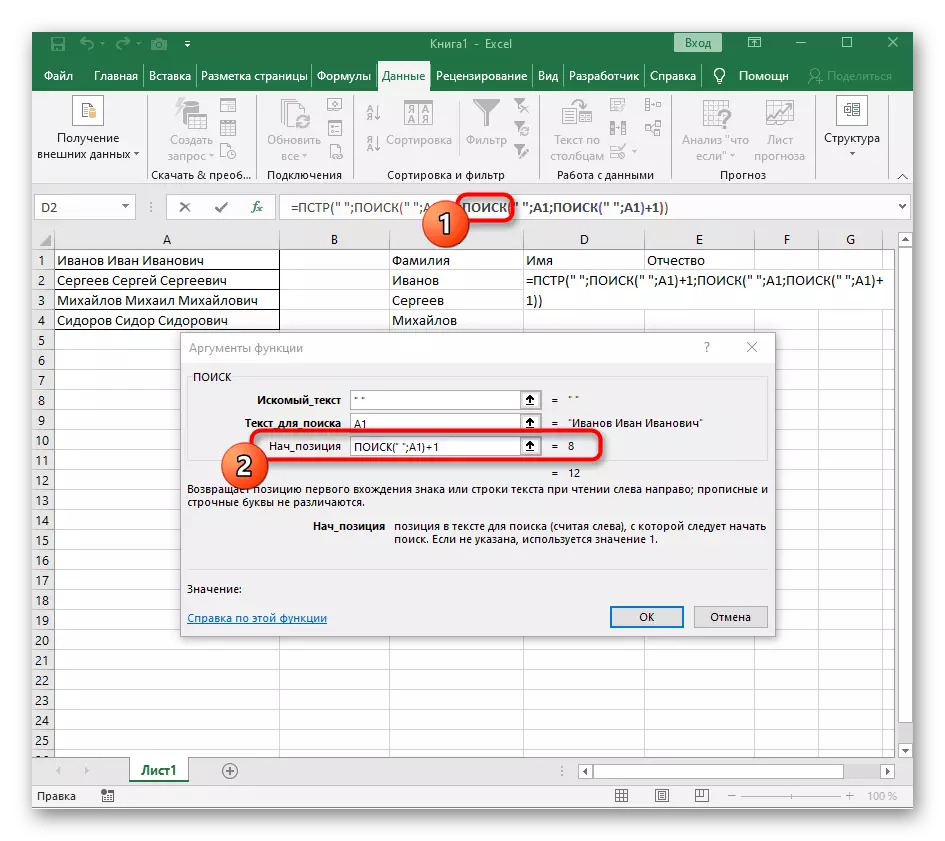
- Přejděte do vytvořené funkce a vyplňte jej stejným způsobem.
- Návrat na první "vyhledávání" a přidat do "Nach_position" +1 na konci, protože nepotřebuje prostor pro vyhledávání řádku, ale další znak.
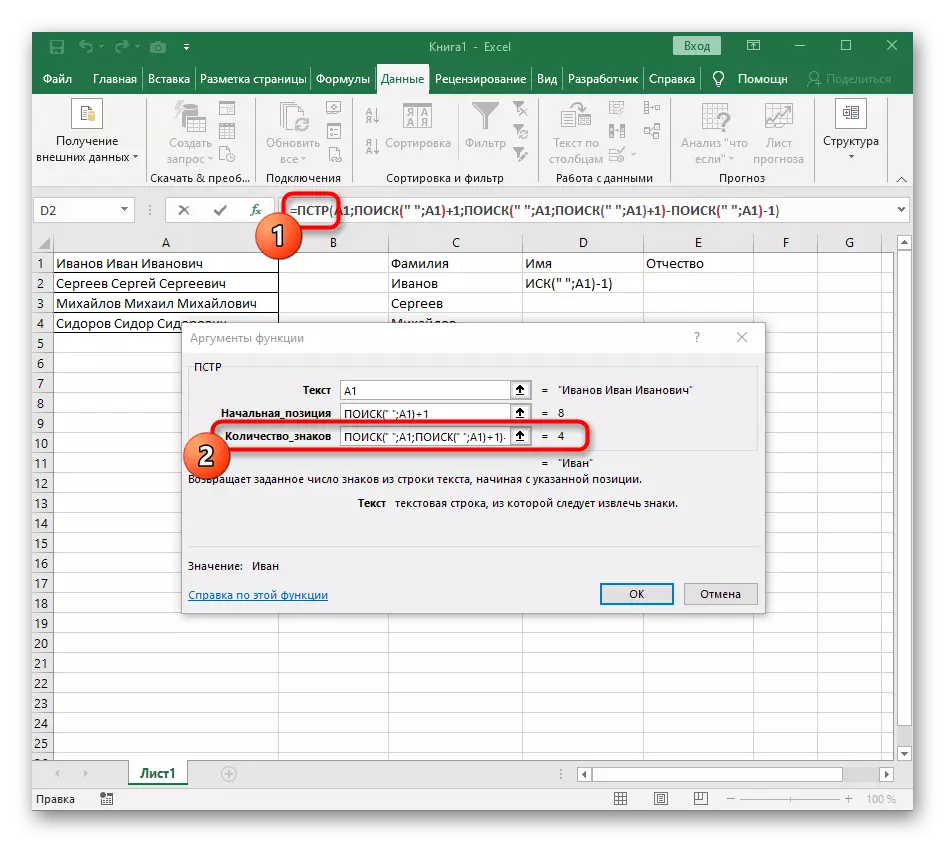
- Klikněte na kořen = PST a položte kurzor na konci řádku "number_names".
- Extrahujte expresi exprese (""; A1) -1 pro dokončení výpočtů mezer.
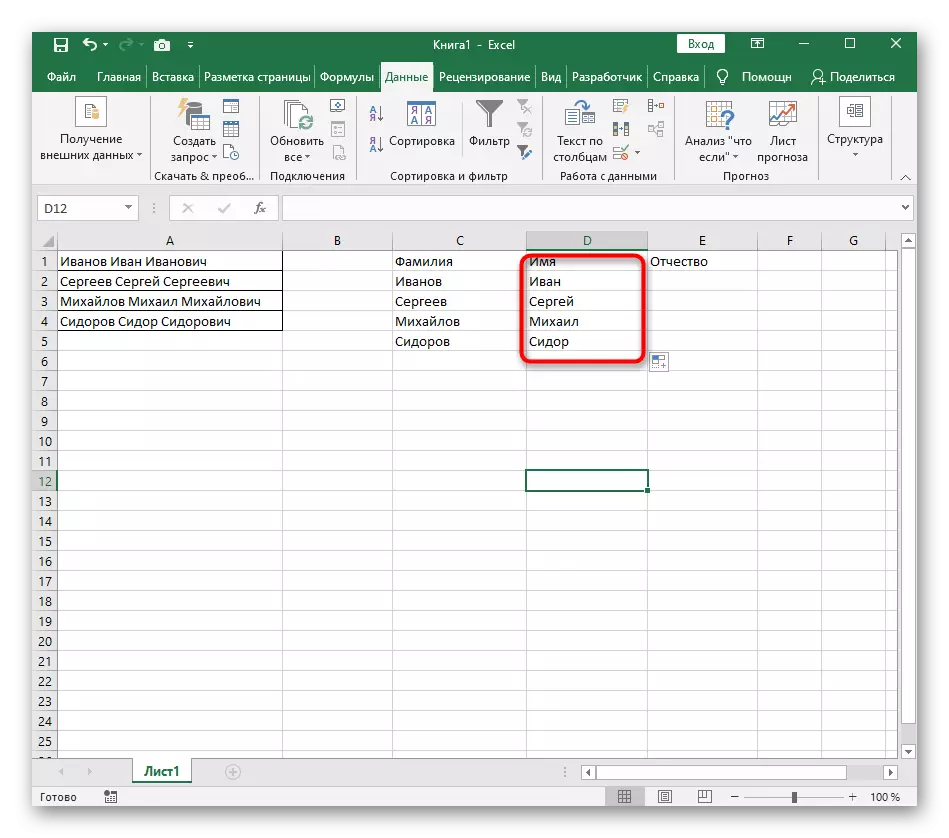
- Vraťte se do tabulky, protáhněte vzorec a ujistěte se, že se slova zobrazují správně.


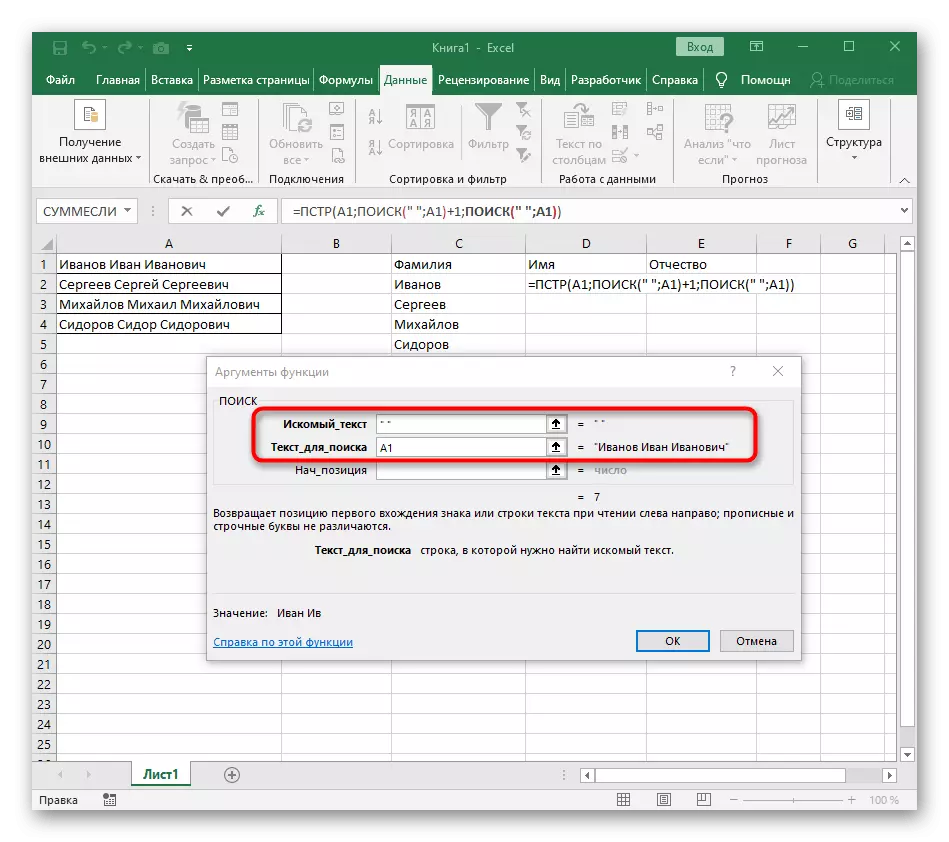

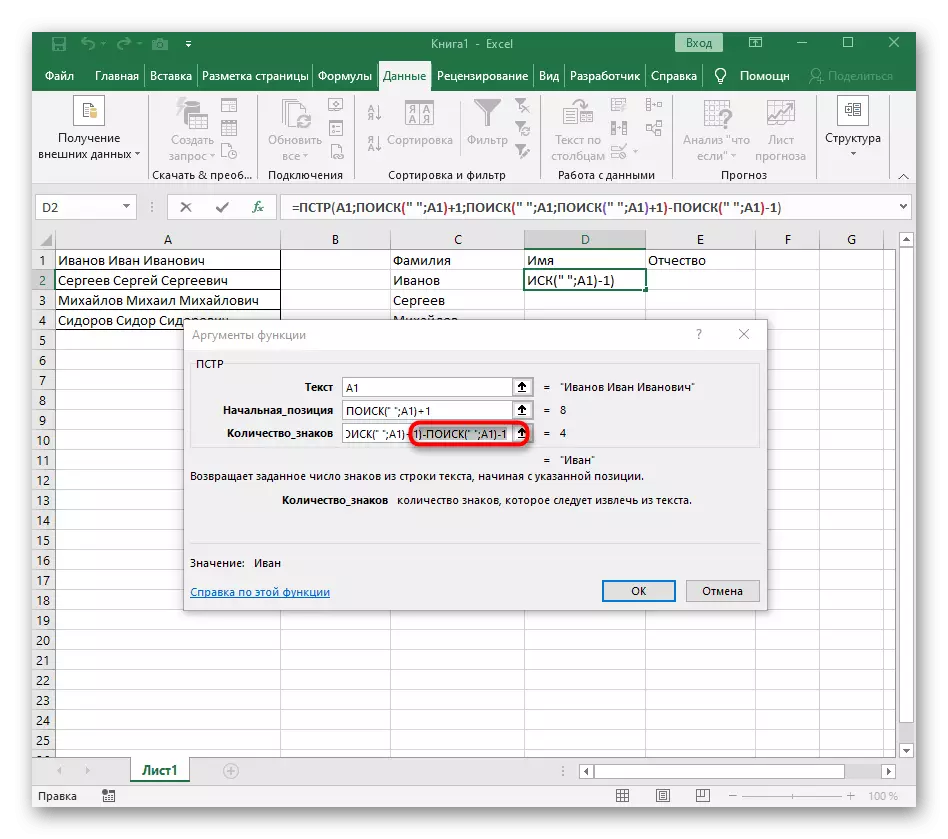
Vzorec se ukázal velký, a ne všichni uživatelé rozumí přesně, jak to funguje. Faktem je, že hledat linku, kterou musel použít několik funkcí, které určují počáteční a konečné pozice mezer, a pak jeden symbol odtrhl od nich tak, že v důsledku toho byly zobrazeny tyto většiny mezer. Výsledkem je, že vzorec je toto: = PRST (A1; vyhledávání ("" A1) +1; vyhledávání (""; A1; vyhledávání ("" A1) +1) -poisk (""; A1) - 1). Použijte jej jako příklad, nahrazení čísla buňky textem.
Krok 3: Separace třetího slova
Posledním krokem naší instrukce znamená rozdělení třetího slova, které se dívá na stejném způsobu, jak se to stalo s první, ale obecný vzorec se mírně změní.
- V prázdné buňce, pro umístění budoucího textu, psát = Rashesimv (a přejděte do argumentů této funkce.
- Jako text určete buňku s nápisem pro separaci.
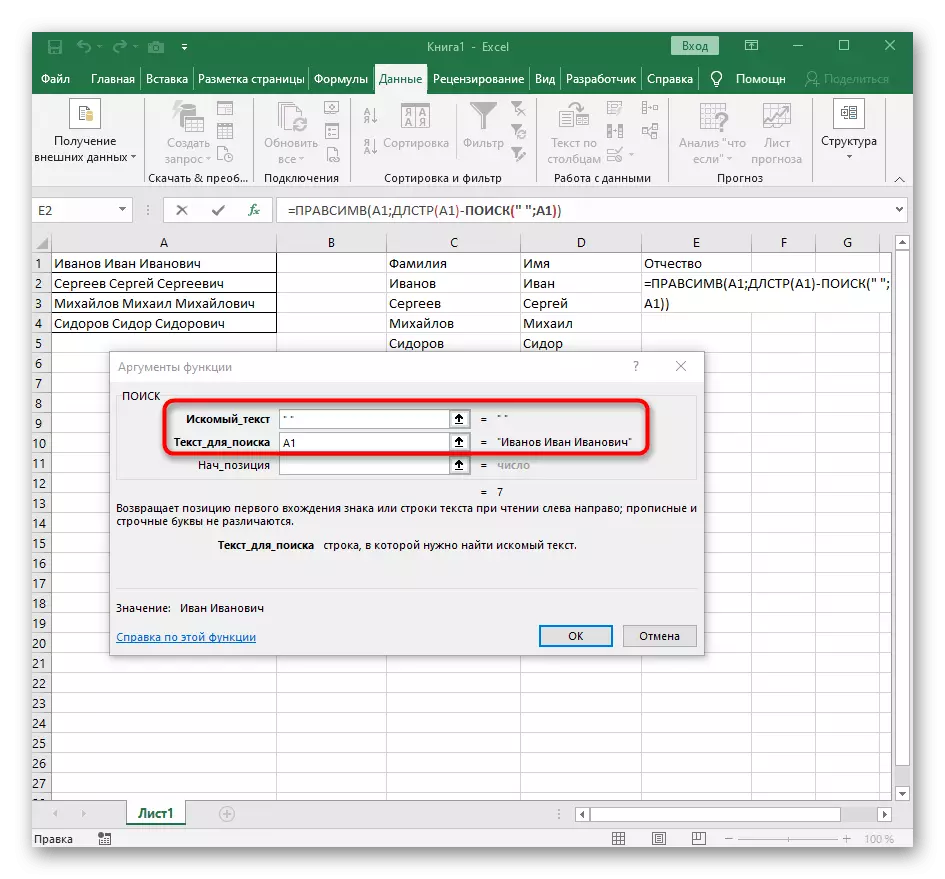
- Tato doba pomocná funkce pro nalezení slova se nazývá dlstr (A1), kde A1 je stejná buňka s textem. Tato funkce určuje počet znaků v textu a zůstaneme pouze vhodné.
- Chcete-li to udělat, přidejte -poisk () a jděte na upravit tento vzorec.
- Zadejte již známou strukturu pro vyhledávání prvního oddělovače v řetězci.
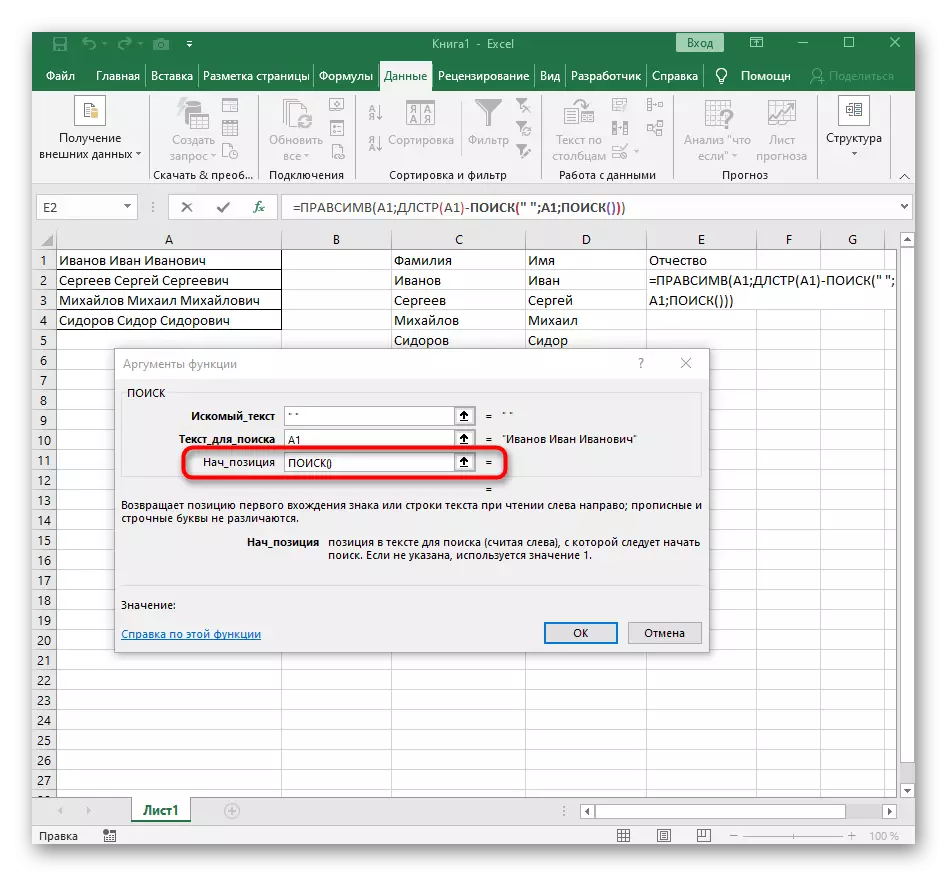
- Přidat další hledání výchozí pozice ().
- Určete ji stejnou strukturu.
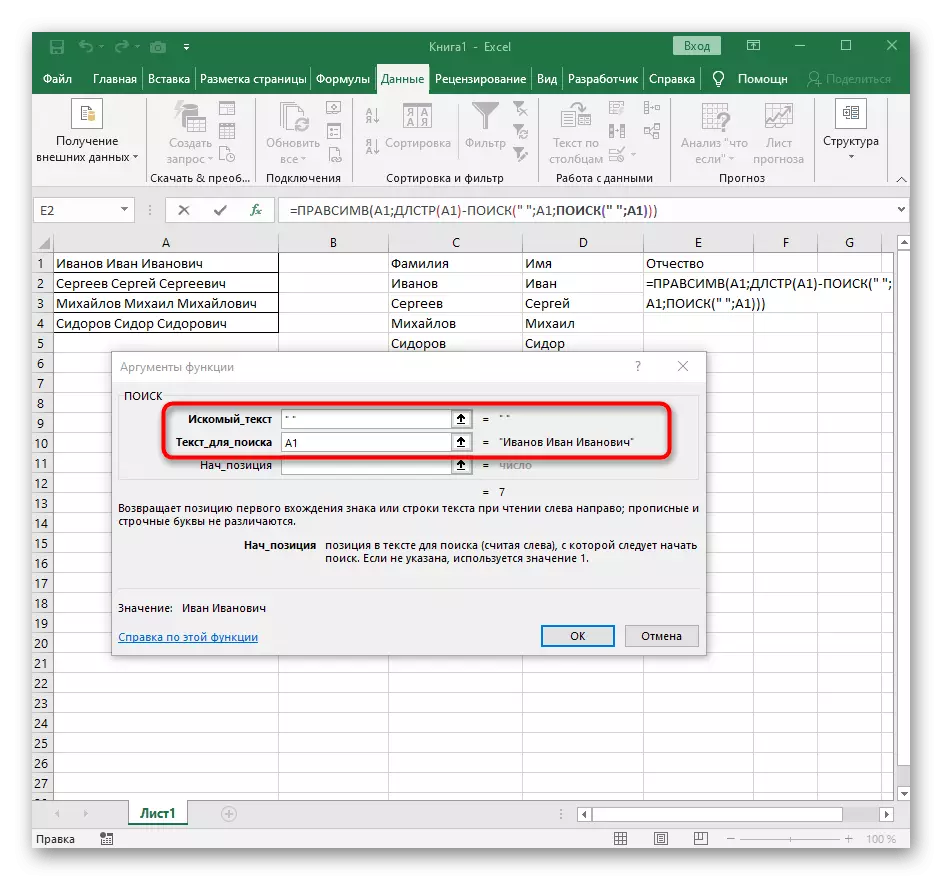
- Návrat na předchozí vyhledávací vzorec.
- Přidejte +1 do výchozí polohy.
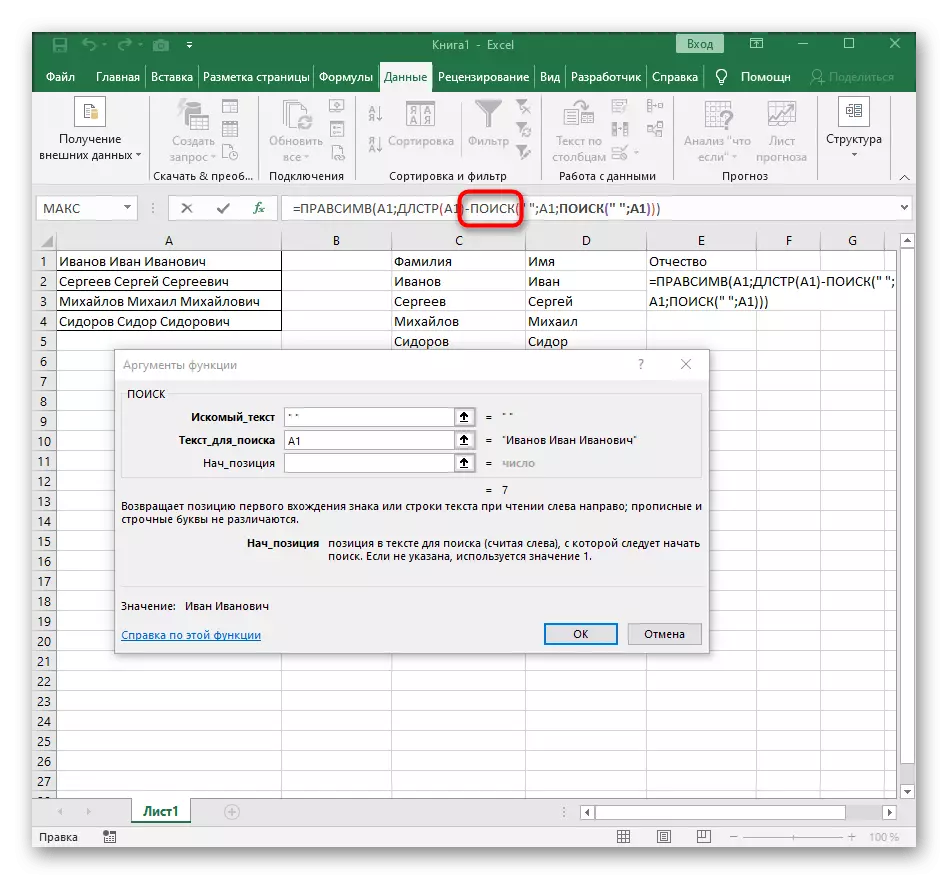
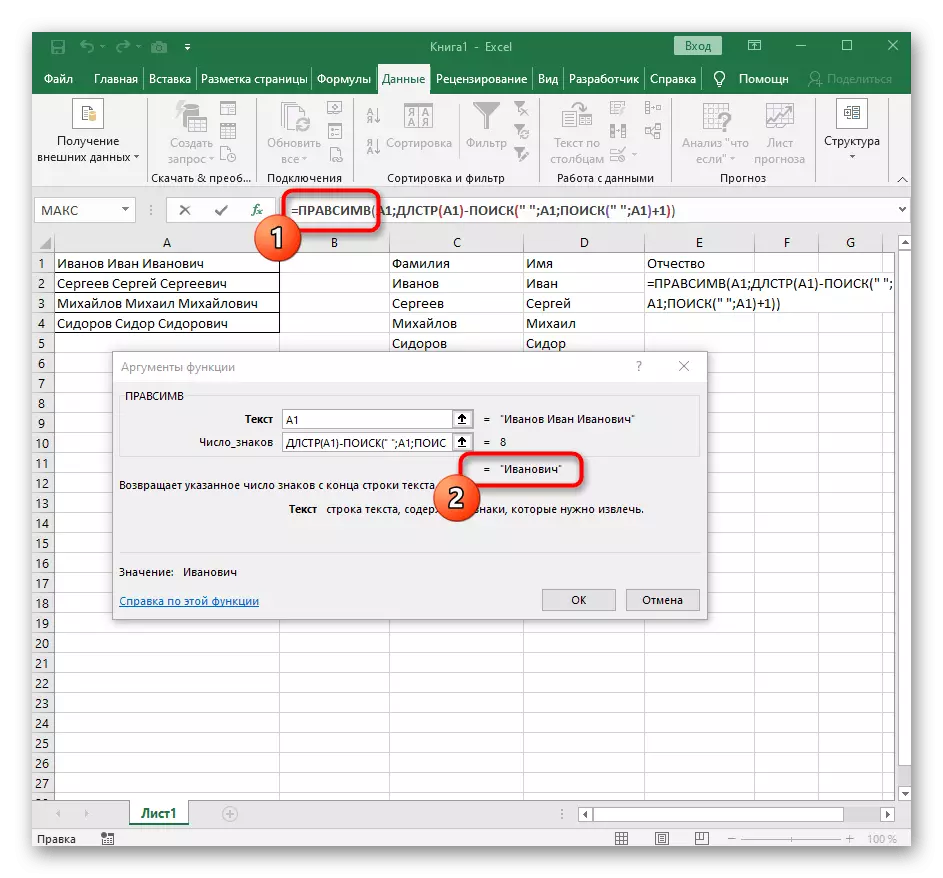
- Přejděte do kořenového kořene Formulia RascessV a ujistěte se, že výsledek se zobrazí správně a poté potvrďte změny. Kompletní vzorec v tomto případě vypadá = pracelemir (A1; Dlstr (A1) -poisk (""; A1; vyhledávání ("" A1) +1)).
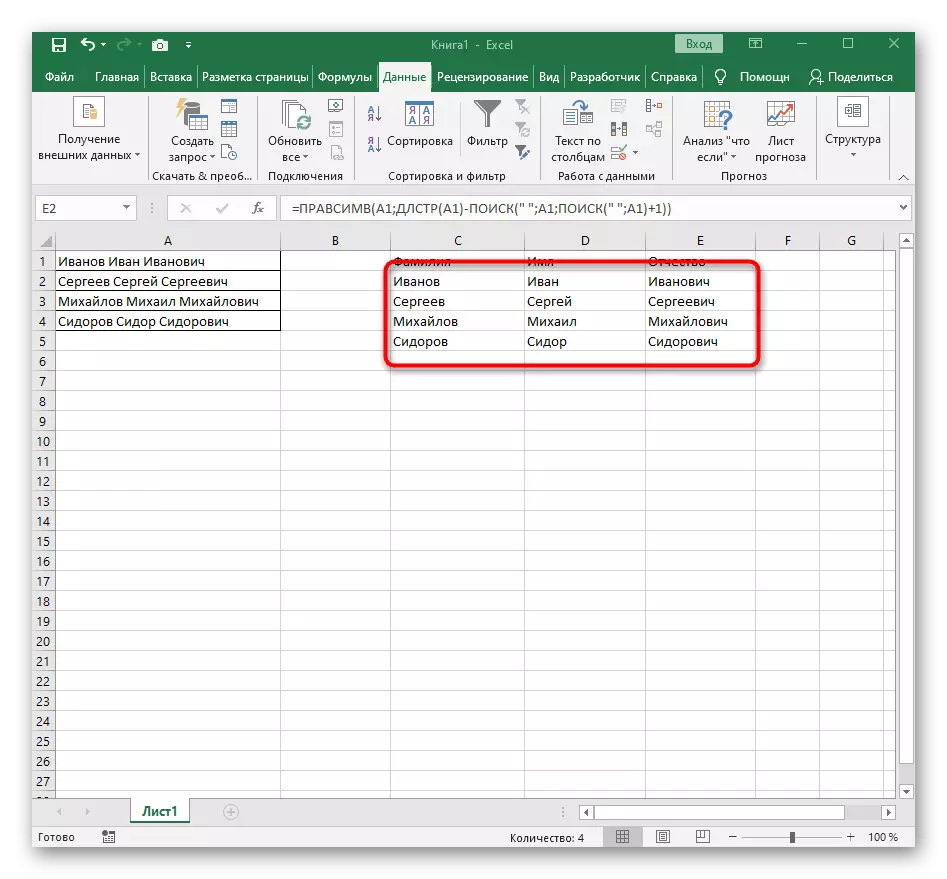
- Výsledkem je, že v dalším snímku obrazovky vidíte, že všechna tři slova jsou oddělena správně a jsou ve sloupcích. Za tímto účelem bylo nutné použít různé formy vzorců a pomocných funkcí, ale umožňuje dynamicky rozšiřovat tabulku a nebojte se, že pokaždé, když budete mít text znovu sdílet. Pokud je to nutné, jednoduše rozšířit vzorec posunutím dolů tak, aby byly automaticky ovlivněny následující buňky.